

fr.wedoany.com Rapport : Netflix a optimisé l’efficacité des requêtes de la base de données Apache Druid en introduisant une stratégie de cache basée sur les intervalles. Environ 84 % des résultats d’analyse proviennent désormais du cache, la charge des requêtes a été réduite d’environ 33 % et le temps de réponse P90 s’est amélioré de 66 %. Cette optimisation est principalement réalisée par une couche de cache proxy externe, qui résout les problèmes de calcul redondant et de balayage répété de grands ensembles de données causés par de légers décalages des plages temporelles lors des actualisations successives des requêtes sur les tableaux de bord à fenêtre glissante.
À l’échelle de Netflix, son système d’analyse en temps réel doit traiter des billions de lignes de données pour alimenter des tableaux de bord dédiés à la surveillance, aux expérimentations et aux décisions opérationnelles. Ces tableaux de bord exécutent fréquemment des requêtes quasi identiques, par exemple pour calculer les taux d’erreur ou les indicateurs d’engagement sur une fenêtre temporelle glissante. Evan King, cofondateur de Hello Interview, a souligné que le cache traditionnel traite les requêtes répétées ayant la même intention mais des limites temporelles légèrement décalées comme des requêtes différentes, ce qui entraîne un faible taux de réutilisation du cache et des calculs redondants dans Apache Druid.
L’approche de Netflix décompose les résultats des requêtes en segments alignés temporellement, afin de permettre leur réutilisation dans des requêtes à fenêtre glissante qui se chevauchent. Au lieu de mettre en cache la sortie complète d’une requête, le système stocke des agrégations intermédiaires sur des intervalles de temps fixes. Lorsqu’une nouvelle requête arrive, les segments mis en cache sont utilisés pour la partie historiquement stable de la fenêtre temporelle ; seules les données de l’intervalle le plus récent sont recalculées à partir de Druid, puis fusionnées avec les résultats en cache.
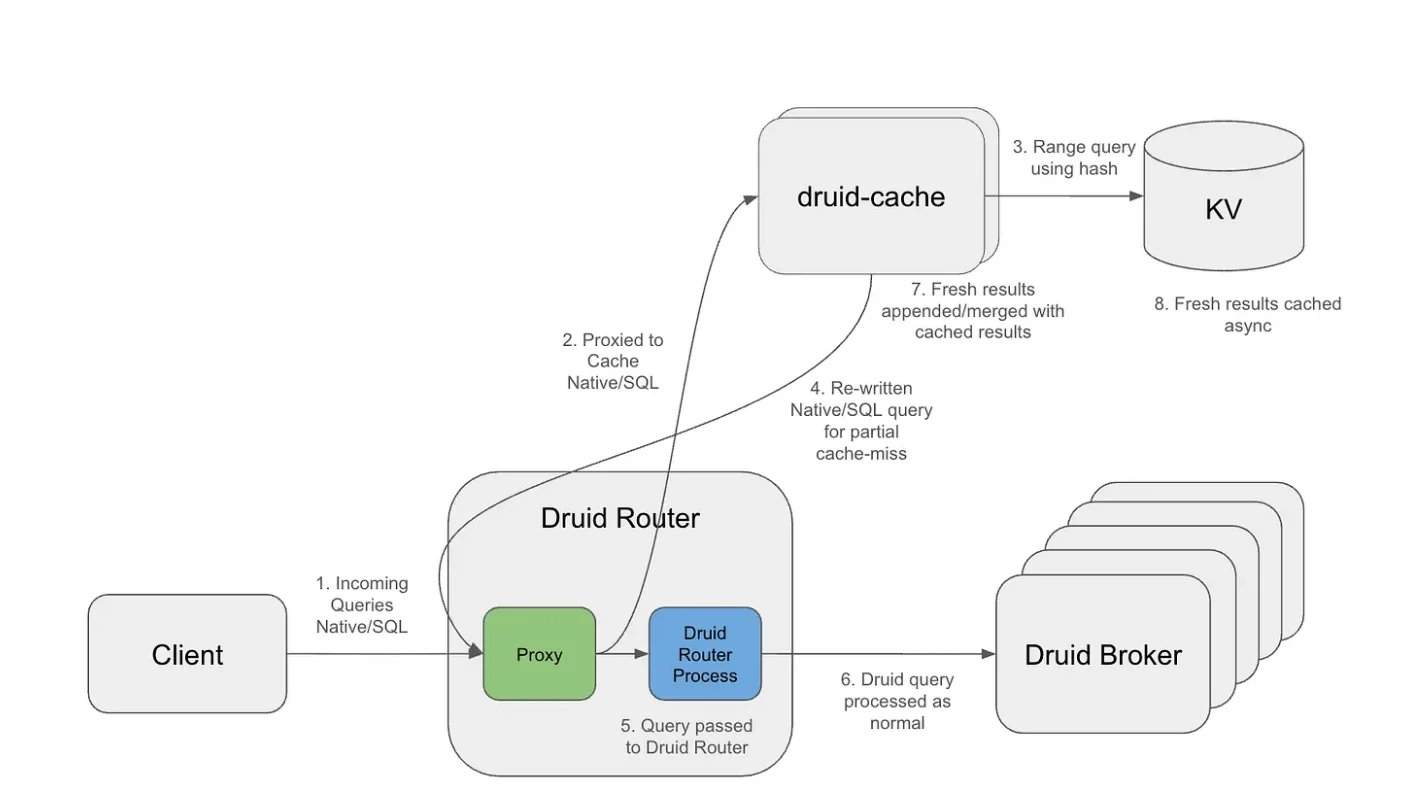
