fr.wedoany.com Rapport : Tashi Zhihang, en collaboration avec l’Université nationale de Singapour, l’Université Jiao Tong de Shanghai, l’Institut d’automatique de l’Académie des sciences de Chine et l’Université de Fudan, a publié sur une plateforme de prépublication l’article « TacForeSight: Force-Guided Tactile World Model for Contact-Rich Manipulation ». Cette recherche propose un modèle tactile du monde conditionné par la force, intégrant pour la première fois les signaux de force au poignet comme informations précurseurs des futurs états tactiles, afin de prédire l’évolution des contacts à court terme et d’intégrer ces prédictions dans le processus de génération des actions du robot.
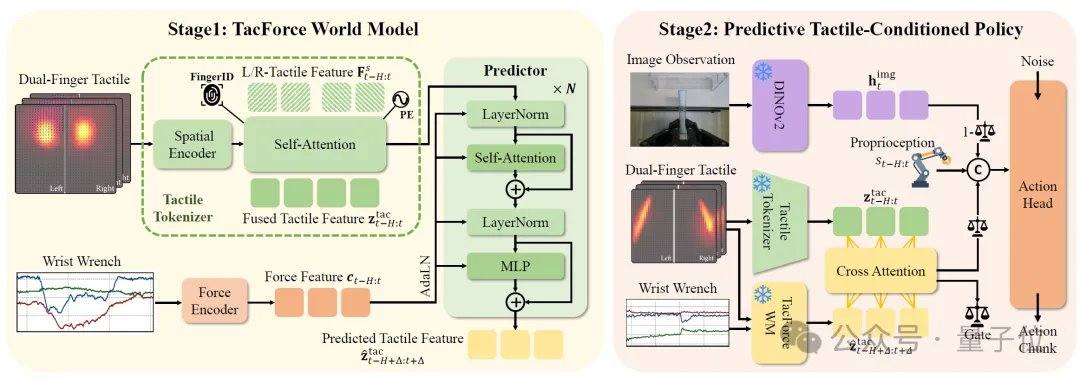
Dans les opérations à contacts intensifs, telles que l’essuyage, l’insertion ou le serrage, l’état de contact évolue continuellement dans le temps, et les variations de force ou de position peuvent facilement entraîner des échecs. Les méthodes existantes reposent souvent sur des signaux de rétroaction pour des ajustements a posteriori. L’idée centrale de TacForeSight est d’identifier la relation temporelle entre la force et le toucher : la force au poignet fournit un signal précurseur de la tendance globale des efforts, tandis que le toucher reflète les détails locaux du contact. Sur cette base, l’équipe a développé le module central TacForceWM, qui encode le champ tactile à deux doigts en variables latentes tactiles compactes, et utilise les signaux de force ou de couple au poignet à haute fréquence pour prédire l’évolution tactile à court terme. Cela réduit la charge de calcul liée à la génération d’images tactiles haute dimension et permet d’utiliser les prédictions pour générer des stratégies d’action légères.

Après avoir prédit l’état tactile futur, le système utilise une politique conditionnée par le toucher prédictif (Predictive Tactile-Conditioned Policy) avec un mécanisme d’attention croisée (Cross-Attention) pour modéliser explicitement la relation entre le contact actuel et les tendances futures, permettant ainsi à la génération d’actions de prendre en compte à la fois le contact présent et les changements à venir. Parallèlement, un mécanisme de contrôle adaptatif piloté par le toucher ajuste dynamiquement les poids de la vision et du toucher en fonction de la phase de la tâche : il privilégie le contrôle tactile pendant les phases de contact intense et s’appuie sur les informations visuelles lors des phases sans contact.
