

Des chercheurs de l’Institut génomique de Singapour (GIS) de l’Agence pour la science, la technologie et la recherche (A*STAR) ont développé une nouvelle méthode de séquençage ADN permettant de lire avec précision les séquences contenant des bases non standard. Cette avancée, qui combine séquençage par nanopores et intelligence artificielle, ouvre de nouvelles voies à la recherche génomique.
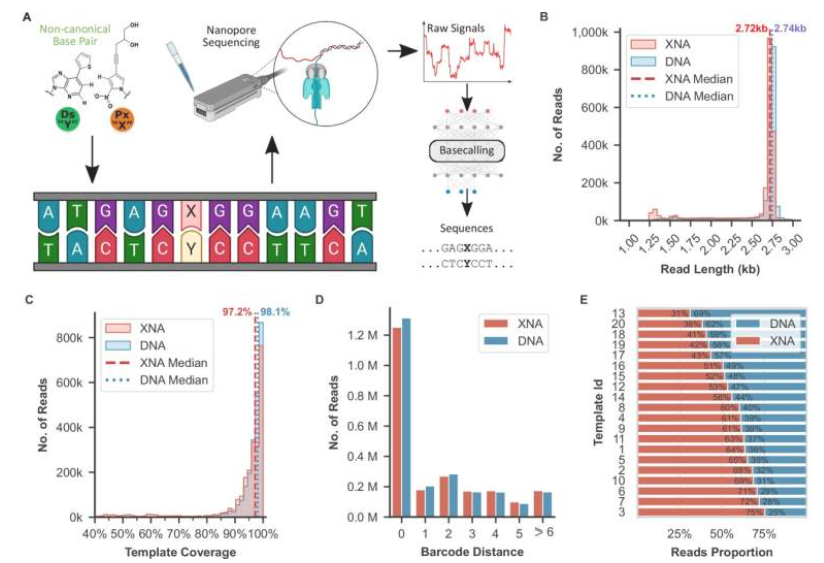
L’ADN est normalement constitué des quatre bases canoniques A, T, C et G, mais les bases non canoniques présentes dans la nature ou créées en laboratoire offrent un potentiel d’extension du code génétique. Les séquenceurs classiques ne reconnaissent que les bases standard, ce qui limite le développement de nouveaux médicaments et applications biotechnologiques. Le Dr Mauricio Rivas Pérez (A*STAR GIS) explique : « Notre capacité à lire rapidement un texte dépend largement de notre familiarité avec le vocabulaire utilisé. De la même façon, pour qu’un modèle d’intelligence artificielle puisse ‘lire’ rapidement l’ADN, il doit avoir été entraîné sur un grand nombre d’exemples de chaque type de base. »
L’équipe a créé une bibliothèque d’ADN artificiel contenant toutes les combinaisons de bases canoniques et non canoniques, puis a enregistré par séquençage nanopore le signal électrique propre à chaque base. Face au bruit des données et à la rareté de certains échantillons, la méthode utilise un algorithme d’IA adaptatif qui s’améliore par apprentissage continu et augmentation de données. Les résultats ont été publiés dans Nature Communications.
L’atout majeur de cette technique est sa capacité à reconnaître directement les nouvelles « lettres » génétiques, brisant ainsi les limitations des approches traditionnelles. Le Dr Niranjan Nagarajan, directeur adjoint IA et calcul à A*STAR GIS, déclare : « Pouvoir identifier à grande échelle ces nouvelles bases nous offre un vocabulaire beaucoup plus riche pour écrire et lire l’information biologique. C’est comme apprendre à reconnaître de nouvelles lettres : cela nous permet de comprendre davantage de mots et de sens dans le langage de la vie. »