

fr.wedoany.com Rapport : Alors que le ralentissement de la mise à l'échelle de la densité des transistors se poursuit, l'encapsulation avancée est devenue la principale voie d'extension. Cependant, les accélérateurs d'intelligence artificielle sont volumineux et nécessitent des vitesses d'interconnexion extrêmement élevées, ce qui pousse l'encapsulation elle-même à ses limites. L'interposeur circulaire limite la taille de l'encapsulation et le taux d'utilisation des tranches de silicium. La technologie HBM4E double le nombre d'E/S tout en augmentant la vitesse, tandis que les encapsulations de plusieurs kilowatts rendent les architectures de refroidissement traditionnelles difficiles à supporter.
L'ECTC est le principal salon technologique dédié à l'encapsulation. Les annonces de cette année sont étroitement liées aux produits commerciaux à venir. Intel a présenté l'intégration de l'EMIB-T, la mise à l'échelle de la taille de l'encapsulation et sa feuille de route future. Marvell a montré comment, grâce à un HBM personnalisé, la logique d'interface peut être retirée de l'accélérateur tout en raccourcissant le câblage de l'encapsulation. TSMC et Microsoft intègrent directement le liquide de refroidissement dans le silicium, tandis que Marvell et Lightmatter intègrent des interconnexions optiques dans l'encapsulation.
Cette synthèse couvre les technologies présentées à l'ECTC 2026 qui sont les plus susceptibles de façonner les solutions d'accélérateurs d'IA dans les années à venir.
Intel EMIB-T
Intel est le plus grand intervenant industriel au salon ECTC. Sa présentation phare est l'EMIB-T. Il s'agit de la prochaine génération de puces EMIB utilisant la technologie des trous d'interconnexion en silicium (TSV). Après le lancement initial, Intel a affiné l'architecture et la feuille de route, incluant un pas de bosse plus petit, une taille d'encapsulation plus grande et des fonctionnalités de pont. Leur démonstration suggère que l'EMIB-T est destiné à être utilisé dans le TPU v9 de Google et constitue l'alternative la plus fiable à la plateforme CoWoS de TSMC dans le domaine des accélérateurs d'IA à grande encapsulation.
Puce de test d'extension EMIB-T, avec une teneur en silicium équivalant à deux fois le masque. Les images MEB en vue de dessus montrent des pas de bosse de 110, 55 et 36 micromètres.

Intel a validé la technologie EMIB-T sur une puce encapsulée avec un silicium de taille double de celle du masque, avec un pas de bosse de 36/35 µm. Par rapport au pas de 45 µm utilisé dans l'encapsulation Granite Rapids, la densité des bosses a augmenté de 65 %. Le Granite Rapids-AP est une encapsulation de grande taille, mesurant 70 mm × 105 mm, soit une superficie légèrement inférieure à 9 masques. Actuellement, la validation pour un pas de bosse de 36/35 µm est étendue à des encapsulations de silicium de 4,5 fois la taille du masque, avec pour objectif une certification d'ici fin 2026.

L'étape suivante en matière de pas est également en cours. Intel teste un pas de bosse de 25 µm, basé sur une puce composée de deux puces de silicium d'un masque reliées par un seul pont EMIB-T de 3 mm × 18 mm.
Une réduction supplémentaire de la taille deviendra plus difficile. En dessous de 25 µm, le volume de soudure dans chaque bille devient très faible. La probabilité de courts-circuits, de circuits ouverts et de pertes de rendement dues à l'assemblage augmente considérablement. L'EMIB-T peut continuer à réduire la taille, mais le facteur limitant passe de la densité de câblage du pont à la formation des billes de soudure, à la précision de l'alignement et au rendement d'assemblage.
Intel a également présenté les limites de taille de l'encapsulation EMIB-T. Bien que des encapsulations de taille de panneau complet soient possibles, Intel considère l'encapsulation de quart de panneau comme un objectif pratique. Ils ont présenté un échantillon de test de 240 mm × 240 mm, d'une superficie équivalant à environ 67 masques lithographiques. Cependant, l'échantillon sur le stand présentait un gauchissement important. À cette taille, le pont n'est qu'une partie du problème. La manipulation du substrat, le gauchissement, la précision de l'alignement et la structuration au niveau du panneau deviennent des facteurs limitants primordiaux. Intel évalue également des technologies de lithographie avancées pour garantir une précision d'alignement suffisante sur ces grands substrats, que ce soit au format quart de panneau ou panneau complet.
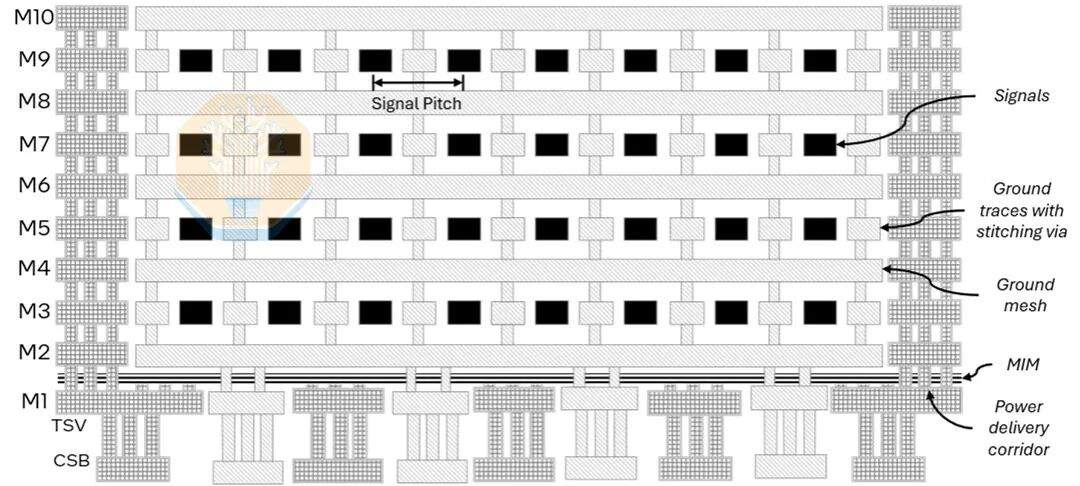
Bien que le pas de bosse et la taille de l'encapsulation soient importants, le circuit de pont est tout aussi crucial. L'EMIB-T est beaucoup plus complexe que l'EMIB utilisé dans les produits actuels. Il ajoute des TSV, davantage de couches métalliques, des grilles d'alimentation et des couches de condensateur MIM, permettant au circuit de pont de transporter simultanément des signaux à haute densité et une alimentation verticale. Intel a présenté une coupe transversale montrant 10 couches métalliques (dont 4 couches de routage) ainsi qu'un condensateur MIM entre M1 et M2. Intel a mis l'accent sur ses améliorations pour le HBM4E.
