fr.wedoany.com Rapport : Nvidia a annulé le projet d’accélérateur AI Rubin Ultra à quatre puces de calcul, au profit d’une conception à deux puces GPU, en raison de difficultés de production dépassant les prévisions. Initialement prévu pour 2027, le Rubin Ultra était considéré comme le nœud le plus ambitieux de la feuille de route de l’entreprise, visant à doubler les performances par rapport au Rubin original (conception à deux puces). Cependant, la connexion de quatre puces proches de la taille du masque et le refroidissement de 16 modules HBM4E constituaient un défi d’ingénierie colossal. Selon SemiAnalysis, en raison de « préoccupations liées à l’exécution de la fabrication », Nvidia a décidé d’abandonner cette approche au profit d’une architecture à deux puces de calcul plus facile à produire en série.

Les performances du Rubin Ultra révisé devraient être la moitié de celles de la version originale, ce qui pourrait réduire son avantage concurrentiel face à des rivaux comme la série AMD Instinct MI500. Cependant, Nvidia pourrait encore optimiser l’efficacité globale de l’accélérateur AI pour justifier sa valeur ajoutée. De plus, le Rubin Ultra utilisera la mémoire HBM4E au lieu du HBM4 du Rubin original. À partir du GPU Rubin, Nvidia prévoit de fournir des systèmes rack Kyber refroidis par liquide, augmentant le nombre de GPU encapsulés par domaine d’extension à au moins 144, améliorant ainsi les performances de calcul totales livrées aux clients.
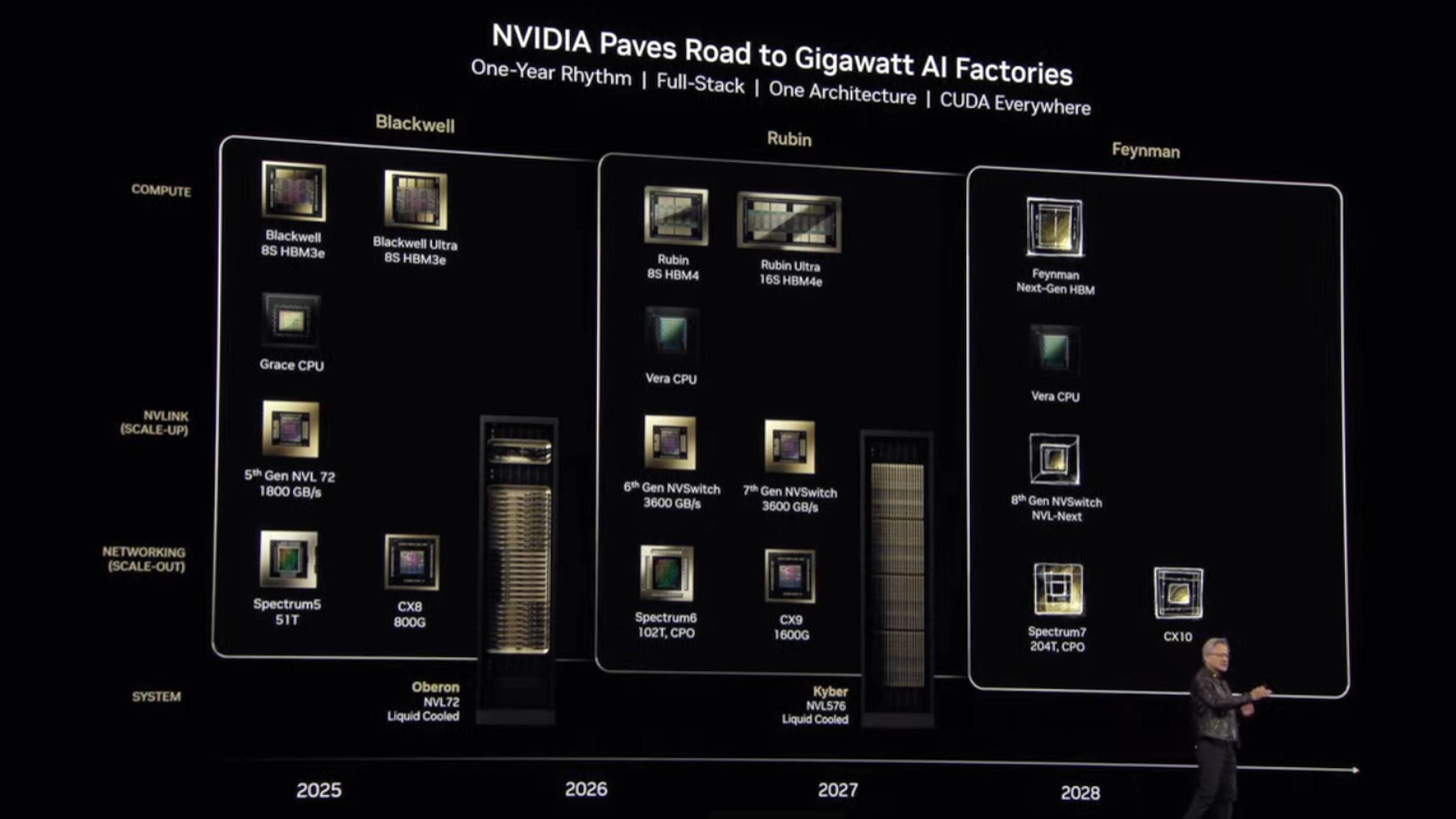
L’abandon de l’accélérateur AI équipé de 16 modules HBM4E pourrait avoir un impact sur le marché HBM, car la nouvelle version du Rubin Ultra n’utilise que huit modules HBM4E. Par ailleurs, la conception à deux puces rend le coût unitaire du GPU Rubin Ultra inférieur à celui de la version originale. Étant donné que Nvidia vend principalement des solutions rack complètes plutôt que des GPU indépendants, l’évolution des dépenses réelles des partenaires reste à observer : si davantage de systèmes sont achetés pour obtenir le même nombre de puces de calcul, les dépenses totales pourraient être plus élevées qu’avec l’approche initiale.