
fr.wedoany.com Rapport : La pile logicielle d'inférence de NVIDIA (NVIDIA) sur sa plateforme Blackwell a réduit le coût par token du modèle DeepSeek V4 jusqu'à un cinquième de sa valeur initiale en un mois. Alors que les entreprises passent des projets pilotes d'IA aux usines d'IA de production, les décisions en matière d'infrastructure sont passées de l'attention portée aux spécifications maximales des puces au coût par token, c'est-à-dire le nombre de tokens utiles produits par dollar et par watt d'énergie tout en respectant les objectifs de latence. La pile logicielle d'inférence de NVIDIA, co-conçue avec les GPU, CPU, réseaux et systèmes NVIDIA, et renforcée par un vaste écosystème open source, améliore continuellement les performances matérielles.
Les entreprises et fournisseurs d'inférence de premier plan commencent déjà à bénéficier de la valeur ajoutée de la pile logicielle d'inférence de NVIDIA sur Blackwell. Baseten utilise la bibliothèque open source NVIDIA TensorRT-LLM pour fournir le service DeepSeek V4 Pro sur les GPU Blackwell, adapté aux charges de travail d'inférence, de codage et de contexte long, avec une augmentation du débit de tokens par seconde allant jusqu'à 50 % grâce à des optimisations d'exécution propriétaires. Cognition utilise le framework d'inférence NVIDIA Dynamo pour gérer les GPU d'inférence, offrant à son équipe une voie toute tracée pour étendre les charges de travail d'apprentissage par renforcement sans avoir à construire l'infrastructure à partir de zéro. Deep Infra utilise la pile logicielle d'inférence de NVIDIA pour exécuter des modèles open source de pointe, y compris DeepSeek V4, sur Blackwell avec des performances élevées dès le premier jour. Together AI utilise NVIDIA TensorRT-LLM sur Blackwell pour aider Cursor à accélérer le passage de l'optimisation du modèle aux points de terminaison de production, afin de soutenir son expérience de codage en temps réel.
