fr.wedoany.com Rapport : Meta a dévoilé les résultats de ses recherches sur l’interface cerveau-machine Brain2Qwerty v2. Cette étude utilise l’intelligence artificielle pour reconstituer le langage naturel à partir de l’activité cérébrale générée lorsque des sujets tapent du texte. L’objectif est de fournir un moyen de communication textuel non invasif aux personnes ayant perdu la capacité de parler ou d’agir en raison de lésions cérébrales, d’accidents vasculaires cérébraux ou de maladies neurologiques.

Contrairement aux interfaces cerveau-machine qui nécessitent l’implantation chirurgicale d’électrodes, le projet Brain2Qwerty v2 utilise un appareil de magnétoencéphalographie (MEG) pour enregistrer les faibles champs magnétiques produits par l’activité neuronale du cerveau des patients, afin d’obtenir des signaux. Ces signaux sont ensuite analysés par un modèle d’IA qui produit les informations.
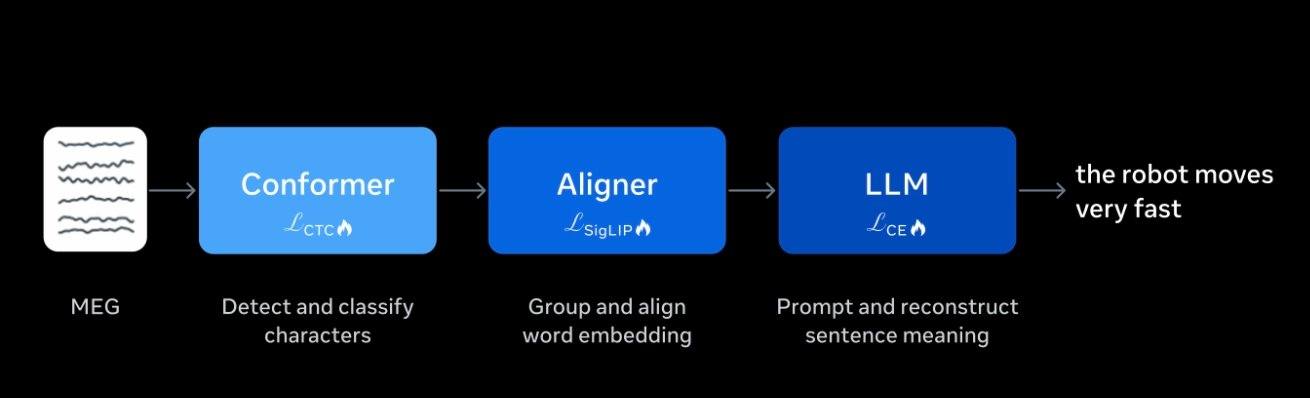
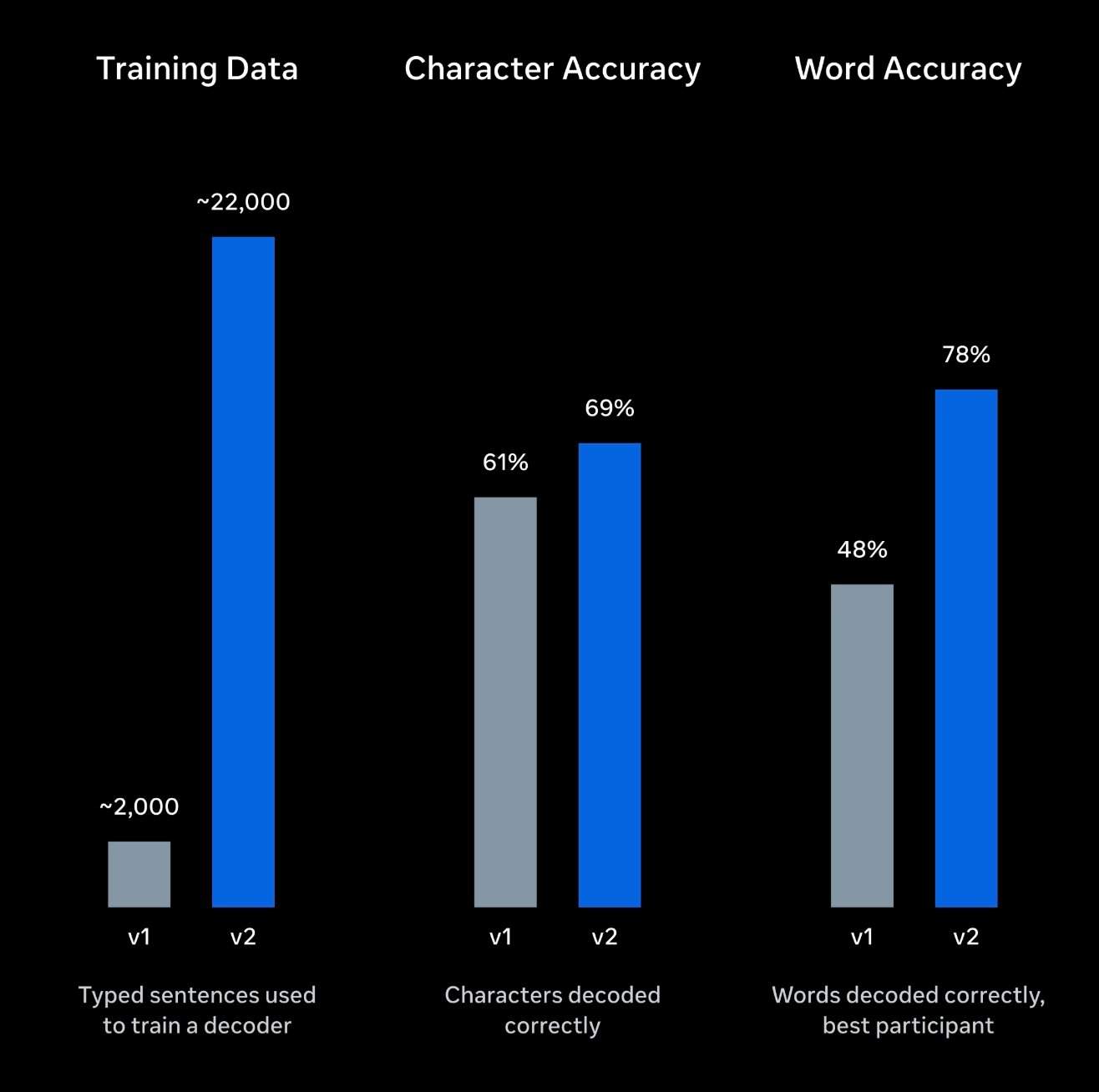
Ce modèle d’IA a été entraîné sur les données de neuf volontaires, comprenant 22 000 phrases et environ 10 heures d’enregistrement de l’activité cérébrale. Meta a procédé à un réglage fin spécifique du modèle, lui permettant d’utiliser les informations sémantiques contextuelles pour compléter et corriger les signaux cérébraux très bruités, générant ainsi des phrases plus cohérentes et naturelles.
Selon les résultats expérimentaux publiés par Meta, le taux de reconnaissance moyen actuel des mots de Brain2Qwerty v2 est d’environ 61 %, ce qui correspond à un taux d’erreur moyen sur les mots (WER) d’environ 39 %. Chez le sujet le plus performant, la précision a atteint jusqu’à 78 %, et dans plus de la moitié des phrases testées, il n’y avait pas plus d’une erreur par mot.
Cette technologie présente encore des limitations évidentes. Les expériences ont été menées dans un environnement hautement contrôlé, où les patients doivent utiliser un appareil MEG de laboratoire de grande taille pour produire avec précision les signaux magnétoencéphalographiques. En termes de coût de l’équipement, de volume et de scénarios d’utilisation quotidienne, il reste encore un écart important avant une application pratique.
Actuellement, Meta a ouvert les codes d’entraînement de Brain2Qwerty v1 et v2 sur GitHub. L’institution partenaire, le Basque Center on Cognition, Brain and Language, a également rendu public l’ensemble de données v1, tandis que l’ensemble de données v2 sera ouvert après l’acceptation officielle de l’article.