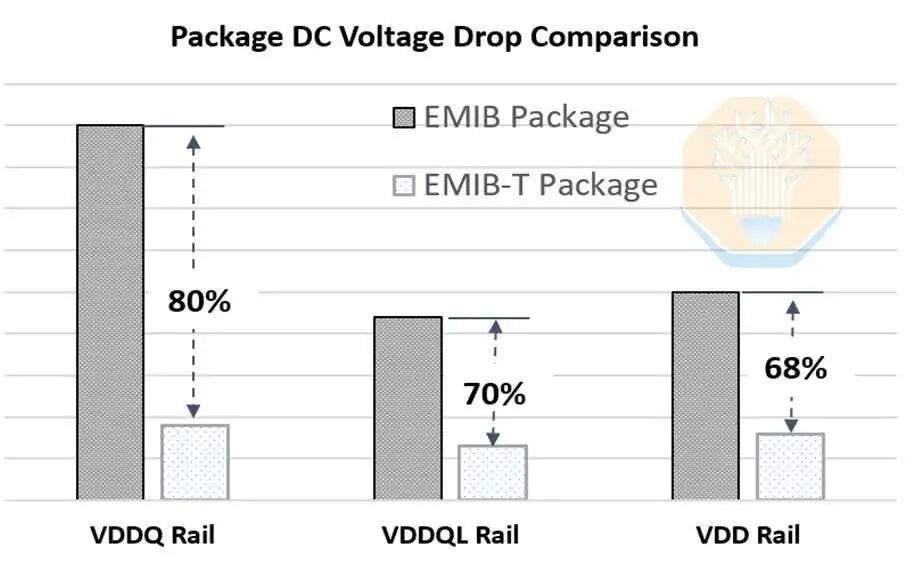
Le « T » dans EMIB-T signifie TSV (Through-Silicon Via). Leur rôle est l'alimentation électrique. Dans l'EMIB traditionnel, l'alimentation dans les zones non pontées est transmise verticalement à travers le substrat, tandis que l'alimentation près des zones pontées doit se diffuser latéralement dans le câblage de l'encapsulation et du côté de la puce. En utilisant des TSV dans la zone du pont, l'alimentation peut être transmise directement à travers la zone du pont, réduisant ainsi considérablement le chemin du courant. Intel affirme que l'utilisation de ces TSV peut réduire la chute de tension continue de 68 % à 80 %.
La difficulté du HBM4E réside dans le fait que l'interconnexion doit simultanément augmenter la densité des signaux et la capacité d'alimentation. Le HBM4 a deux fois plus de broches que le HBM3, et le PHY nécessite des rails d'alimentation supplémentaires, tels que VDDQ et VDDQL. Ces rails d'alimentation occupent une partie de l'espace de routage des signaux, augmentant ainsi la densité des signaux dans l'espace restant.
Pour résoudre ce problème, Intel n'utilise pas le même routage pour tous les canaux HBM. Il place les chemins de signaux les plus longs sur des couches au routage plus simple. Sur la couche M9, seulement environ 28 % de la longueur des canaux les plus longs traverse les zones de routage les plus denses, tandis que sur des couches inférieures comme M3, ce pourcentage monte à environ 84 %, mais ces canaux sont plus courts. Cela évite que la diaphonie et la perte d'insertion ne soient principalement causées par les zones de routage les plus mauvaises.
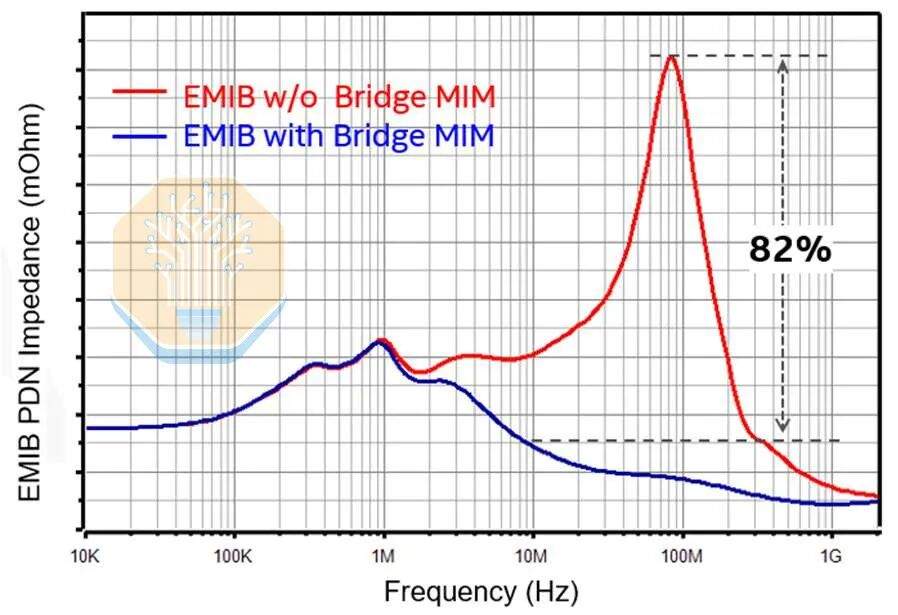
Le transfert d'énergie a également été déplacé vers la couche de pont. L'EMIB-M a introduit des condensateurs métal-isolant-métal (MIM) entre M1 et M2, et l'EMIB-T les a améliorés. Intel a annoncé une densité de capacité de 500 nF/mm², ce qui est à peu près équivalent au condensateur MIM de l'Intel 18A. Intel affirme que, par rapport à une encapsulation EMIB-T sans condensateur MIM de pont, ces condensateurs de pont peuvent réduire l'impédance AC du réseau de distribution d'énergie (PDN) de plus de 82 %.