Contrairement aux charges de travail traditionnelles de pages web, de recherche et de logiciel en tant que service, qui sont relativement prévisibles, l'IA agentique est différente. Les agents peuvent raisonner, planifier, invoquer des outils, lancer des sous-agents spécialisés et gérer de grands volumes de contexte dans des flux de travail multi-tours, transformant une seule requête en un problème de calcul distribué pouvant impliquer des centaines de sous-agents, des milliers de tâches et plusieurs grands modèles de langage, s'exécutant sur des GPU, CPU, DPU et des systèmes de stockage. La pile logicielle détermine si cette complexité se traduit par une puissance de calcul gaspillée ou par un coût par token plus faible.
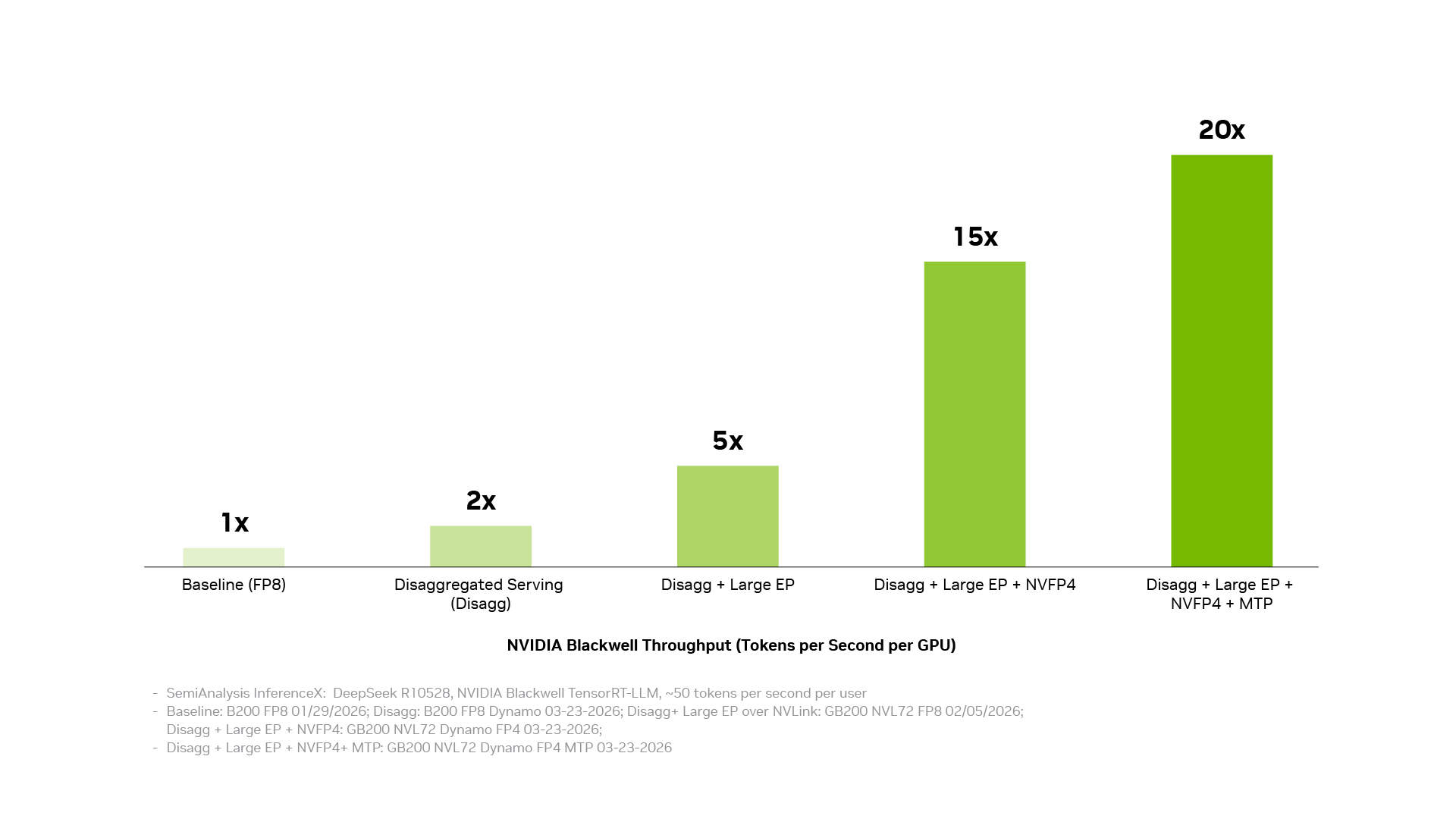
Un coût par token plus faible provient de la transformation d'optimisations individuelles en performances au niveau du système. La pile logicielle d'inférence de NVIDIA y parvient en connectant trois couches : la couche d'exploitation et de maintenance de production coordonne les services distribués, l'orchestration, la mise à l'échelle automatique et la gestion de la mémoire ; la couche d'accélération des applications exécute les modèles avec des performances élevées et offre aux développeurs un espace pour le réglage et la personnalisation ; la couche d'accès à l'infrastructure expose les capacités des GPU, réseaux, mémoire et systèmes NVIDIA. Lorsque ces couches fonctionnent ensemble en tant que système, les effets des optimisations individuelles se cumulent. Le découplage des services, le parallélisme expert à grande échelle basé sur la technologie d'interconnexion NVIDIA NVLink, la précision NVFP4 et la prédiction multi-tokens apportent chacun des gains significatifs ; combinés, ils peuvent augmenter le débit jusqu'à 20 fois.
