fr.wedoany.com Rapport : Le 10 juin 2026, Zilliz, basée à Redwood City, en Californie, a annoncé le lancement de la version préliminaire publique de Zilliz Vector Lakebase. Il s'agit d'une mise à jour majeure de Zilliz Cloud, visant à combiner une base de données vectorielles de niveau production avec une infrastructure de données native pour lacs de données partagée.
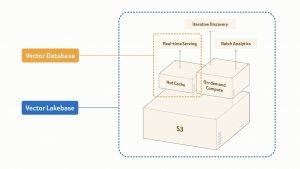
Vector Lakebase repose sur la recherche vectorielle en temps réel de Zilliz Cloud, un moteur qui sert déjà Zillow, OpenEvidence, Exa, Filevine, MiniMax et plus de 10 000 entreprises et équipes d'IA. Cette mise à jour étend les capacités avec trois nouvelles façons d'opérer sur les mêmes données : la découverte interactive, l'analyse par lots à grande échelle et la recherche directe sur les lacs de données externes. Le résultat est une infrastructure de données unique où toutes les charges de travail s'exécutent sur une seule copie logique des données, avec une facturation uniquement pour les tâches à la demande et par lots lorsque le calcul est actif.
Charles Xie, fondateur et PDG de Zilliz, a déclaré que la recherche vectorielle de niveau production est au cœur de l'entreprise et la raison pour laquelle des milliers d'équipes choisissent Milvus et Zilliz Cloud. Vector Lakebase représente la prochaine étape selon Zilliz : une infrastructure de données où le même vecteur peut servir les requêtes de production, alimenter les sessions de découverte et piloter des pipelines de données d'entraînement à l'échelle du pétaoctet, sans duplication, migration ni piles parallèles.
En ce qui concerne l'importance d'une infrastructure de données unique, les systèmes d'IA ne se limitent plus à un simple problème de récupération par requête. Ils fonctionnent en boucle continue, incluant la fourniture de services, l'apprentissage à partir des retours, l'exploration et la préparation de meilleures données, puis la fourniture de services à nouveau. Chaque étape nécessite généralement des systèmes indépendants pour le service, l'exploration et le traitement à grande échelle. Déplacer des milliards de vecteurs entre ces systèmes peut prendre des jours. Vector Lakebase comble cet écart en construisant un plan de données sémantique à copie zéro sur un stockage natif pour lacs de données partagé, permettant aux services en temps réel, à la découverte interactive et à l'analyse par lots de s'exécuter sur une seule copie logique des données, à des échelles allant du gigaoctet au pétaoctet.
Robert Guo, vice-président des produits chez Zilliz et l'un des architectes de Milvus, a indiqué que l'équipe souhaitait trouver un moyen de conserver les données à un seul endroit et d'exécuter des charges de travail très différentes sur celles-ci. Vector Lakebase y parvient grâce à une couche de stockage unifiée sur Vortex, un service hiérarchisé pour le chemin de production et un calcul à la demande pour tous les autres besoins.
Vector Lakebase offre cinq capacités clés sur une base unique. Premièrement, un service hiérarchisé en temps réel propose trois niveaux de production optimisés pour différentes charges de travail : optimisé pour les performances (1000+ QPS, latence de quelques millisecondes, mémoire), optimisé pour la capacité (100–500 QPS, latence inférieure à 100 ms, mémoire plus NVMe) et stockage hiérarchisé (10–50 QPS, latence d'environ 100 ms, couvrant mémoire, NVMe et stockage objet, avec une réduction significative des coûts). Tous les niveaux offrent un rappel par défaut de 95–98 %, ajustable à plus de 99 %, et sont soutenus par le SLA de disponibilité de 99,99 % de Zilliz Cloud et la haute disponibilité inter-régionale des clusters mondiaux. Deuxièmement, la recherche à la demande propose un calcul à la carte pour les charges de travail où l'infrastructure reste inactive la plupart du temps, avec une facturation directe du stockage objet et du calcul. Un benchmark interne de Zilliz sur 1 milliard de vecteurs à 768 dimensions, avec 10 heures de calcul actif par mois, a montré que la recherche à la demande coûtait 318 $ au total, contre 4 937 $ pour un chemin sans serveur similaire, soit un coût environ 15 fois inférieur. Troisièmement, la recherche sur les lacs de données externes est un mode de collection externe à copie zéro qui ajoute des index de pointe et une recherche à spectre complet aux tables Lance, Iceberg, Parquet et Vortex existantes, avec une synchronisation incrémentielle lors des actualisations, les données sources restant à leur emplacement d'origine. Quatrièmement, la recherche IA à spectre complet prend en charge la recherche sur les vecteurs (denses et creux), le texte, JSON et les données géospatiales, avec des capacités de recherche hybride, BM25, expressions régulières, recherche multi-vecteurs et itérative, ainsi que la récupération multi-chemins. Les résultats peuvent être réordonnancés à l'aide de Cohere, Voyage AI, RRF, ainsi que de stratégies de pondération, d'amplification ou d'atténuation. Cinquièmement, le stockage natif unifié pour lacs de données est construit sur Vortex pour partager le stockage entre les services et l'analyse. Vortex est un format de colonne ouvert conçu pour des lectures aléatoires plus rapides et moins coûteuses que Lance et Parquet, associé à des index adaptés au stockage objet, réduisant l'amplification de lecture de plus de 90 %. Un remblayage de schéma sur 100 millions de lignes peut généralement être effectué en quelques minutes, sans interrompre le trafic de requêtes actives.
Ces capacités permettent aux équipes d'IA de consolider les clusters de services parallèles toujours actifs et les systèmes par lots indépendants auparavant nécessaires en une seule plateforme, avec des index cohérents, des données versionnées et des ressources de calcul pouvant être réduites à zéro entre les tâches.
Zilliz Vector Lakebase est désormais disponible en version préliminaire publique sur Zilliz Cloud, avec des options de déploiement sans serveur, dédié et BYOC, couvrant plus de 30 régions sur AWS, Google Cloud et Microsoft Azure. L'inscription avec une adresse e-mail professionnelle donne droit à 100 $ de crédit gratuit. Les équipes qui exécutent des services, des découvertes et des analyses sur des piles indépendantes peuvent contacter l'équipe Zilliz pour un accompagnement personnalisé.
Zilliz est une entreprise d'infrastructure de données pour l'IA et le créateur de la base de données vectorielles open source Milvus, qui compte plus de 44 000 étoiles GitHub et plus de 100 millions de téléchargements Docker. Zilliz aide les entreprises et les startups d'IA à rendre leurs données non structurées consultables, analysables et gouvernables. Sa technologie repose sur Milvus et Zilliz Cloud. Milvus est une base de données vectorielles open source conçue pour la recherche vectorielle à l'échelle de centaines de milliards. Zilliz Cloud étend cette base en une plateforme Vector Lakebase entièrement gérée, combinant les capacités de service à haut débit et faible latence d'une base de données vectorielles avec l'ouverture, l'évolutivité et l'économie d'un lac de données multimodal. Zilliz soutient plus de 10 000 entreprises et startups d'IA natives dans le monde, notamment MiniMax, OpenEvidence, Filevine, Exa, Salesforce et Read AI. L'entreprise est basée à Redwood Shores, en Californie, et est soutenue par des investisseurs tels que Prosperity 7 Ventures d'Aramco, Pavilion Capital de Temasek, Hillhouse Capital, 5Y Capital, Qiming Venture Partners et Trustbridge Partners.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com