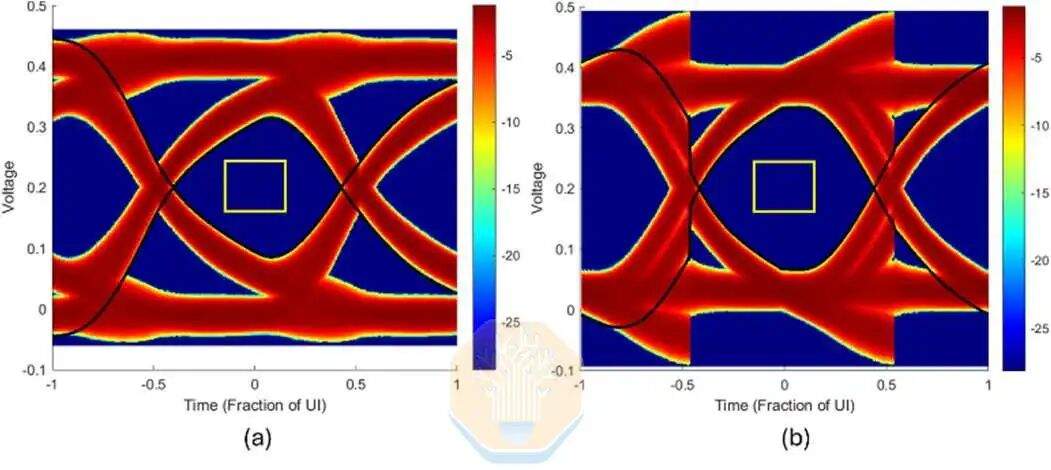
Intel a également réalisé des simulations de l'EMIB-T avec le HBM4E. À un débit de 12 Gb/s, sans égalisation en réception, la largeur de l'œil UI d'Intel est d'environ 67 %. Avec un égaliseur à décision feedback à un seul coefficient (DFE), cette valeur peut atteindre environ 72,5 %. Le DFE est un circuit côté réception qui réduit l'interférence des bits précédents après le passage du signal à travers le canal d'encapsulation.
Intel a également simulé des vitesses de transmission plus élevées, respectivement 12,8 Gb/s, 14 Gb/s et 16 Gb/s. À toutes les vitesses testées, la largeur de la fenêtre de l'interface utilisateur est restée supérieure à 60 %, avec une légère diminution de la capacité du plot.
La feuille de route EMIB d'Intel va au-delà de la technologie de pont passif ne comprenant que du câblage et des condensateurs. Les versions futures incluront des condensateurs MIM de pont à plus haute densité, des puces de pont à rapport d'aspect élevé de plus grande taille, des pas de bosse inférieurs à 25 micromètres, des ponts actifs et des régulateurs de tension intégrés à l'intérieur de la puce EMIB. Intel a également présenté le concept de condensateur à tranchée profonde (DTC) intégré dans le substrat central et de condensateur eMIM-T > 2500 nF/mm² intégré sous le substrat, bien que ces technologies n'aient pas encore été observées dans les produits EMIB expédiés.
L'EMIB-T est encore en retard sur la plateforme CoWoS de TSMC à plusieurs égards. TSMC a déjà intégré le DTC/eDTC et est plus avancé dans l'intégration des régulateurs de tension et des interconnexions locales actives en silicium (LSI). L'EMIB-T réduit l'écart, mais Intel rattrape encore un écosystème qui fonctionne à grande échelle depuis des années.
HBM personnalisé de Marvell
Lors de la journée des analystes industriels de Marvell en 2024, Marvell a annoncé le HBM personnalisé. À l'époque, il s'agissait d'une déclaration vague, sans détails techniques. La conception du HBM a toujours été centrée sur la compatibilité JEDEC : des empilements DRAM standard fournis par les fabricants de mémoire, un PHY HBM standard sur l'accélérateur et une interface large fixe entre eux. Lors du Hot Chips 2025, Marvell a présenté le schéma d'implantation de la puce de base personnalisée.

À l'ECTC, Marvell a finalement fourni des détails au niveau de l'encapsulation pour le HBM4E personnalisé.
La spécification JEDEC fixe l'interface entre l'empilement HBM et l'hôte. Cela favorise l'interopérabilité : le HBM de n'importe quel fabricant de mémoire peut être associé à n'importe quel hôte compatible. Cependant, cela nuit à la consommation d'énergie, aux performances et à la surface. L'ASIC hôte doit implémenter un PHY HBM standard avec un agencement de plots et des règles de routage standardisés, pour router une interface parallèle très large. À mesure que la taille de l'encapsulation augmente et que la vitesse du HBM s'accélère, cette frontière fixe rend plus difficile l'optimisation du littoral, de la densité de routage, de l'alimentation électrique et de l'intégrité du signal.

La technologie HBM personnalisée ne nécessite aucune modification des puces DRAM centrales. Au lieu de cela, une puce de base personnalisée est fabriquée à l'aide d'un processus logique avancé, avec une interface inter-puce optimisée. Cette puce de base personnalisée peut intégrer le contrôleur HBM, les fonctions de gestion et de surveillance, la logique personnalisée et une interface étendue.

Marvell affirme que cela réduit d'environ 60 % l'espace occupé par le PHY HBM et la logique associée sur l'ASIC hôte, libérant ainsi directement plus d'espace pour le calcul, le cache ou les E/S. Cette interface personnalisée déplace la majeure partie de l'interface côté mémoire vers la puce de base HBM.
L'exemple de Marvell utilise 1024 canaux à un débit de 32 Gb/s, atteignant 4,1 To/s, ce qui équivaut à une interface JEDEC HBM4(E) de 2048 bits à 16 Gb/s.
Le routage de l'encapsulation est également simplifié. L'interface personnalisée réduit la longueur des canaux de l'interposeur de 6,5 mm à 1,5 mm, permettant à Marvell d'augmenter la bande passante tout en conservant les mêmes 9 couches de routage et une largeur de ligne/espacement (L/S) de 2/2 µm.
Dans l'exemple de Marvell, un interposeur en couche de redistribution organique (RDL) est utilisé à la place du silicium, ce qui réduit le coût de l'encapsulation. La largeur de ligne/espacement du RDL organique est bien inférieure à celle de l'interposeur en silicium du CoWoS-S ou des ponts en silicium du CoWoS-L et de l'EMIB-T, ce qui augmente la difficulté de routage. Marvell s'appuie sur des motifs de blindage et de routage personnalisés dans différentes parties pour maximiser la densité de bande passante tout en contrôlant la diaphonie.

Lors du GTC, Nvidia a annoncé que Feynman utiliserait un HBM personnalisé. Les raisons de Nvidia sont probablement similaires à celles de Marvell : une bande passante plus élevée, une consommation d'énergie plus faible et une surface de puce d'accélérateur HBM réduite. Environ 16 % de la surface de la puce du GPU Rubin est dédiée à la logique et au PHY liés au HBM. Le HBM personnalisé permettrait à Nvidia de transférer la majeure partie de cette charge vers la puce de base HBM.
Le HBM personnalisé prend également en charge des interfaces étendues au-delà des liaisons HBM standard. La puce de base peut agir comme un contrôleur mémoire auxiliaire et répartir le trafic vers de la mémoire supplémentaire, plutôt que de forcer tout le trafic mémoire à passer par les canaux limités du bord de la puce de l'accélérateur. Cette mémoire supplémentaire peut être de la LPDDR, plus grande et à plus faible bande passante, ou même une deuxième couche de HBM. Cela permet à l'accélérateur d'étendre sa capacité mémoire sans monopoliser les précieux canaux de bord de puce nécessaires aux E/S externes. Ceci est particulièrement important pour les prochains GPU MI450 et MI500 d'AMD, qui prendront en charge la LPDDR pour augmenter la capacité mémoire.
