

Lorsque les utilisateurs demandent à ChatGPT de générer des images dans le style Ghibli, c’est en réalité DALL-E qui produit l’image. Cet outil basé sur un modèle de diffusion peut créer des visuels époustouflants, mais il présente des limites : erreurs occasionnelles comme des mains à trois doigts ou des visages déformés, et difficultés à fonctionner sur des appareils à ressources computationnelles limitées. Une équipe dirigée par les professeurs Ryu Jae-jun et Yoon Sung-hwan de l’École supérieure d’intelligence artificielle de l’Université des Sciences et Technologies d’Ulsan (UNIST) a proposé un nouveau principe de conception pour les IA génératives afin de résoudre ces problèmes.
Les modèles de diffusion, utilisés dans des applications populaires comme DALL-E et Stable Diffusion, permettent le transfert de style ou la création de dessins animés, mais souffrent, lors du déploiement, d’une accumulation d’erreurs, de dégradation des performances et d’une vulnérabilité aux attaques adverses. L’équipe a découvert que ces problèmes proviennent d’une capacité de généralisation limitée du modèle, c’est-à-dire de sa difficulté à fonctionner de manière fiable sur de nouvelles données ou dans des environnements inconnus.
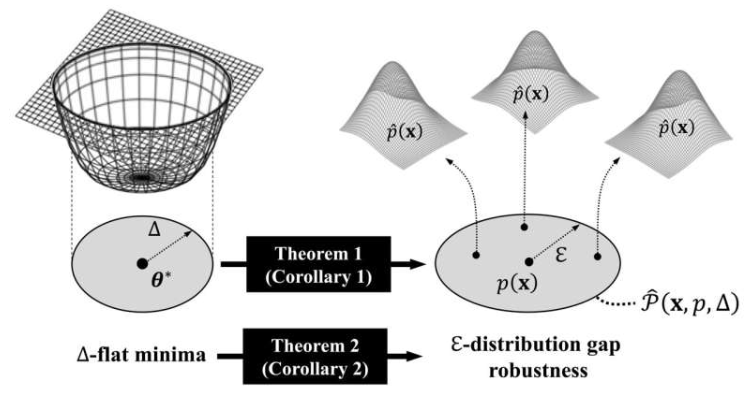
Pour y remédier, les chercheurs ont proposé d’orienter l’entraînement vers des « minima plats » (flat minima) situés sur la surface de la fonction de perte du modèle – des zones larges et peu pentues qui assurent une stabilité et une fiabilité même en cas de petites perturbations ou de bruit. Parmi les algorithmes recherchant ces minima plats, la minimisation perceptive de la netteté (Sharpness-Aware Minimization, SAM) s’est révélée la plus efficace. Les modèles entraînés avec SAM accumulent moins d’erreurs lors de tâches de génération rapide, conservent une meilleure qualité après compression et voient leur résistance aux attaques adverses multipliée par sept, renforçant considérablement leur robustesse.
L’équipe souligne que se concentrer sur les minima plats offre une solution unifiée aux problèmes d’accumulation d’erreurs, d’erreurs de quantification et de vulnérabilités adverses. Le cadre proposé améliore non seulement la qualité des images, mais permet aussi de concevoir des systèmes d’IA générative fiables et complets, applicables efficacement dans divers secteurs et scénarios réels, même avec des données limitées pour entraîner de grands modèles.