

fr.wedoany.com Rapport : Le 1er juin, la société chinoise d’intelligence artificielle MiniMax a dévoilé son nouveau modèle généraliste, le MiniMax M3. Ce modèle repose sur l’architecture propriétaire MiniMax Sparse Attention. Son API prend en charge une fenêtre de contexte allant jusqu’à 1 million de tokens, garantissant au moins 512 000 tokens utilisables. Il est principalement conçu pour les agents à longues tâches, les tâches de codage complexes et les applications multimodales natives.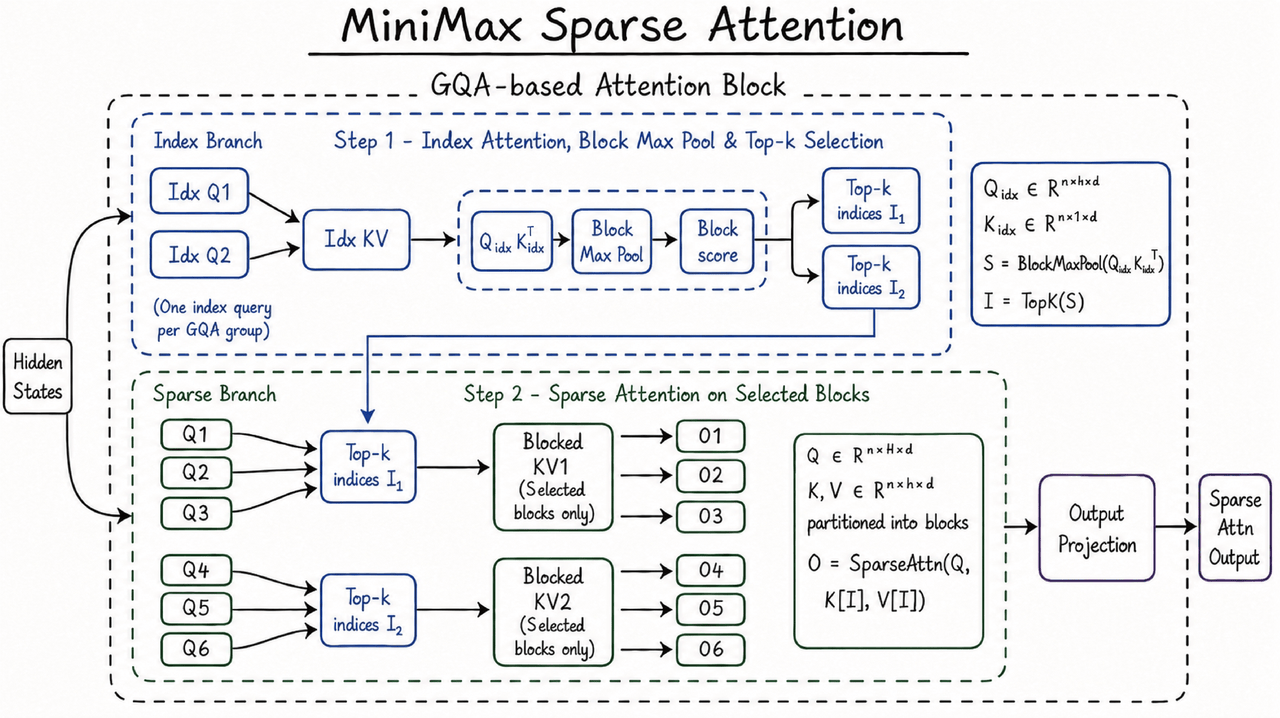
Le changement principal du MiniMax M3 réside dans le passage de la capacité de contexte long d’un « indicateur de paramètre » à un « support de tâche d’ingénierie ». Alors que les applications des grands modèles entrent dans la phase des agents, les modèles ne doivent plus traiter uniquement des questions-réponses uniques ou des générations de texte court, mais des tâches longues entrelaçant des dépôts de code, des documents produits, des journaux de tâches, des enregistrements d’appels d’outils, ainsi que des informations d’images et de vidéos. Une fenêtre de contexte d’un million de tokens signifie que le MiniMax M3 peut conserver davantage d’informations en amont et en aval dans une chaîne de tâches unique, réduisant ainsi les pertes d’informations dues aux troncatures fréquentes, aux résumés répétés et aux recherches externes. Pour le développement logiciel, la reproduction scientifique, les questions-réponses sur les bases de connaissances d’entreprise, la compréhension de longues vidéos et les scénarios complexes d’automatisation de bureau, le contexte long devient une capacité fondamentale essentielle pour qu’un modèle puisse entrer de manière stable dans les processus de production.
