fr.wedoany.com Rapport : Les chercheurs d'Alibaba ont développé un framework nommé SkillWeaver pour résoudre le problème du routage des outils par les agents IA dans les tâches multi-étapes. Ce framework réduit la consommation de tokens de plus de 99 % grâce à une méthode de routage par combinaison de compétences.
Lorsque les systèmes d'IA d'entreprise sont étendus, les agents doivent traiter un grand nombre d'outils et de compétences. Les méthodes existantes de sélection de compétences uniques peinent à répondre aux demandes métier nécessitant plusieurs étapes, comme « télécharger un jeu de données, le transformer et créer un rapport visuel ». L'équipe de recherche a défini ce type de problème comme un « routage par combinaison de compétences », exigeant que l'agent détermine simultanément comment décomposer la tâche, comment mapper les sous-tâches aux compétences et comment les combiner en un plan exécutable.
SkillWeaver réalise ce processus en trois phases : décomposition, récupération et combinaison. La phase de décomposition utilise un grand modèle de langage pour diviser la requête utilisateur en une série de sous-tâches ; la phase de récupération utilise un modèle d'embedding pour extraire une liste restreinte d'outils candidats pour chaque sous-tâche à partir de la bibliothèque de compétences ; la phase de combinaison évalue la compatibilité des outils candidats et crée un plan d'exécution sous forme de graphe orienté acyclique. L'équipe de recherche a également introduit la technique de décomposition itérative sensible aux compétences (Iterative Skill-Aware Decomposition, SAD), qui permet au grand modèle de langage de réécrire la décomposition en fonction des informations de compétences récupérées lors d'une première itération, via une boucle de rétroaction, afin d'aligner la granularité avec la bibliothèque d'outils.
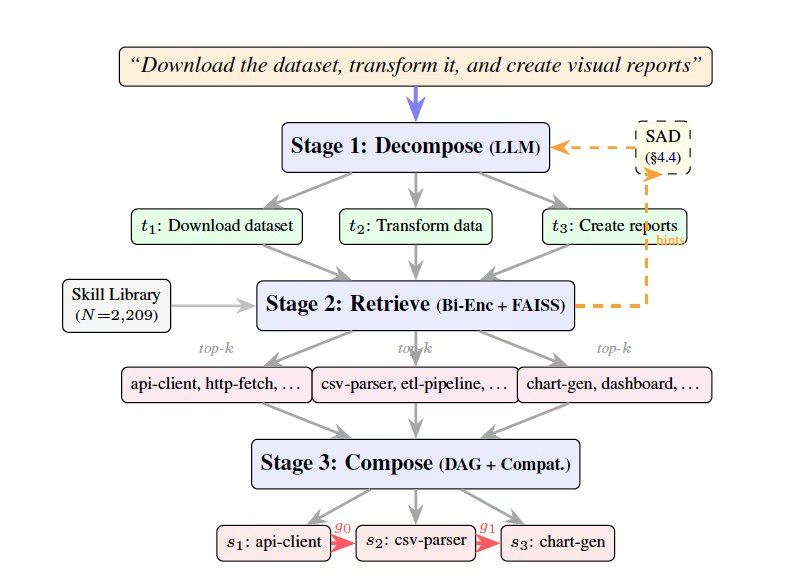
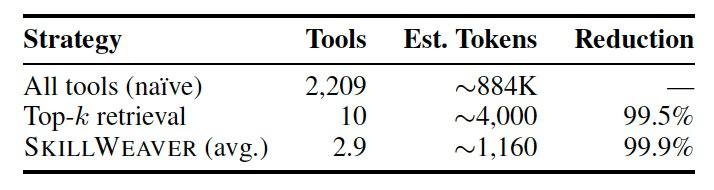
Pour évaluer les performances, les chercheurs ont créé un benchmark CompSkillBench contenant 300 requêtes multi-étapes, utilisant une bibliothèque de 2 209 compétences provenant de l'écosystème MCP public, couvrant 24 catégories fonctionnelles telles que l'infrastructure cloud, la finance et les bases de données. Le moteur central utilise le modèle Qwen2.5-7B-Instruct pour la décomposition des tâches, et le récupérateur de recherche sémantique MiniLM pour trouver les outils. Les expériences montrent que, dans un réglage normal sans SAD, la précision de décomposition du modèle 7B est de 51,0 %, et passe à 67,7 % après activation de la boucle de rétroaction SAD, tandis que le modèle plus grand Qwen-Max atteint 92 %. Sur les tâches difficiles nécessitant quatre à cinq compétences, SAD améliore la précision de 50 %. Comparée à la méthode LLM-Direct qui expose tous les outils au modèle, la récupération et le reroutage de SkillWeaver améliorent considérablement la précision et réduisent la consommation de fenêtre de contexte par requête d'environ 884 000 tokens à environ 1 160 tokens, soit une réduction de 99,9 %.
L'équipe de recherche souligne que ce framework est construit à partir de composants open source prêts à l'emploi, notamment le modèle d'embedding all-MiniLM-L6-v2 et l'index FAISS. L'embedding et l'indexation des 2 209 compétences ne prennent que 15 secondes. Les développeurs peuvent l'implémenter eux-mêmes à l'aide de bibliothèques d'orchestration telles que LangChain ou LlamaIndex. Actuellement, la phase d'exécution de SkillWeaver manque encore de capacité de récupération d'erreurs : en cas d'échec d'un appel API à la deuxième étape, la chaîne est interrompue. L'équipe recommande que, pour un déploiement en production, les développeurs construisent eux-mêmes des mécanismes de repli et de réessai.