Interposeur HBM de Samsung
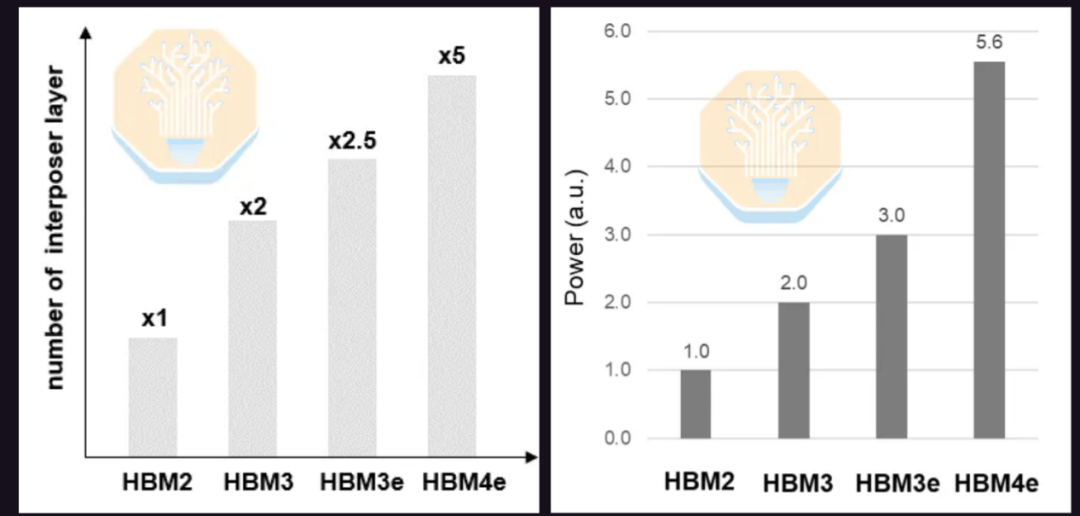
Samsung a également présenté sa solution HBM4E basée sur un interposeur. Le HBM4E augmente le débit de données à 12 Gb/s et plus, et double le nombre de broches d'E/S, ce qui accroît la complexité du routage. Le nombre d'interposeurs nécessaires pour le HBM4E pourrait être le double de celui du HBM3E et cinq fois celui du HBM2. En raison de l'augmentation du nombre de broches d'E/S et du débit de données, sa consommation d'énergie devrait également augmenter de 86 % par rapport au HBM3E et de 5,6 fois par rapport au HBM2.
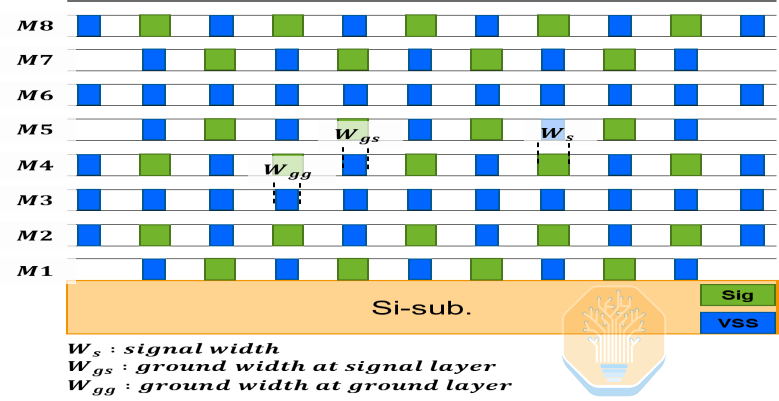
Samsung propose une solution d'interposeur en silicium à 8 couches, qui, selon elle, réduit le nombre de couches de 20 % par rapport aux besoins estimés. Cet interposeur utilise une disposition alternée répétée de deux signaux/un plan de masse pour blinder les signaux à haute vitesse, avec 75 % des couches dédiées au routage des signaux.
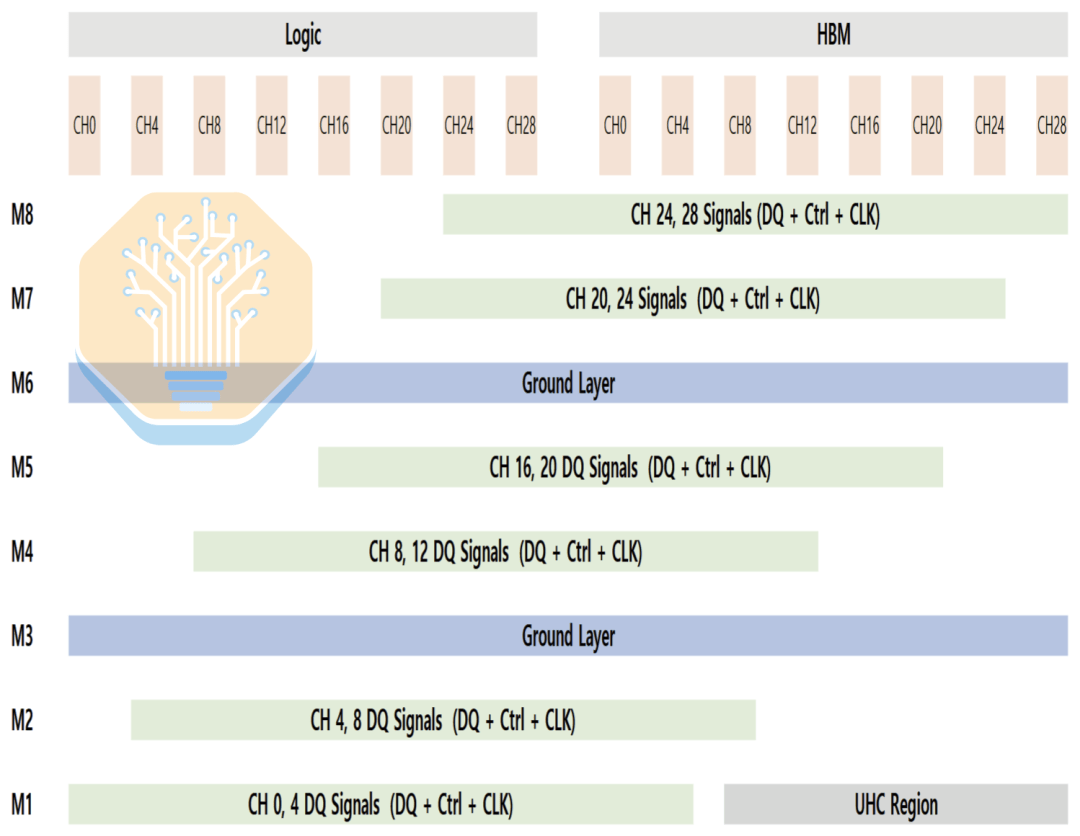
Une autre caractéristique clé de l'interposeur est le condensateur à ultra-haute densité (UHC). Samsung ne précise pas la structure exacte du condensateur, mais elle pourrait être similaire au condensateur MIM de l'EMIB-T d'Intel ou au condensateur DTC du CoWoS de TSMC. Le condensateur UHC ne peut être placé que sur la couche M1, qui est également principalement utilisée pour le routage des signaux, ce qui limite la surface disponible.
