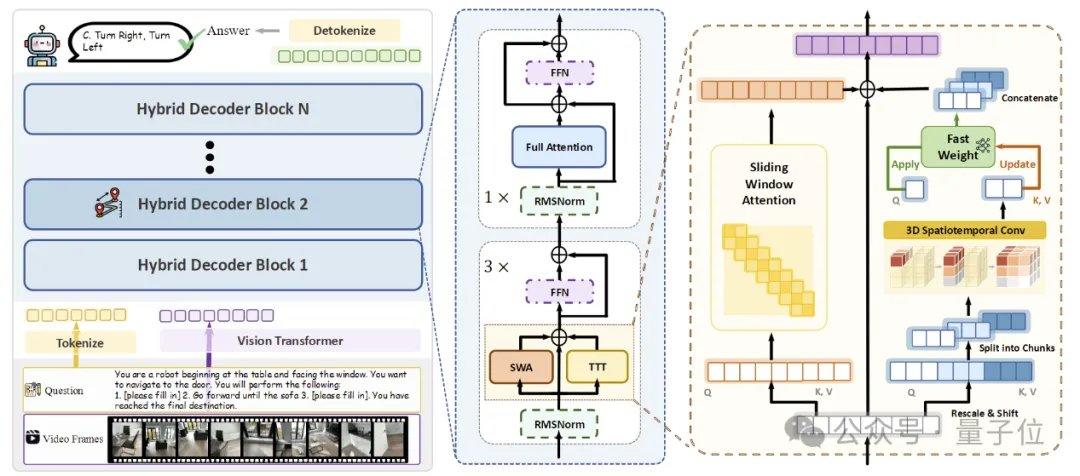
fr.wedoany.com Rapport : Réalisée par Liu Fangfu, doctorant à l’Université Tsinghua, en tant que premier auteur, en collaboration avec plusieurs chercheurs, l’étude Spatial-TTT sur l’intelligence spatiale multimodale a récemment été officiellement acceptée par ECCV 2026, une conférence de premier plan en vision par ordinateur. Ce travail se concentre sur la résolution du problème de l’intelligence spatiale en flux continu des grands modèles multimodaux dans le monde physique réel, c’est-à-dire comment le modèle forme et met à jour en continu une mémoire spatiale dans un flux vidéo en constante évolution, plutôt que de traiter chaque entrée comme un segment indépendant.
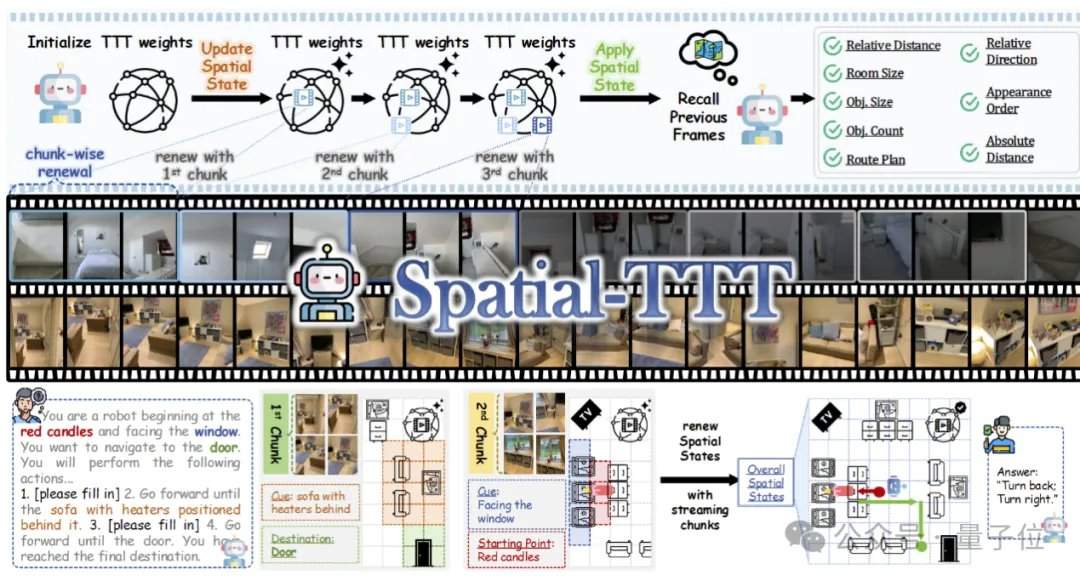
Des scénarios réels tels que la navigation robotique, la conduite autonome et la réalité augmentée exigent des modèles des capacités bien supérieures à la simple compréhension d’images statiques. Les méthodes traditionnelles, confrontées à des flux vidéo longs de plusieurs dizaines de minutes, voire plusieurs heures, souffrent d’une fragmentation de la compréhension spatiale en raison de l’absence d’un mécanisme efficace de mise à jour de la mémoire en ligne. Spatial-TTT a été proposé précisément pour relever ce défi, en introduisant le concept de test-time training (TTT) dans le domaine de l’intelligence spatiale, permettant au modèle de mettre à jour ses paramètres internes tout en visionnant la vidéo pendant le processus d’inférence.