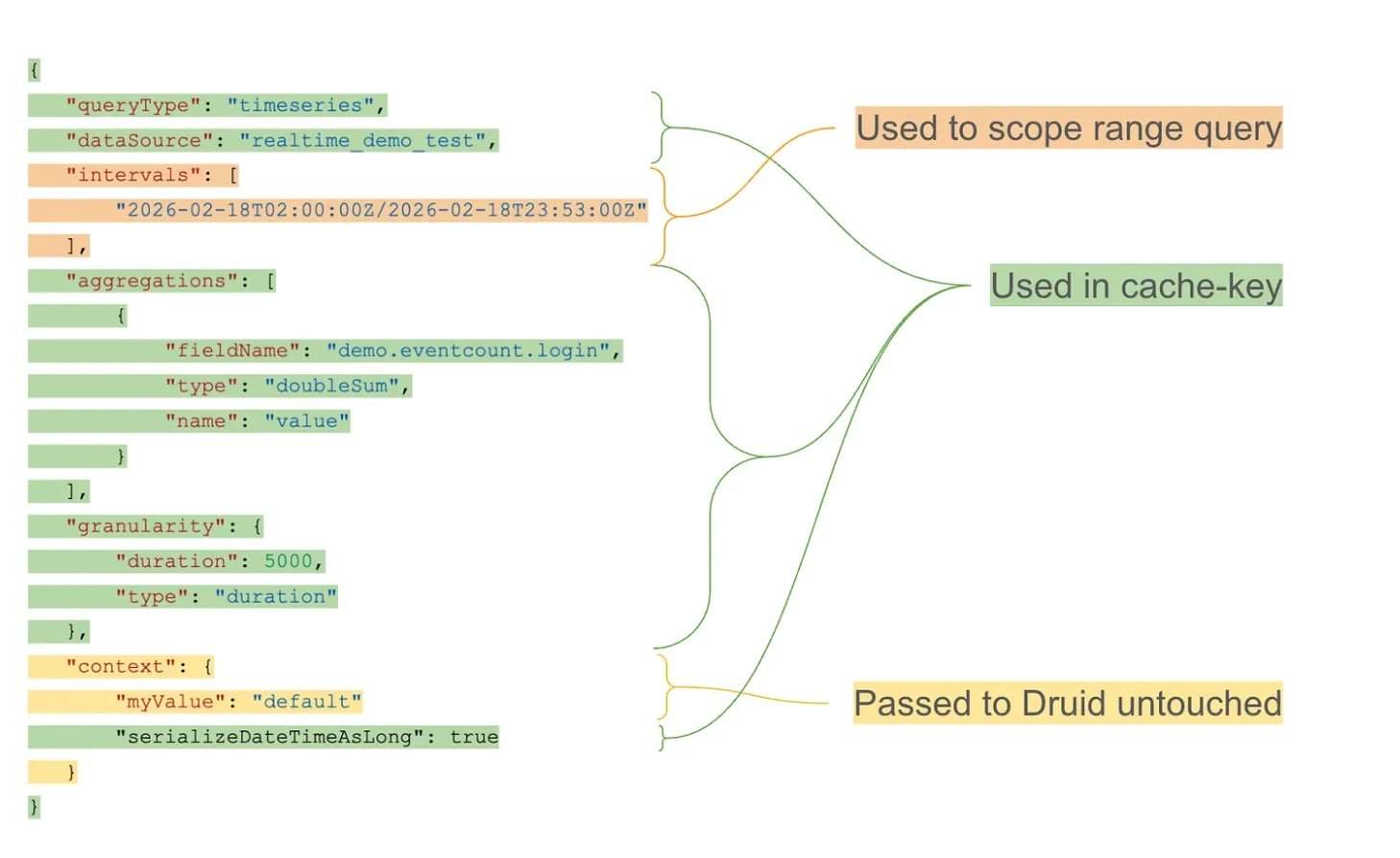
Avec une charge de travail de plus de 10 billions de lignes de données dans Apache Druid, les requêtes répétées à fenêtre glissante constituent le principal goulot d’étranglement. La couche de cache, grâce à l’utilisation de compartiments alignés sur la granularité et d’une stratégie de TTL (durée de vie) exponentielle, permet une mise en cache à long terme des intervalles historiques tout en maintenant l’actualité des données les plus récentes. Sur le plan architectural, la couche de cache fonctionne comme un proxy externe : elle intercepte les requêtes entrantes, sépare la structure de la requête de son intervalle temporel et génère des clés de cache réutilisables. Les segments de cache sont stockés dans un système de clés-valeurs distribué, prenant en charge une expiration indépendante et une récupération efficace.
Grâce à cette conception, seul l’intervalle le plus récent nécessite un recalcul, tandis que les segments historiques peuvent être réutilisés dans plusieurs requêtes qui se chevauchent. Par conséquent, la plage temporelle des opérations de requête atteignant Druid est considérablement réduite, le nombre de segments balayés est moindre et la quantité de données traitées est également réduite. Dans certaines charges de travail, Netflix a observé une réduction allant jusqu’à 14 fois du volume d’octets de résultats, ainsi qu’une diminution significative du balayage des segments.
Ce système est actuellement déployé en tant que couche expérimentale et continue d’évoluer. Les travaux futurs incluent l’extension du support aux requêtes SQL modélisées utilisées par les outils de tableau de bord, afin de réduire la dépendance aux expressions de requêtes natives de Druid. Netflix explore également l’intégration directe du cache basé sur les intervalles dans Apache Druid, pour éliminer le besoin d’une couche proxy externe et améliorer l’efficacité de la planification des requêtes.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com