Cette capacité est soutenue par l’architecture MiniMax Sparse Attention développée en interne par MiniMax. Les mécanismes d’attention traditionnels complets sont confrontés à une augmentation rapide de la charge de calcul lorsque la longueur du contexte s’accroît. MSA améliore l’efficacité de calcul dans les contextes longs grâce à une attention éparse, permettant au MiniMax M3 de maintenir des performances d’inférence utilisables dans une fenêtre de contexte de l’ordre du million. Selon les informations officielles, avec une longueur de contexte d’un million, la charge de calcul par token du M3 est environ 1/20 de celle du modèle de la génération précédente, la vitesse de la phase de pré-remplissage est multipliée par plus de 9, et la vitesse de la phase de décodage est multipliée par plus de 15. Pour les développeurs et les utilisateurs professionnels, ces changements d’efficacité affectent directement le coût de l’API, la vitesse de réponse et la capacité d’exécution continue des tâches longues, déterminant également si le MiniMax M3 peut passer des scénarios de démonstration à des appels métier plus fréquents.
Le MiniMax M3 met également l’accent sur les capacités de codage et d’agent. Les tâches de génie logiciel sont devenues un scénario clé dans la compétition des capacités des grands modèles, car un processus de développement réel comprend généralement la clarification des besoins, la modification du code, le retour de test, l’appel d’outils, l’itération de version et la collaboration multi-tours. MiniMax a révélé que le M3 a obtenu des scores élevés dans des évaluations telles que SWE-Bench Pro, Terminal-Bench 2.1, KernelBench Hard et MCP Atlas, et a formé le modèle à s’adapter à des scénarios de collaboration continue via un cadre de simulation utilisateur. Cette orientation montre que le MiniMax M3 ne se contente pas d’améliorer la capacité à « écrire un morceau de code », mais tente de couvrir l’ensemble de la chaîne de développement, de la décomposition des tâches, à l’exécution, la vérification et la correction itérative.
La multimodalité est également l’une des capacités clés du MiniMax M3. Ce modèle intègre des données multimodales dès les premières phases de l’entraînement, permettant aux informations textuelles, images et vidéos d’être traitées en collaboration au sein d’une même tâche. Dans les cas d’usage officiels, le MiniMax M3 est utilisé pour des expériences de reproduction d’articles, l’optimisation d’opérateurs CUDA et l’automatisation de processus d’entraînement de modèles, des tâches à long cycle qui démontrent la valeur combinée du contexte long, des capacités de codage, de l’appel d’outils et de la compréhension multimodale. Pour les applications d’IA en entreprise, cette combinaison de capacités signifie que le modèle peut simultanément lire des documents, comprendre des graphiques, analyser des journaux, générer du code et appeler des outils, étendant ainsi les limites des applications d’agent d’une « capacité ponctuelle » à une « exécution inter-étapes ».
Le lancement du MiniMax M3 reflète également l’évolution de la compétition des grands modèles en Chine, qui passe des simples paramètres de modèle, du prix et de l’expérience de dialogue général, vers des capacités plus proches des environnements de production, telles que le contexte long, l’exécution d’agents, l’ingénierie de code et la fusion multimodale. Alors que les entreprises intègrent les grands modèles dans leurs processus de R&D, d’exploitation, de service client, de bureautique et de gestion des connaissances, les fournisseurs de modèles doivent résoudre simultanément les problèmes de performance, de coût, de capacité de contexte, de stabilité et d’écosystème d’outils. L’investissement du MiniMax M3 dans le contexte d’un million de tokens et l’architecture MSA indique que les agents à longues tâches deviennent un nouveau point focal de la concurrence pour la commercialisation des grands modèles.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com











