

fr.wedoany.com Rapport : Le 2 juillet, le projet open source d’apprentissage par renforcement AReaL a publié sa version 2.0, visant à établir un lien entre l’entraînement des modèles de base et les applications modernes d’agents intelligents, afin de fournir un support efficace d’apprentissage par renforcement pour les scénarios d’agents.
AReaL 2.0 est conçu pour les agents déjà déployés dans des environnements métiers réels, en leur offrant une infrastructure système leur permettant d’apprendre en continu pendant leur utilisation. Cette version permet d’enregistrer et d’organiser les interactions générées par les agents lors de l’exécution de tâches réelles, puis de les intégrer dans le processus d’entraînement ultérieur pour optimiser en continu le modèle sous-jacent, rendant ainsi les agents plus performants à mesure qu’ils sont utilisés, dans un cadre sûr et contrôlé.
Actuellement, les agents entrent dans des environnements de production réels pour accomplir des tâches complexes telles que l’écriture de code, la recherche d’informations et l’utilisation d’outils. Cependant, bien qu’ils travaillent quotidiennement, ils peinent à tirer un véritable apprentissage de leur activité. Dans un contexte métier réel, les agents génèrent une grande quantité d’expériences précieuses, comme l’état d’achèvement des tâches, les causes d’échec des appels d’outils, la satisfaction des utilisateurs et les orientations décisionnelles. Ces informations sont souvent conservées uniquement sous forme de journaux, ce qui rend difficile leur transformation stable et sécurisée en une amélioration future des capacités.
AReaL 2.0 vise à résoudre le problème de la croissance continue des agents après leur déploiement. Les développeurs n’ont pas besoin de recréer un agent : il suffit de faire passer les requêtes que l’agent envoie normalement au grand modèle via l’entrée d’inférence unifiée d’AReaL 2.0 pour intégrer le processus d’apprentissage par renforcement en ligne.
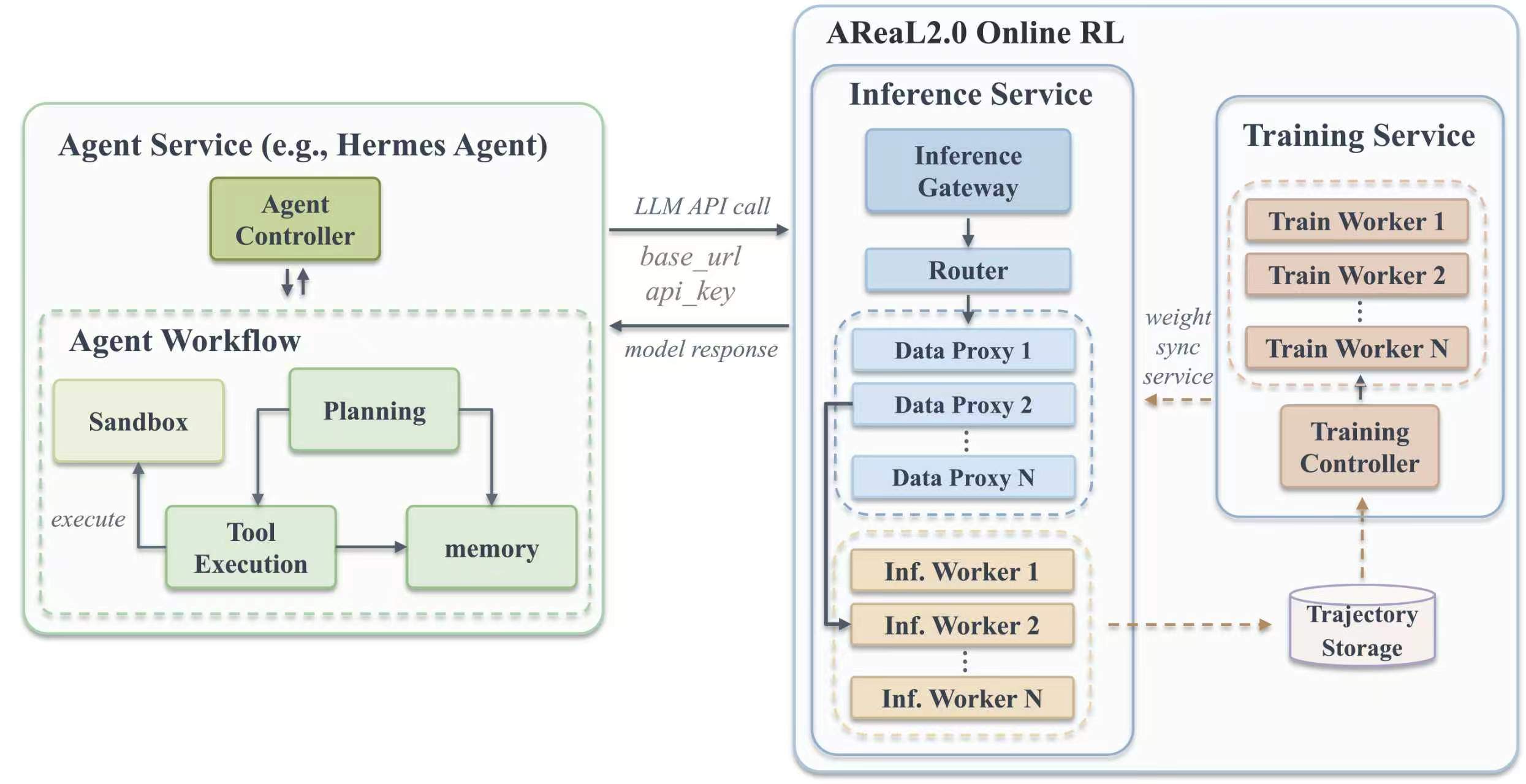
Prenons l’exemple d’Hermes Agent : Hermes reçoit normalement des tâches, planifie des étapes et appelle des modèles. AReaL 2.0 enregistre en arrière-plan les interactions clés lors de l’exécution des tâches et, combiné aux retours ou signaux de récompense après la tâche, utilise ces trajectoires réelles pour l’entraînement ultérieur. Les développeurs peuvent remplacer Hermes par leur propre agent et environnement de tâches pour construire de la même manière un processus d’apprentissage par renforcement en ligne pour l’agent. Cela signifie que l’amélioration des capacités de l’agent ne dépend plus uniquement de données artificielles, d’un entraînement hors ligne et d’un redéploiement : les dialogues multi-tours, les appels d’outils, les résultats d’exécution et les signaux de retour issus de tâches réelles peuvent tous devenir des matériaux d’apprentissage pour le modèle.
