fr.wedoany.com Rapport : Dans un contexte où les modèles multimodaux passent de la démonstration au déploiement en production, les trois modèles Step 3.7 Flash, Qwen3.6-flash et MiniMax M3 ont été soumis à des tests réels dans des scénarios de développement et d’exploitation. Une évaluation comparative portant sur deux tâches — la reconnaissance de diagrammes de flux et l’extraction de données de factures — montre que la qualité de la compréhension visuelle et de la sortie structurée est relativement stable pour les trois modèles, mais qu’il existe des différences en termes de temps de réponse et de consommation de tokens.
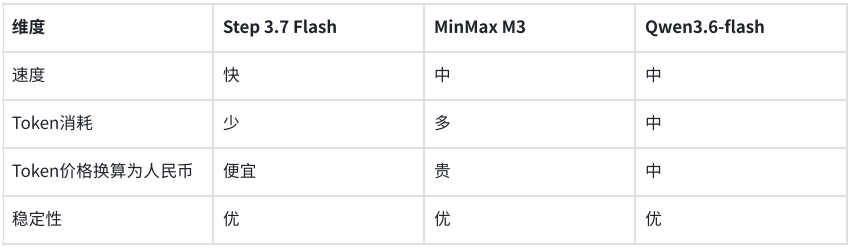
L’évaluation, menée selon trois dimensions — qualité, vitesse et coût —, a sélectionné deux types de scénarios industriels : d’une part, la restitution de la logique métier à partir d’un diagramme de flux système lors du développement d’un agent, et d’autre part, l’extraction structurée des informations d’une facture via un appel API dans un système métier. Les tests montrent qu’aucun des trois modèles n’a commis d’erreur grave de reconnaissance dans les deux tâches, et que la qualité des sorties est satisfaisante.
Dans le scénario de compréhension de diagramme de flux, le modèle devait extraire avec précision la logique métier en 10 étapes à partir d’un diagramme de flux d’authentification par connexion WeChat Mini Program. Step 3.7 Flash a correctement identifié les 10 étapes, chacune correspondant parfaitement au diagramme original. MiniMax M3 a également produit 10 étapes, avec une logique correcte. Qwen3.6-flash a fusionné les étapes 3 et 4, produisant 9 étapes, mais la logique globale était correcte. À qualité de sortie équivalente, Step 3.7 Flash a affiché le temps de réponse le plus rapide et la consommation de tokens la plus faible.
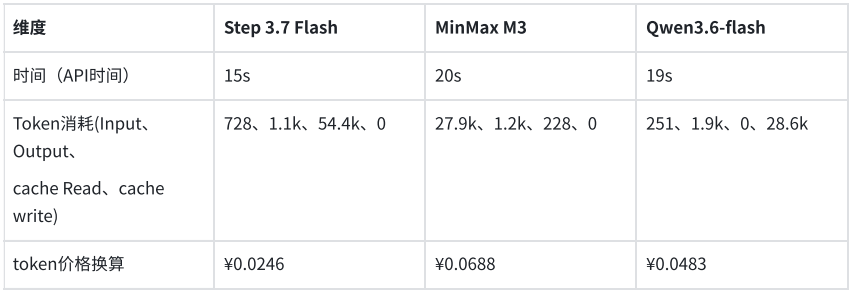
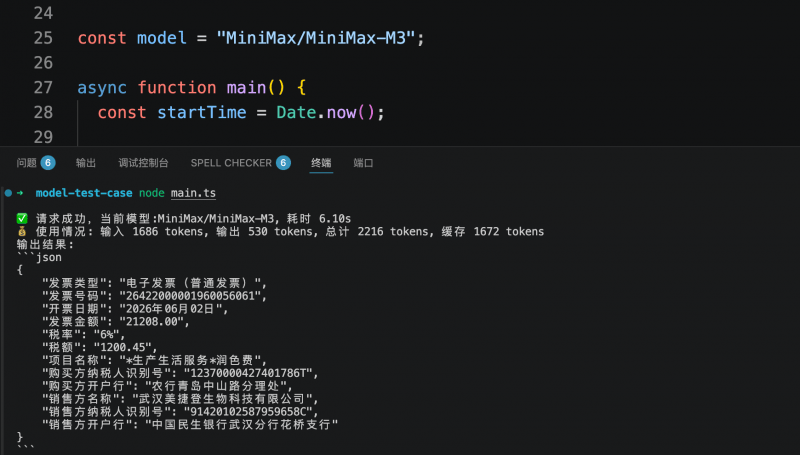
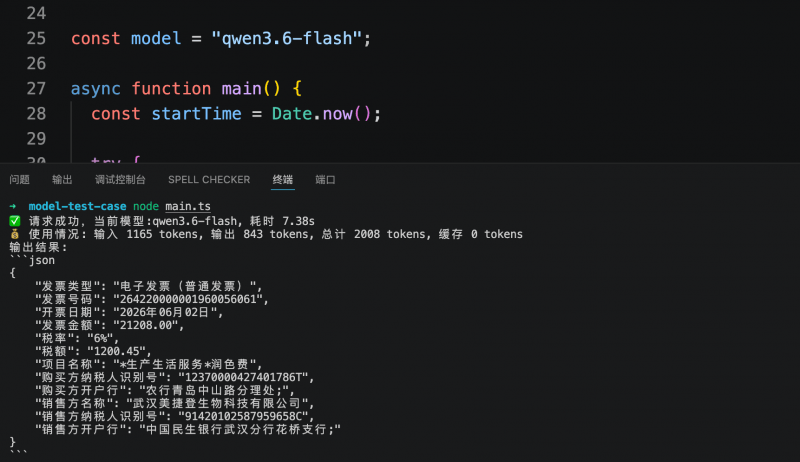
Dans un autre test orienté système métier, le modèle devait extraire les champs clés d’une facture électronique selon une structure JSON prédéfinie. Les trois modèles ont correctement identifié et structuré les informations requises. Step 3.7 Flash a accompli cette tâche en 5,6 secondes, consommant 1 409 tokens ; MiniMax M3 a pris 6,1 secondes, consommant 2 216 tokens ; Qwen3.6-flash a pris 7,38 secondes, consommant 2 008 tokens. Le coût d’extraction structurée par facture était inférieur à 0,01 yuan.