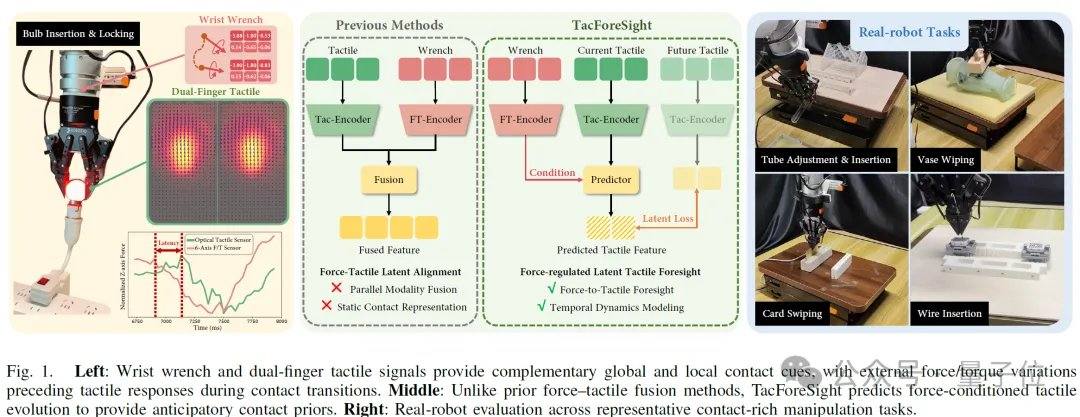
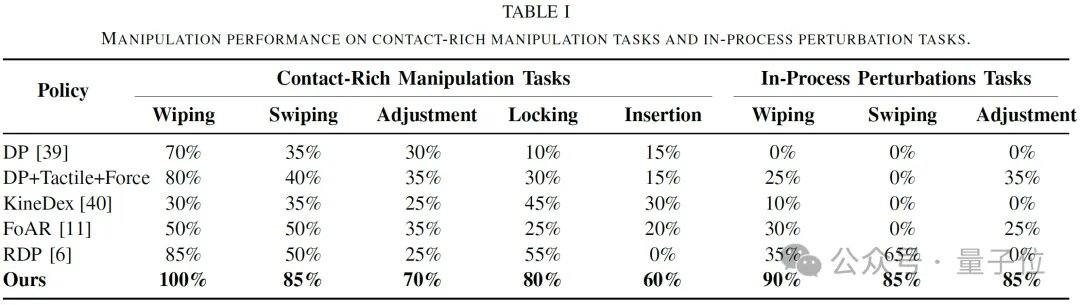
Les expériences ont été menées sur une plateforme robotique réelle, comprenant un bras robotique, une pince, une caméra, un capteur de force ou de couple à six axes et un capteur tactile à deux doigts. Cinq tâches typiques à contacts intensifs ont été couvertes : essuyage d’un vase, glissement d’une carte, insertion d’un tube, serrage d’une ampoule et insertion d’un faisceau de câbles flexibles. Les résultats montrent un taux de réussite moyen proche de 80 % sur les tâches standard, surpassant les modèles purement visuels, les simples fusions vision-toucher-force, ainsi que les méthodes de référence telles que KineDex, FoAR et RDP. Dans des scénarios de perturbations dynamiques (hauteur, angle, posture), les taux de réussite atteignent respectivement 90 %, 85 % et 85 %, avec une moyenne de 86,7 %. Le modèle prend en charge une inférence en temps réel à 20 Hz, pouvant être intégré dans une boucle de contrôle robotique à haute fréquence.

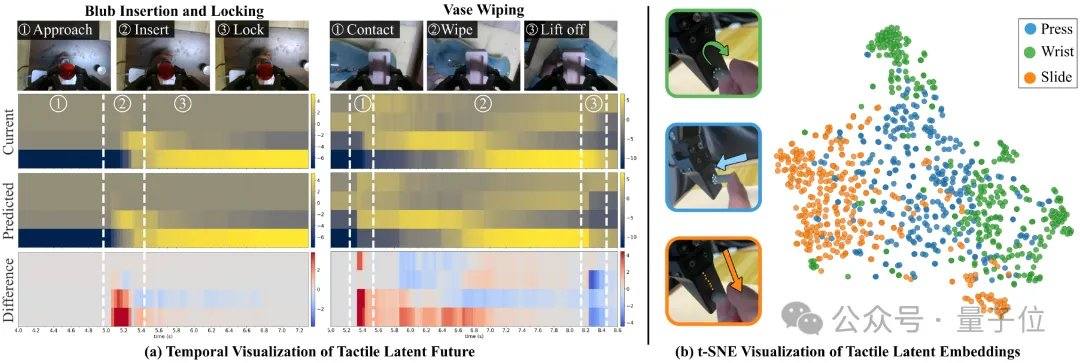
L’analyse de visualisation des variables latentes montre que, dans les tâches de serrage d’ampoule et d’essuyage de vase, les variables latentes tactiles prédites présentent des changements liés au contact environ 200 millisecondes plus tôt que les variables latentes tactiles actuelles. Sur des segments d’interaction force-toucher non vus (pression, torsion, glissement), les variables latentes extraites par l’encodeur tactile forment des clusters distincts dans la visualisation t-SNE, indiquant que le modèle est capable de discriminer les modes de contact. Il s’agit d’une nouvelle avancée de Tashi Zhihang dans le domaine des opérations de précision ; en mars dernier, la société avait déjà publié le cadre d’opération visuo-tactile OmniVTA et l’ensemble de données visuo-tactiles à grande échelle OmniViTac, aidant les robots à comprendre le contact par la vision et le toucher.