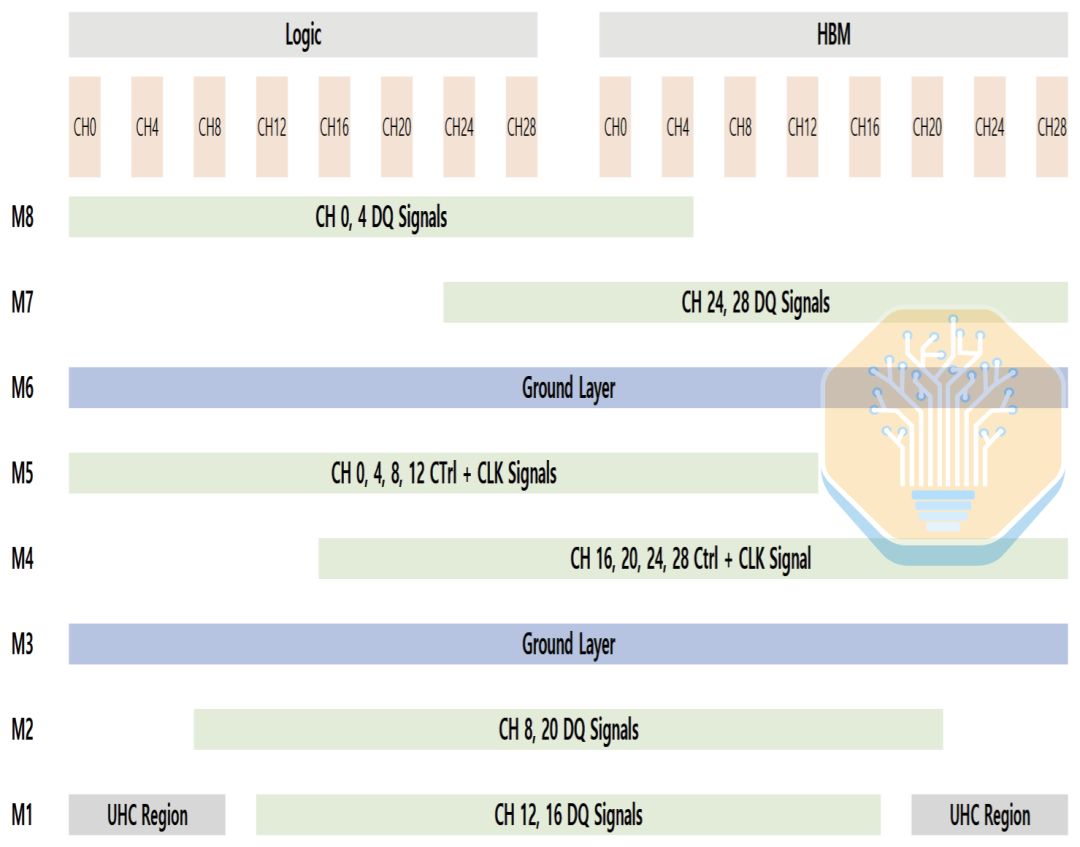
Si le routage est déséquilibré, le condensateur est poussé vers un côté de l'interface, entraînant des performances inégales du réseau de distribution d'énergie (PDN) entre le côté logique et le côté HBM. La disposition de Samsung redistribue le routage entre la couche M1 et d'autres couches, permettant ainsi à l'UHC d'être réparti plus uniformément sur toute l'interface. Cela réduit l'impédance du PDN et le bruit de tension tout en maintenant une densité de routage contrôlable.
Thermique de la liaison hybride HBM de Samsung
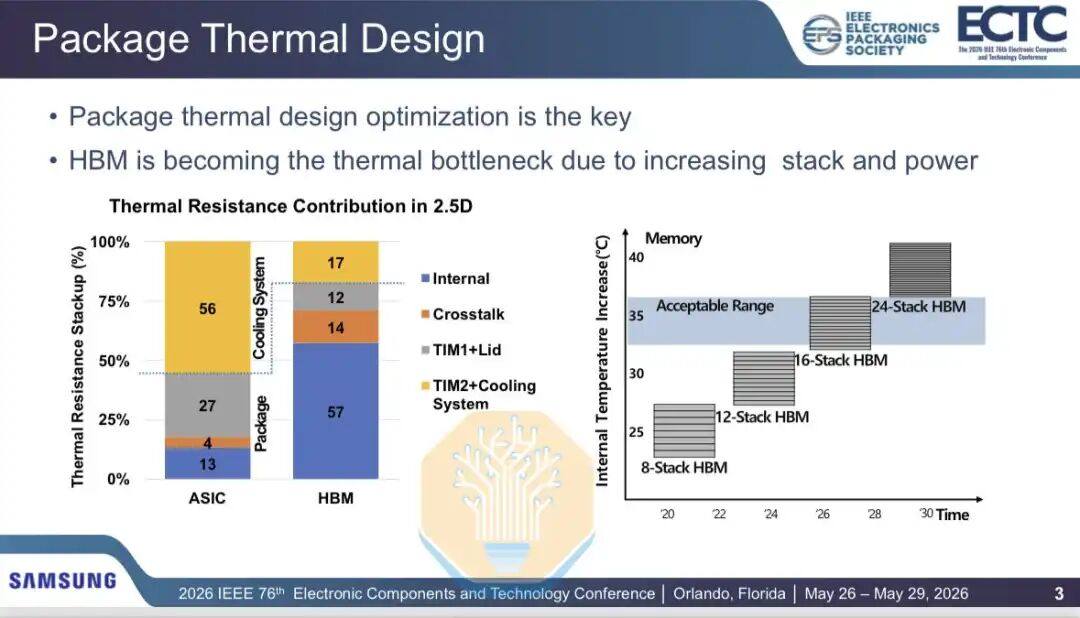
Samsung a également abordé les problèmes thermiques du HBM, en particulier la technologie de liaison hybride. Les empilements HBM deviennent de plus en plus nombreux et rapides, tandis que la consommation d'énergie de la puce logique en dessous augmente également. Pour le HBM à 16 couches, la résistance thermique est acceptable, mais à mesure que les futures générations évoluent vers le HBM à 20 et 24 couches, de nouvelles solutions seront nécessaires.
