

fr.wedoany.com Rapport : LinkedIn a lancé une plateforme d'intégration unifiée qui regroupe les pipelines de données de recrutement dispersés en une base cohérente et évolutive, visant à normaliser et harmoniser les données de recrutement issues de différents systèmes, améliorer la qualité des données, accélérer l'intégration des partenaires et soutenir les applications d'IA en aval. Cette plateforme résout les problèmes de schémas incohérents et d'enregistrements incomplets lors de l'ingestion de données provenant de sources telles que les systèmes de suivi des candidats, les sites d'emploi et les tableaux d'affichage, en introduisant un modèle de données unifié et une couche d'intégration.
Gaurav Sisodiya, responsable technique chez LinkedIn, a souligné dans un article qu'ils recherchent la coexistence plutôt que le remplacement. Un autre article technique indique que LinkedIn a développé cette plateforme d'intégration unifiée pour normaliser, harmoniser et fournir les données de recrutement à grande échelle. Selon LinkedIn, cette plateforme réduit de 72 % le temps d'intégration des partenaires, tout en élargissant la couverture des données et en améliorant leur exhaustivité. Les partenaires externes et les systèmes internes peuvent s'intégrer sans transformations personnalisées, et une infrastructure partagée remplace les pipelines auparavant isolés.
Sur le plan architectural, la plateforme se compose de trois couches : normalisation, orchestration et enrichissement. La couche de normalisation convertit les données provenant de sources hétérogènes en un schéma cohérent, en abstraisant les différences entre les divers systèmes de suivi des candidats et plateformes d'emploi. La couche d'orchestration gère les flux de travail pour l'ingestion, la validation et la coordination, en coordonnant les mouvements de données et en effectuant des contrôles de qualité. La couche d'enrichissement traite les données normalisées pour combler les lacunes, dédupliquer les enregistrements et renforcer les signaux, avant de les fournir aux systèmes en aval.
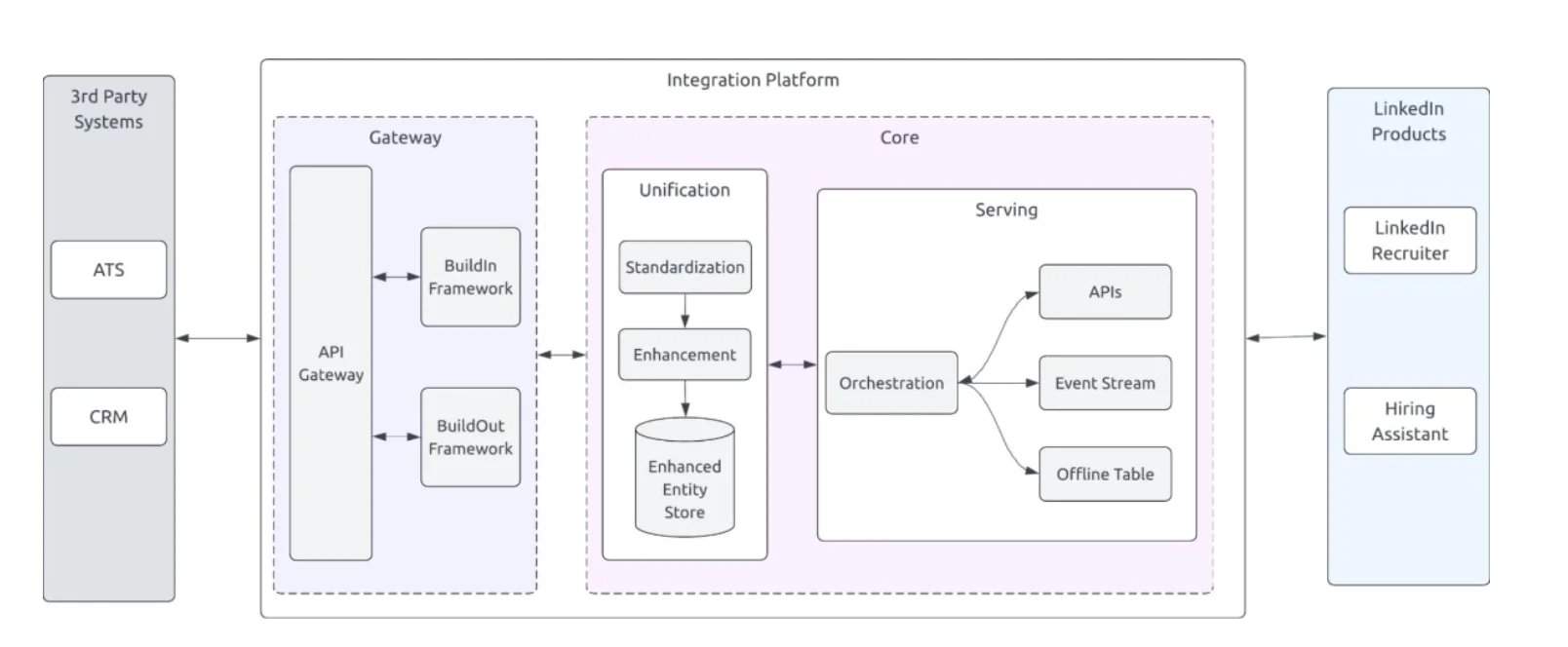
Aditya Hegde, ingénieur chez LinkedIn, a décrit dans un article les flux de travail sous-jacents : flux de travail orchestrés par Temporal, flux Kafka, persistance des enregistrements dans Espresso, orchestration multi-schémas et mappage déclaratif schéma/ID, permettant une rejouabilité, une synchronisation bidirectionnelle et une évolution sécurisée.
Cette base de données structurée permet aux ingénieurs de LinkedIn de construire des interfaces de perception et d'action pour l'assistant de recrutement. Les données de recrutement normalisées permettent aux systèmes d'IA d'interpréter les signaux des profils de candidats, des exigences de poste et des interactions des recruteurs, et d'agréger ces signaux en recommandations, automatisations et supports de décision dans les flux de travail des recruteurs. Ritvik Kar, responsable produit chez LinkedIn, a souligné que la fiabilité du système est cruciale, car les clients ont besoin de systèmes hautement fiables, observables et stables pour garantir une disponibilité élevée des données et une cohérence en lecture-écriture.
LinkedIn rapporte que la plateforme unifiée réduit la duplication des pipelines d'intégration et simplifie la maintenance grâce à un traitement centralisé des données. Cette approche améliore également la cohérence des données pour les analyses en aval et les systèmes d'IA, qui dépendent de données de recrutement partagées provenant de multiples sources.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com