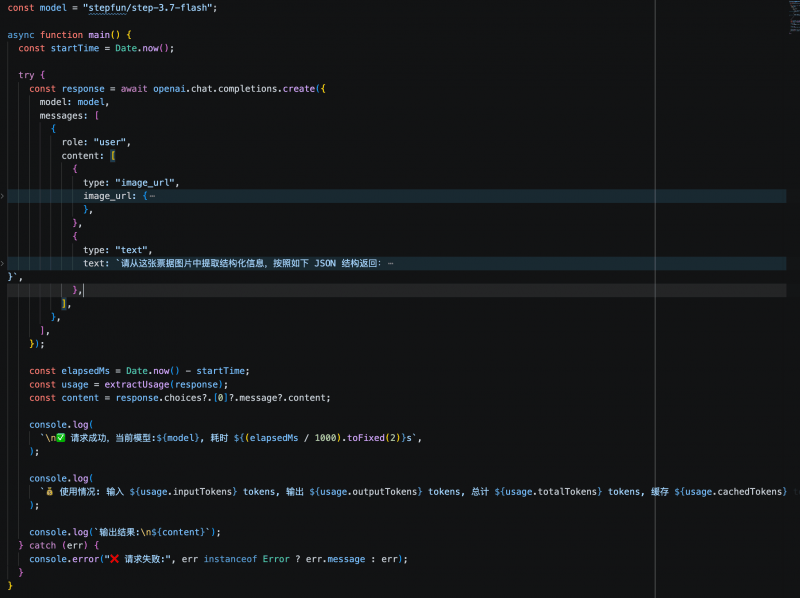

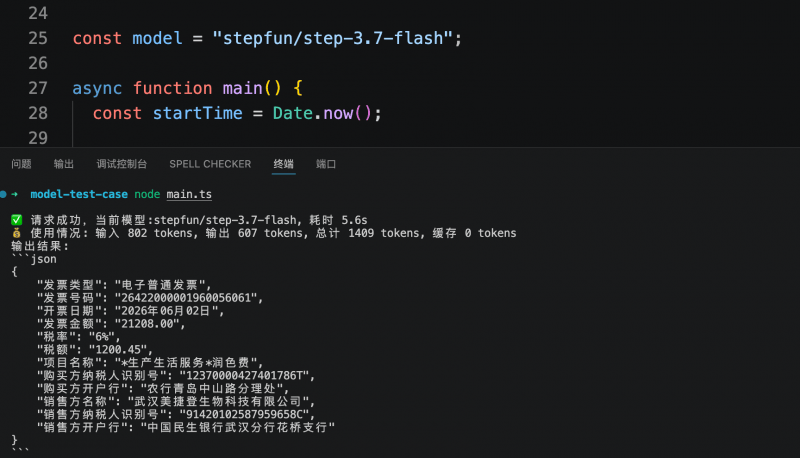
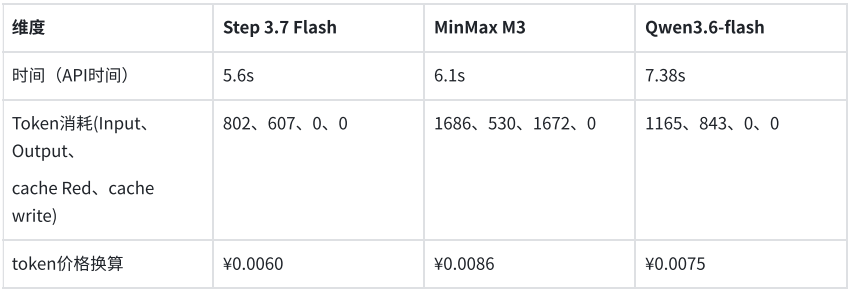
En combinant les deux tests, la stabilité de la qualité de la compréhension visuelle et de la sortie structurée des trois modèles répond aux exigences initiales de production, sans erreur d’extraction. Pour les scénarios d’agent ou d’API métier à appels fréquents, la latence de réponse et la consommation de tokens deviennent des indicateurs clés de différenciation. Dans cette comparaison, Step 3.7 Flash, tout en maintenant une qualité de sortie équivalente, offre une réponse plus rapide et un coût inférieur, ce qui en fait le modèle le plus adapté pour un déploiement prioritaire en environnement de production.