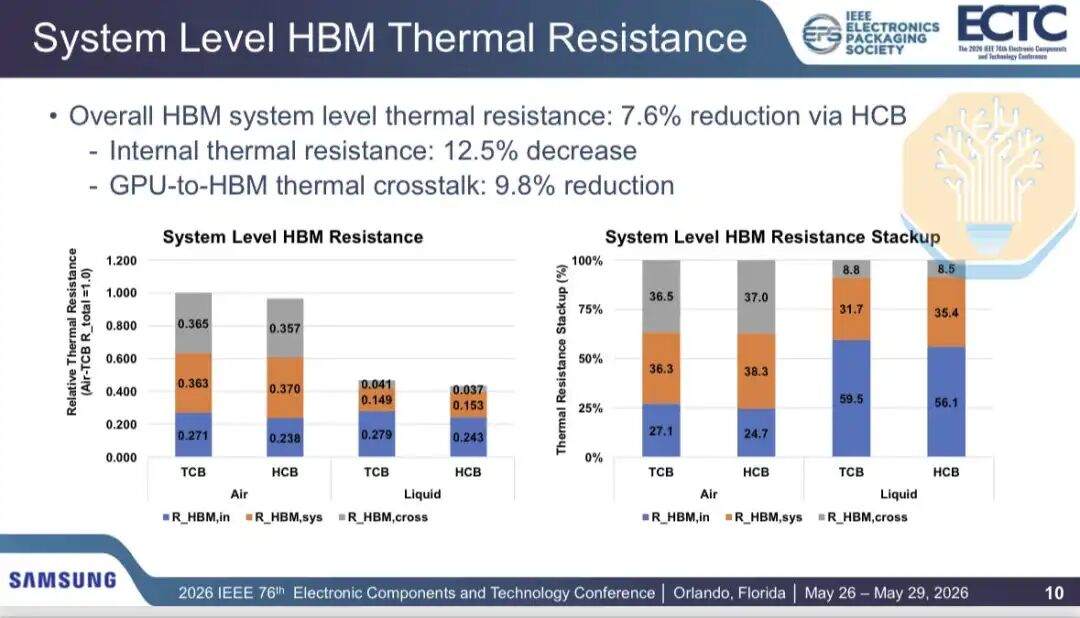
Samsung a comparé les performances thermiques du HBM entre la liaison par thermocompression (TCB) et la liaison hybride cuivre (HCB) dans une encapsulation GPU 2.5D (contenant 2 puces GPU et 8 empilements HBM, similaire à l'architecture Nvidia Blackwell). Les résultats montrent que le refroidissement par air peut réduire la résistance thermique interne du HBM de 12,2 %, et le refroidissement liquide de 12,9 %. La résistance thermique totale du HBM peut être réduite de 3,5 % avec le refroidissement par air et de 7,7 % avec le refroidissement liquide.
Étant donné que la HCB ne cible qu'une partie du réseau thermique, l'amélioration n'est pas uniforme. Samsung divise le chemin thermique en résistance thermique interne, résistance thermique au niveau du système et diaphonie GPU vers HBM. La résistance thermique interne et la diaphonie ont diminué respectivement d'environ 12,5 % et 9,8 %, mais la résistance thermique au niveau du système, incluant le matériau d'interface thermique et le dissipateur, a augmenté d'environ 2,3 %.
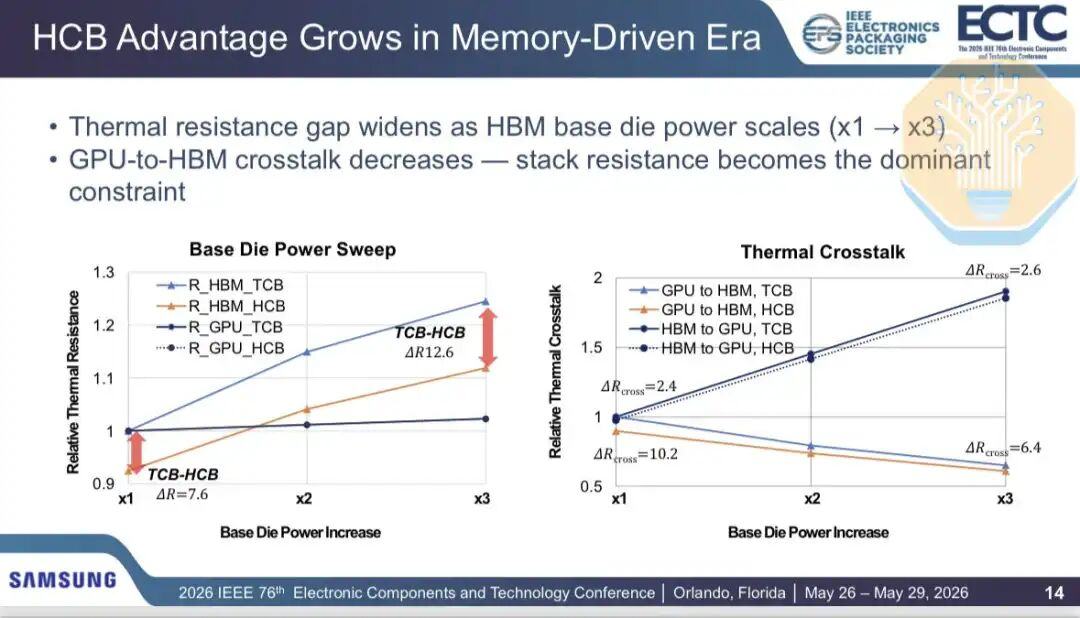
À mesure que davantage de puissance est transférée vers le substrat HBM (par exemple, dans les charges de travail à forte intensité mémoire), le goulot d'étranglement thermique se déplace. Ceci est particulièrement important pour le HBM personnalisé, car son contrôleur mémoire et davantage de circuits logiques sont intégrés au substrat. La proportion de la diaphonie GPU vers HBM dans la résistance thermique totale diminue, passant de 13 % lorsque la puissance du substrat est multipliée par 1 à 5 % lorsqu'elle est multipliée par 3.
Samsung indique que la technologie HCB permet d'augmenter la température de l'air entrant ou d'augmenter la puissance de l'encapsulation. Selon ses estimations, avec la technologie HCB, la température de l'air entrant peut être augmentée de 1 à 2 °C à puissance d'encapsulation constante, ou la puissance de l'encapsulation peut être augmentée d'environ 4 % à température constante. Samsung estime également que la puissance thermique dissipée sera réduite d'environ 7 %.
