
fr.wedoany.com Rapport : Une équipe de chercheurs a développé un cadre d'entraînement pour réseaux de neurones quantiques, réduisant le coût de calcul des gradients pendant l'entraînement – l'un des principaux obstacles de longue date dans le domaine de l'apprentissage automatique quantique.
Selon une étude publiée sur le serveur de prépublication arXiv, cette méthode réduit le nombre d'évaluations de circuits nécessaires par étape d'optimisation, passant d'une croissance quadratique avec le nombre de qubits à une croissance seulement logarithmique. Les chercheurs indiquent que cette amélioration permet un entraînement direct basé sur les gradients sur l'ordinateur quantique à ions piégés Forte Enterprise d'IonQ, et leur a permis d'appliquer cette méthode à une tâche d'imputation de données cliniquement pertinente.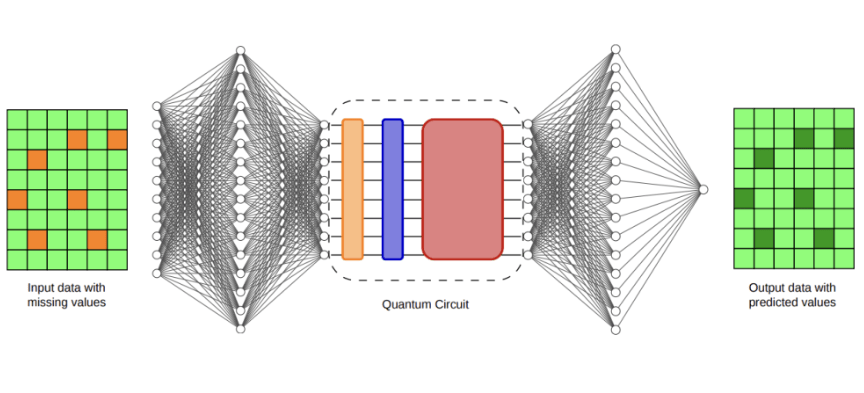
Selon l'équipe, ces travaux résolvent un défi persistant dans l'apprentissage automatique quantique. L'équipe comprend des scientifiques d'IonQ, de l'Université Paris Cité, du Centre national de la recherche scientifique (CNRS), de QC Ware et de Quantum Signals. Les réseaux de neurones quantiques (QNN) sont des circuits quantiques dotés de paramètres ajustables, entraînés de manière similaire aux réseaux de neurones classiques. Théoriquement, ils pourraient offrir des avantages dans certaines tâches d'apprentissage, mais leur entraînement sur du matériel quantique réel s'est avéré difficile, car le calcul des gradients nécessite généralement l'exécution répétée d'un grand nombre de circuits quantiques. Les chercheurs rapportent que ce surcoût est l'une des principales raisons pour lesquelles de nombreuses démonstrations d'apprentissage automatique quantique restent limitées à des simulations ou à des expériences sur du matériel à très petite échelle.
Ce cadre combine trois composants conçus de manière synergique, incluant une architecture de circuit spécialisée, une stratégie d'entraînement couche par couche et une technique de calcul parallèle des gradients.
La méthode traditionnelle de décalage de paramètres, largement utilisée pour entraîner les circuits quantiques, nécessite des évaluations de circuit séparées pour chaque paramètre individuel. À mesure que la taille du modèle augmente, le nombre d'évaluations nécessaires croît rapidement. Le nouveau cadre évite ce goulot d'étranglement grâce à trois choix de conception. Le premier est une architecture de circuit appelée réseau papillon (Butterfly network), inspirée de la structure de la transformée de Fourier rapide, qui organise les opérations quantiques selon un motif spécifique permettant à l'information de se propager dans l'ensemble du système tout en maintenant le circuit relativement peu profond. Selon l'étude, cette conception réduit considérablement le nombre de paramètres entraînables nécessaires à mesure que la taille du système augmente. La deuxième est une stratégie d'entraînement couche par couche, qui, au lieu d'entraîner simultanément chaque paramètre du réseau de neurones quantique, entraîne d'abord des blocs de circuits plus petits, puis ajoute progressivement de nouvelles couches, les couches précédemment entraînées étant gelées lors de l'optimisation des nouvelles couches. La troisième est une version parallélisée de la règle de décalage de paramètres. Étant donné que les portes à l'intérieur de chaque couche papillon agissent sur différentes paires de qubits et commutent entre elles, les chercheurs peuvent utiliser un nombre constant d'exécutions de circuits pour calculer le gradient de l'ensemble de la couche, plutôt que d'évaluer chaque paramètre individuellement. Ces techniques réduisent considérablement le nombre d'évaluations de circuits quantiques nécessaires pendant l'entraînement. Les chercheurs rapportent un avantage de passage à l'échelle à travers un exemple : l'application de la méthode traditionnelle de décalage de paramètres à un circuit papillon de 128 qubits nécessite 1792 évaluations de circuits pour calculer le gradient, tandis que leur méthode n'en nécessite que 28.