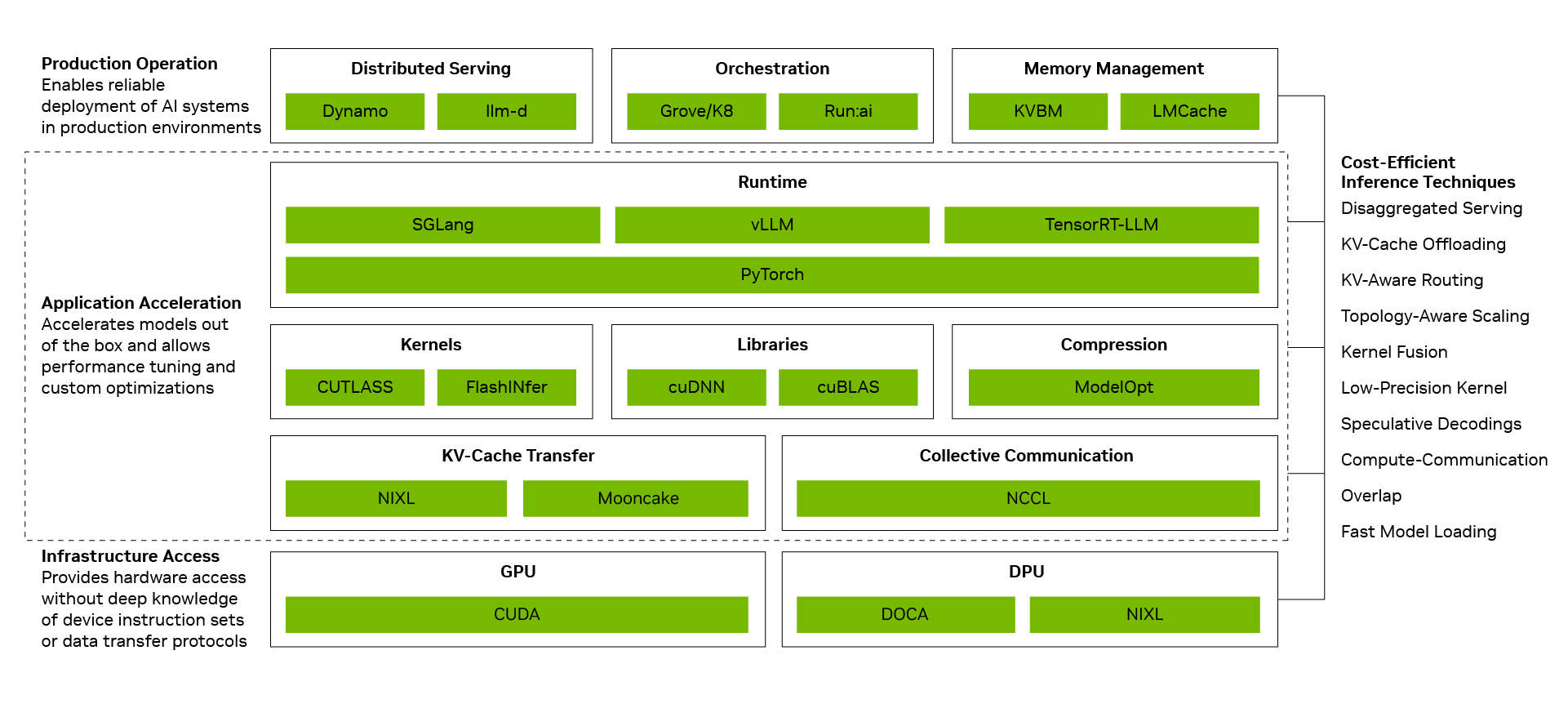
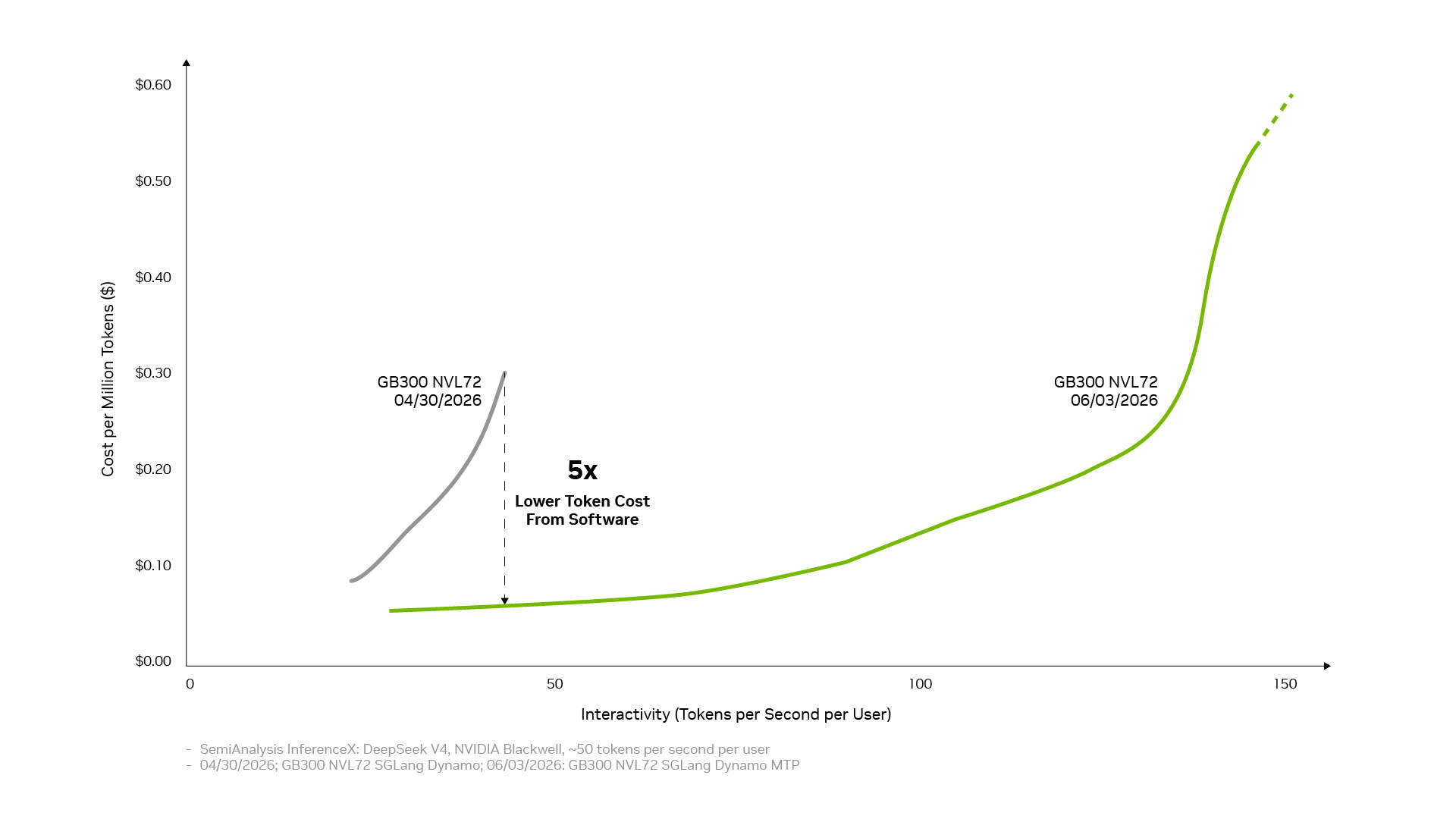
Cette même base de pile complète est également amplifiée par l'écosystème open source. De nombreux frameworks d'IA open source et projets d'inférence largement utilisés aujourd'hui sont construits nativement sur NVIDIA CUDA. PyTorch en est un exemple typique : lancé en 2016 avec un support natif de CUDA, il a co-évolué avec les architectures NVIDIA. Lorsque des technologies révolutionnaires comme le décodage spéculatif DFlash ou FastVideo arrivent sur PyTorch, elles peuvent immédiatement fonctionner sur NVIDIA. Lorsque des modèles ouverts de pointe comme DeepSeek V4 sont publiés, des frameworks d'inférence de premier plan comme vLLM et SGLang peuvent fournir des solutions de déploiement pour l'architecture NVIDIA Blackwell dès le premier jour. C'est pourquoi les performances de DeepSeek V4 sur Blackwell ont été multipliées par jusqu'à 5 en un mois grâce aux frameworks vLLM et SGLang, réduisant le coût par token à environ un cinquième de sa valeur initiale.