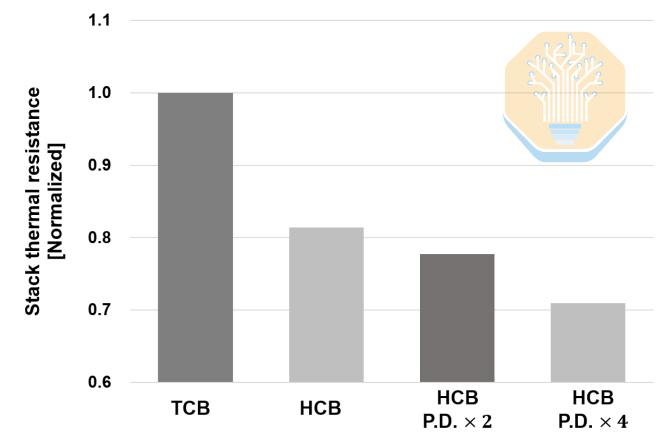
Samsung a également étudié séparément l'impact de la HCB au niveau de l'empilement. Les améliorations y sont plus importantes : par rapport à la TCB, la HCB de référence réduit la résistance thermique de l'empilement d'environ 19 %. En augmentant le nombre de plots HCB, la réduction de la résistance thermique peut atteindre 22,3 % pour une densité de plots multipliée par 2, et 29,1 % pour une densité multipliée par 4.
Refroidissement microfluidique
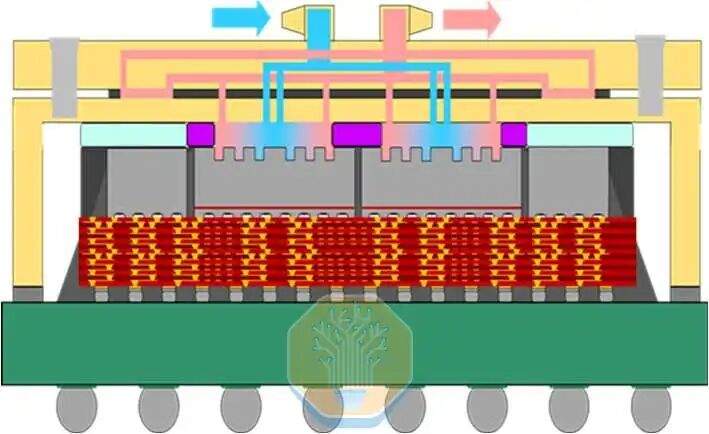
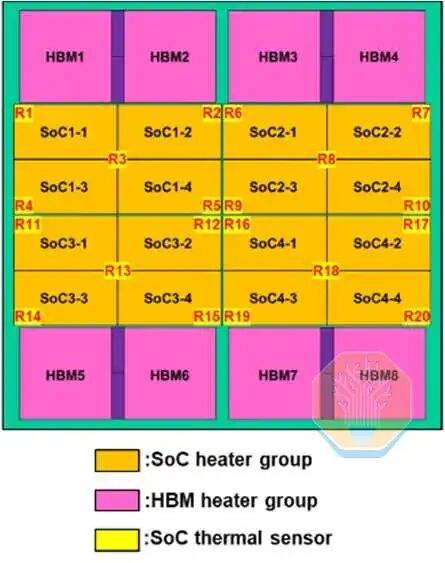
TSMC a présenté une technologie de refroidissement direct du silicium sur une puce CoWoS-R, utilisée dans une plateforme de test de type GPU. Le CoWoS-R se distingue du CoWoS-S par l'utilisation de matériaux organiques plutôt que d'un interposeur en silicium. Le CoWoS-R a été choisi pour sa meilleure tolérance au gauchissement et sa compatibilité de procédé. La plateforme de test utilise un interposeur de 3,3 fois la taille du masque, contenant 4 puces SoC et 8 empilements HBM. Chaque puce SoC est composée de 4 groupes de chauffages SoC qui couvrent ensemble environ la moitié de la surface de l'interposeur.
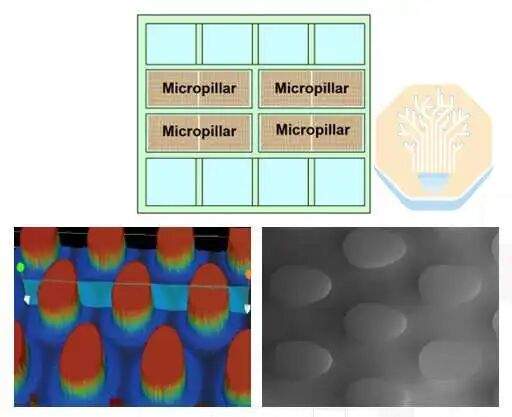
TSMC a comparé trois solutions : l'encapsulation traditionnelle avec un couvercle et un bloc de refroidissement, l'encapsulation sans couvercle avec un bloc de refroidissement, et sa conception d'encapsulation avec refroidissement direct du silicium à micropiliers. Les solutions avec et sans couvercle utilisent toujours un bloc de refroidissement traditionnel et un matériau d'interface thermique (TIM). La dernière solution, quant à elle, forme des micropiliers directement sur la face arrière de la puce SoC.
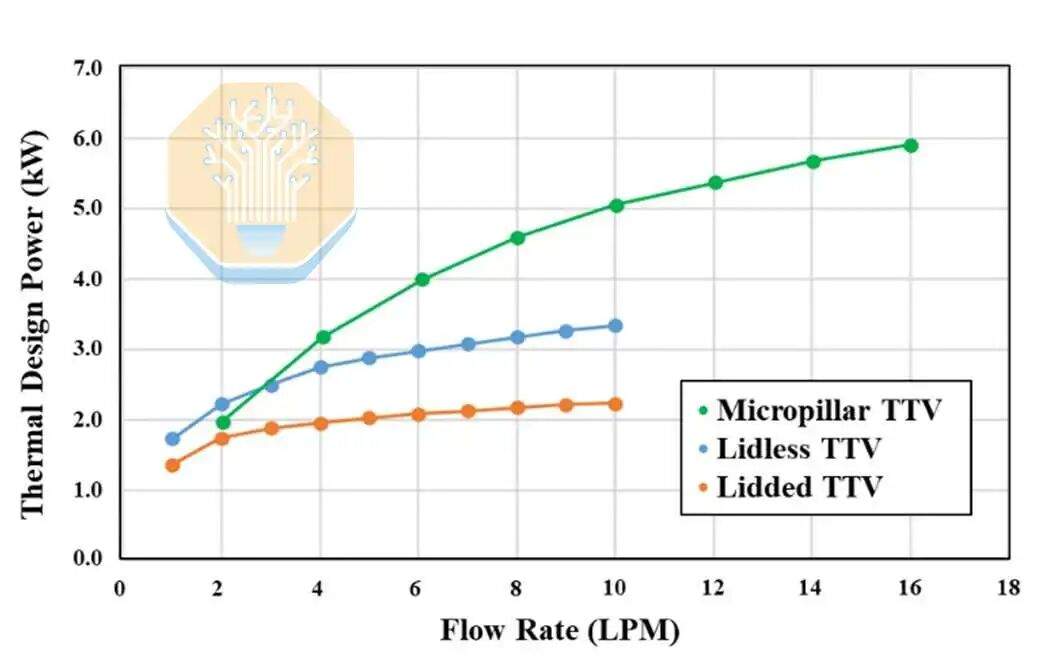
Avec un refroidissement conventionnel, à un débit de 1-2 litres par minute (LPM), la dissipation thermique de l'encapsulation avec couvercle est de 1,9 à 2,3 kW, tandis que celle de l'encapsulation sans couvercle est de 2,5 à 3,0 kW, avec de l'eau désionisée à 40 °C. Les deux solutions atteignent un plateau après un débit supérieur à 4 LPM, car le matériau d'interface thermique (TIM) devient le goulot d'étranglement.