Ce point est particulièrement important dans les scénarios d’entreprise. Les agents dans les flux de travail d’entreprise sont confrontés à des tâches réelles, complexes et en constante évolution, notamment les mises à jour de bases de code, les ajustements de processus métier, les changements de besoins utilisateurs et les modifications d’outils et de systèmes. Si les capacités de l’agent restent essentiellement fixes après le déploiement, il lui sera difficile de s’adapter à long terme à l’environnement réel. AReaL 2.0 vise à combler le chaînon manquant entre « savoir utiliser des outils » et « apprendre de leur utilisation ».
Par ailleurs, l’apprentissage continu dans un contexte métier réel ne peut pas se résumer à « collecter des données puis réentraîner ». Les agents peuvent avoir accès à du code, des informations clients, des bases de connaissances d’entreprise et des systèmes internes. Par conséquent, la chaîne d’entraînement doit prendre en compte des exigences telles que le contrôle des accès, la désensibilisation des données, l’isolement et l’audit. AReaL 2.0 introduit dans sa conception système un mécanisme de délégation de données orienté vers les trajectoires d’agents, permettant de gérer et d’utiliser les données de tâches réelles de manière plus sûre et contrôlée lorsqu’elles entrent dans le processus d’entraînement.
Dans son rapport technique, l’équipe AReaL souligne que le goulot d’étranglement clé pour les agents auto-évolutifs ne réside pas seulement dans le modèle lui-même ou l’algorithme d’apprentissage par renforcement, mais surtout dans l’absence d’une infrastructure d’apprentissage par renforcement en ligne capable de servir des agents réels. AReaL 2.0 a procédé à une mise à niveau architecturale pour les applications d’agents de nouvelle génération, reliant les services d’agents, les trajectoires de tâches réelles, la gouvernance des données et l’entraînement par renforcement en ligne, offrant ainsi une base technique concrète permettant aux agents de continuer à apprendre après leur déploiement.
Le projet AReaL a été lancé en 2024 par des équipes d’Ant Group, de l’Université Tsinghua et de l’Université des sciences et technologies de Hong Kong. En mai 2026, AReaL est passé de l’incubation d’Ant InclusionAI à une communauté open source indépendante et a rejoint le projet PyTorch Foundation Ecosystem, s’intégrant ainsi à l’écosystème d’infrastructure d’apprentissage par renforcement dominant. Avec le développement indépendant de la communauté, AReaL continue de bénéficier de la participation et du soutien de partenaires industriels et de l’écosystème open source, notamment l’équipe Huawei Cloud et MindLab. À l’avenir, AReaL se concentrera sur l’apprentissage par renforcement en ligne, l’évaluation automatisée et l’entraînement d’agents multimodaux, et travaillera avec la communauté pour promouvoir le développement de l’écosystème des agents auto-évolutifs. Actuellement, le rapport technique et le code d’AReaL 2.0 sont disponibles en open source.