Pour évaluer ce cadre, les chercheurs ont choisi l'imputation de données cliniques, un problème qui dépasse les benchmarks traditionnels de l'informatique quantique. L'imputation de données consiste à combler les entrées manquantes dans un ensemble de données. Dans les dossiers médicaux, les informations manquantes sont courantes en raison d'horaires de mesure incohérents, de pannes de capteurs ou de collectes de données incomplètes. Une imputation précise peut avoir un impact significatif sur les modèles prédictifs en aval utilisés dans l'analyse médicale. L'équipe a utilisé l'ensemble de données MIMIC-III, une collection largement étudiée de dossiers d'unités de soins intensifs anonymisés. Ils ont introduit des valeurs manquantes dans l'ensemble de données, puis ont comparé diverses méthodes pour reconstruire les informations manquantes. Les références incluent des techniques statistiques courantes telles que l'imputation par la moyenne et le remplissage par zéro, ainsi que des méthodes plus complexes comme l'imputation par les k plus proches voisins, l'imputation multiple par équations chaînées (MICE), MissForest et le modèle Deep MICE basé sur un réseau de neurones. Les chercheurs ont évalué indirectement la qualité de l'imputation en prédisant la survie des patients, mesurée à l'aide de l'aire sous la courbe ROC (AUC). Parmi les méthodes classiques, Deep MICE a produit la performance moyenne la plus élevée, avec une AUC de 0,7176. Le modèle hybride quantique-classique entraîné sur 16 qubits a atteint une AUC de 0,7147, tandis que le modèle hybride sur 32 qubits a atteint une AUC de 0,7132, les deux étant à moins de quelques millièmes du résultat classique de tête. Bien que les modèles quantiques n'aient pas surpassé la meilleure baseline classique, ils présentaient une plage de performances étroite et une faible variabilité entre les exécutions. Les chercheurs suggèrent que cette stabilité pourrait indiquer un biais inductif bénéfique apporté par l'architecture papillon structurée et le protocole d'entraînement.
Cette étude fournit une démonstration importante d'entraînement direct sur un ordinateur quantique commercial. Les chercheurs ont entraîné la dernière couche d'un réseau de neurones quantique papillon de 16 qubits sur le système à ions piégés Forte Enterprise d'IonQ. Les premières étapes du modèle ont été entraînées en simulation, puis intégrées au réseau entraîné sur le matériel. Ils ont comparé trois scénarios : simulation idéale, simulation avec bruit et exécution directe sur le matériel. Selon les résultats, les différences de performance entre les trois méthodes d'entraînement n'étaient pas statistiquement significatives. Le modèle entraîné sur le matériel a obtenu des résultats comparables à ceux des modèles simulés, tout en maintenant des performances prédictives similaires. Les chercheurs rapportent que cela démontre que le cadre d'entraînement à mise à l'échelle logarithmique est suffisamment robuste pour fonctionner avec les niveaux de bruit actuels du matériel. Cette découverte est importante car de nombreuses démonstrations antérieures d'apprentissage automatique quantique dépendaient fortement de simulations plutôt que de processeurs quantiques réels, le bruit matériel et les longs temps d'entraînement rendant souvent l'optimisation directe impraticable. L'architecture à ions piégés utilisée par IonQ a pu être bénéfique, car ce système offre une connectivité complète entre les qubits, permettant la mise en œuvre de circuits papillon sans frais de compilation importants.
L'étude a également exploré des tailles de système plus grandes. Comme l'entraînement direct sur 32 qubits reste coûteux en calcul, les chercheurs ont utilisé des simulations de réseaux de tenseurs d'états de produits matriciels pour entraîner des couches quantiques plus grandes, l'inférence étant exécutée sur le matériel IonQ. La performance du modèle hybride résultant sur 32 qubits était comparable à celle d'un réseau de neurones classique avec une largeur de couche cachée équivalente. Les chercheurs interprètent cela comme une preuve que les circuits quantiques plus grands produits par le cadre couche par couche restent compatibles avec le matériel réel et peuvent être exécutés sans dégradation mesurable.
Ce travail comporte plusieurs limitations importantes. L'étude s'est concentrée sur une tâche d'imputation contrôlée de validation de concept, et non sur un flux de travail médical à l'échelle de la production. Une seule colonne de caractéristiques a été imputée à l'aide du modèle quantique, les autres valeurs manquantes étant traitées par des méthodes classiques. Le modèle de données manquantes a également été généré en utilisant un modèle de données manquantes complètement aléatoires, alors que les données cliniques réelles présentent généralement des modèles de données manquantes plus complexes. Enfin, le modèle hybride a égalé, mais non surpassé, la meilleure baseline classique. Les résultats démontrent la faisabilité et la compétitivité, mais non un avantage quantique clair. Les chercheurs notent également que des systèmes plus grands pourraient être nécessaires avant qu'un avantage potentiel en performance ne devienne évident. Sur la base de comparaisons avec des architectures de réseaux de neurones classiques, ils estiment qu'environ 128 qubits seraient nécessaires pour égaler la capacité de représentation du meilleur modèle classique utilisé dans l'étude. Néanmoins, les chercheurs estiment que l'importance de ce cadre ne réside pas dans les chiffres de performance actuels, mais dans la réalisation d'un entraînement scalable sur le matériel.
L'équipe de recherche comprend Natansh Mathur de l'Institut de recherche en informatique fondamentale (IRIF), un laboratoire de recherche conjoint du CNRS et de l'Université Paris Cité, ainsi que QC Ware en France. Les co-auteurs Panagiotis Kl. Barkoutsos, Masako Yamada et Martin Roetteler sont affiliés à IonQ. La recherche inclut également Iordanis Kerenidis, affilié à l'IRIF, au CNRS, à l'Université Paris Cité et à Quantum Signals.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com