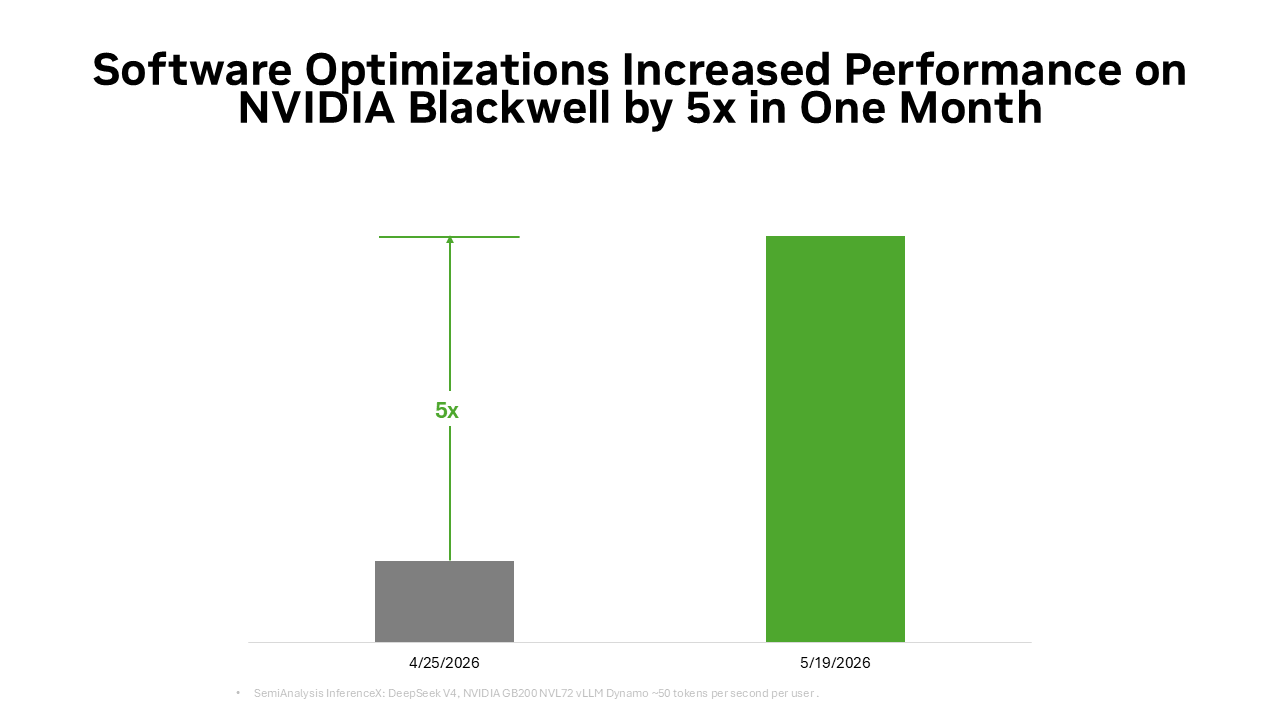
Voici le cercle vertueux de l'open source : de plus en plus de développeurs optimisent les chemins d'inférence basés sur CUDA, de plus en plus de déploiements en production alimentent l'écosystème, et chaque amélioration logicielle augmente la quantité de tokens produits tout en réduisant le coût par token.