Le véhicule de test à micropiliers a montré des performances comparables à celles du bloc de refroidissement sans couvercle à un débit de 2 LPM, puis a surpassé ce dernier à des débits plus élevés, atteignant une puissance thermique de 4 kW à 4 LPM et de 5,3 kW à 8 LPM. TSMC rapporte que la puissance thermique dépasse uniformément 5 kW sur l'ensemble du véhicule de test. La structure à micropiliers rapproche le liquide de refroidissement de la source de chaleur, favorisant ainsi les performances de dissipation thermique.
Cependant, la structure à micropiliers n'est pas parfaite. TSMC a dû former les micropiliers après le processus de chip-on-wafer (CoW), tout en évitant d'endommager la structure CoWoS-R, et développer de nouveaux matériaux d'étanchéité pour garantir l'étanchéité du liquide de refroidissement malgré le gauchissement de l'encapsulation et les désaccords de coefficients de dilatation thermique. Les échantillons de test ont passé le test de niveau de sensibilité à l'humidité 4 (MSL4) sans fuite d'hélium ni délaminage du joint.
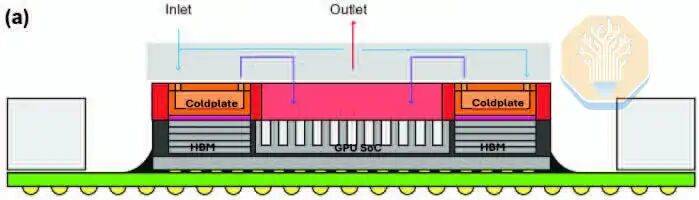
L'approche de refroidissement de Microsoft diffère de celle de TSMC par sa structure de dissipation thermique. TSMC utilise des micropiliers en silicium, tandis que Microsoft utilise des microcanaux droits gravés dans la tranche de silicium du GPU. Microsoft n'a pas utilisé de plateforme de test thermique, mais a testé directement sur un GPU Nvidia GH200. Cela a peut-être permis à Microsoft de capturer plus précisément la distribution thermique réelle et les points chauds. Microsoft a testé plusieurs charges de travail sur le GPU, telles que HPCG et HPL, chacune ayant des caractéristiques différentes de pression de calcul et de mémoire.
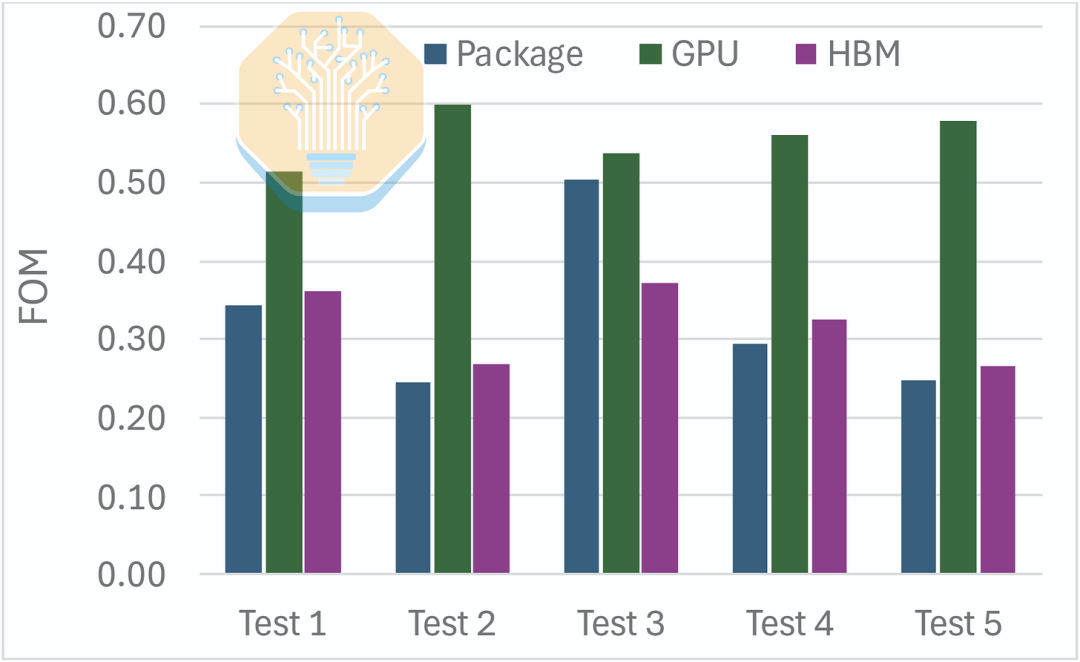
Sous ces charges de travail, Microsoft rapporte une réduction de 51 à 60 % de la résistance thermique de la jonction à l'entrée du GPU à un débit de 1 LPM. L'amélioration pour le HBM est plus modeste, de 27 à 37 %, car il est toujours refroidi via le bloc de refroidissement et le matériau thermique. Globalement, cela réduit la résistance thermique de l'encapsulation de 50 %.
Microsoft a également présenté quelques données de fiabilité préliminaires. Bien que les performances thermiques soient importantes, le déploiement dans les centres de données nécessite également une haute fiabilité et une faible indisponibilité. Sur une période de 6 mois, Microsoft n'a enregistré que 9 événements de blocage potentiels sur environ 4370 observations. Le taux de blocage a diminué au fil du temps, suggérant une instabilité initiale après l'installation, suivie d'une phase de fonctionnement plus stable. Même après 6 mois, aucune corrosion mesurable du silicium n'a été détectée dans les microcanaux. Au niveau du nœud, le GH200 a réussi des tests de référence répétés pendant 3 semaines, suivis d'une semaine de fonctionnement continu à puissance d'encapsulation stable. Microsoft teste encore le MTBF et la disponibilité au niveau du cluster.