Pour réaliser une mémoire spatiale en flux efficace, l’équipe de recherche a proposé trois technologies clés. La première est une architecture TTT hybride, qui insère en alternance des couches TTT et des couches d’ancrage d’auto-attention standard dans le décodeur selon un ratio de 3:1. Les premières sont responsables de l’écriture des informations à longue portée dans des poids rapides, tandis que les secondes maintiennent la capacité d’alignement intermodal et de raisonnement sémantique du modèle pré-entraîné. La deuxième est un mécanisme de prédiction spatiale, qui introduit des convolutions spatio-temporelles 3D légères dans la branche TTT, permettant au modèle d’apprendre les relations de prédiction entre les contextes spatio-temporels et d’améliorer la stabilité des mises à jour en ligne. La troisième est une supervision dense par description de scène, qui, en construisant des données de description de scène couvrant le contexte global, les catégories d’objets et les relations spatiales, entraîne le modèle à passer d’une « réponse locale » à une « maintenance d’une mémoire 3D globale ».
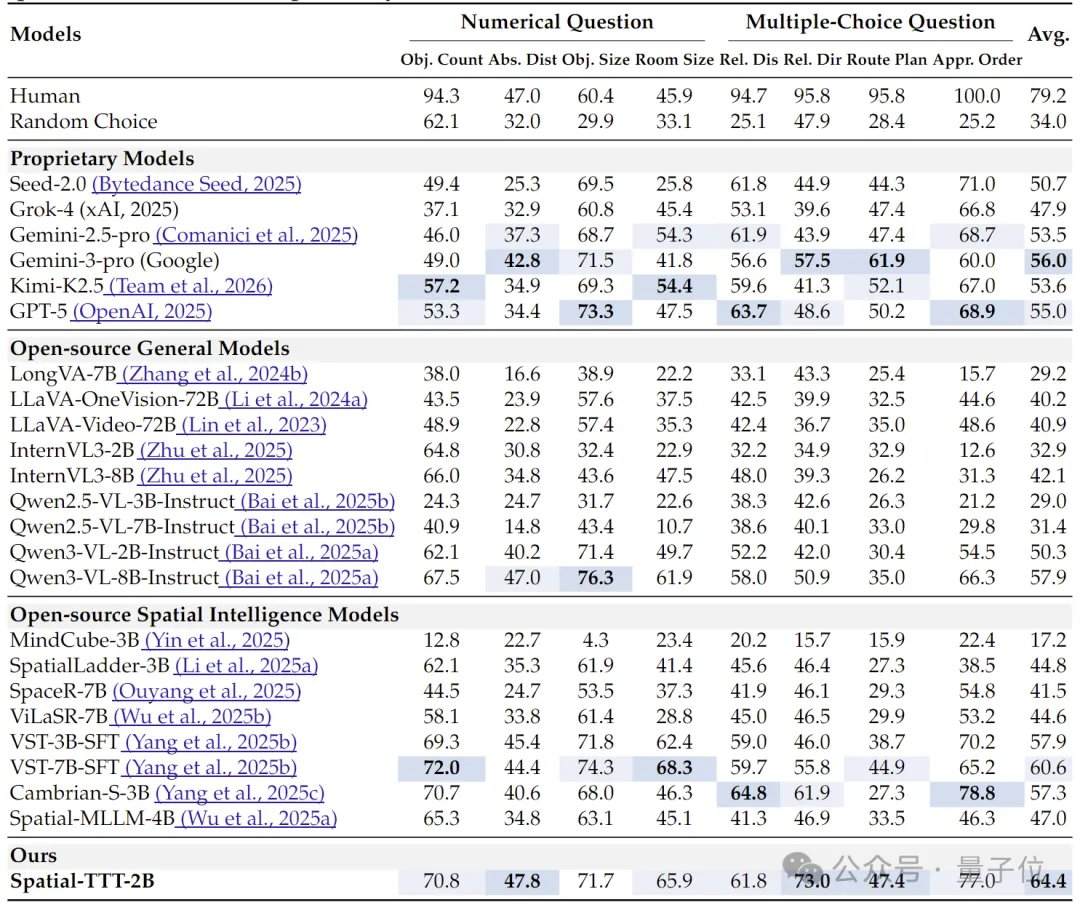
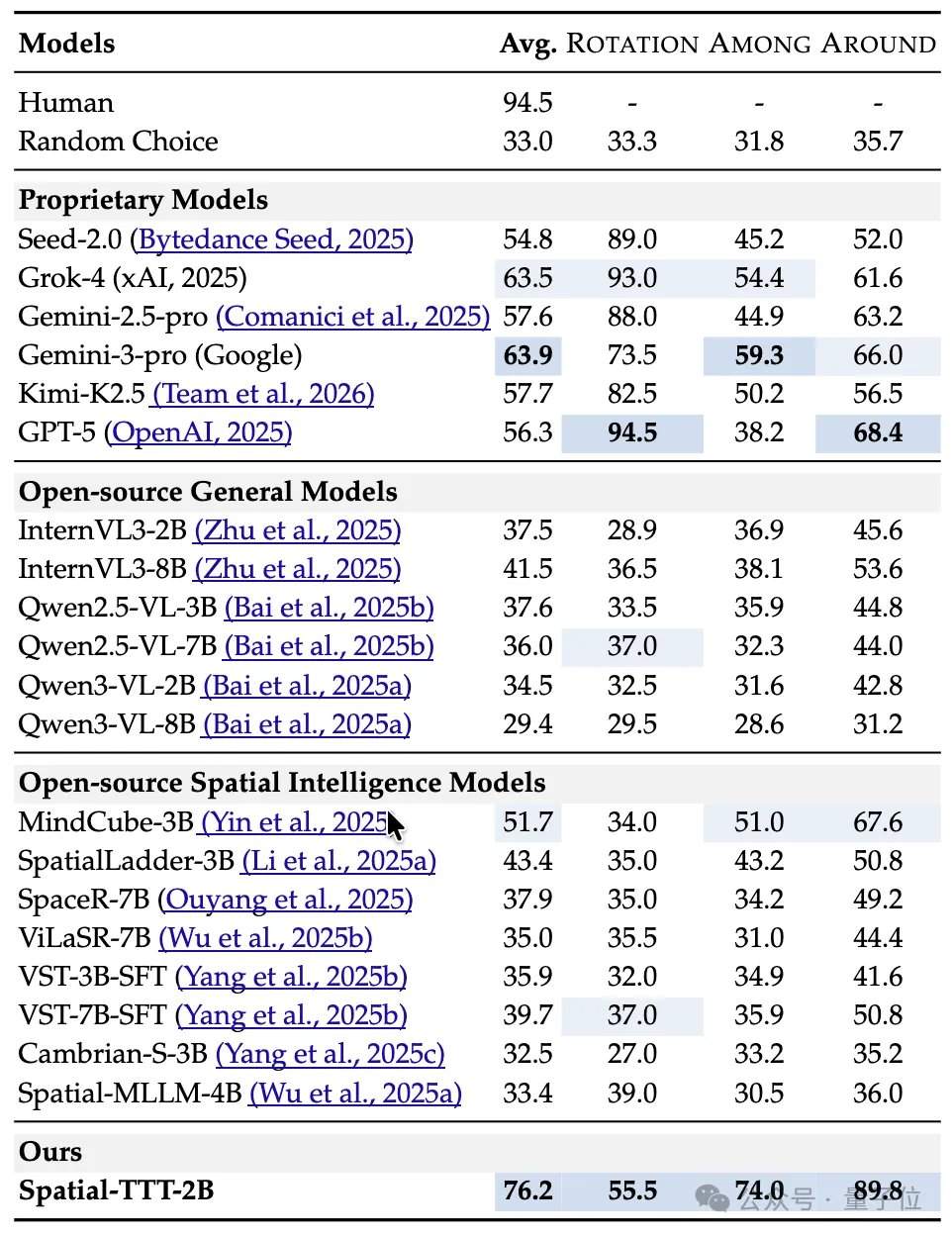
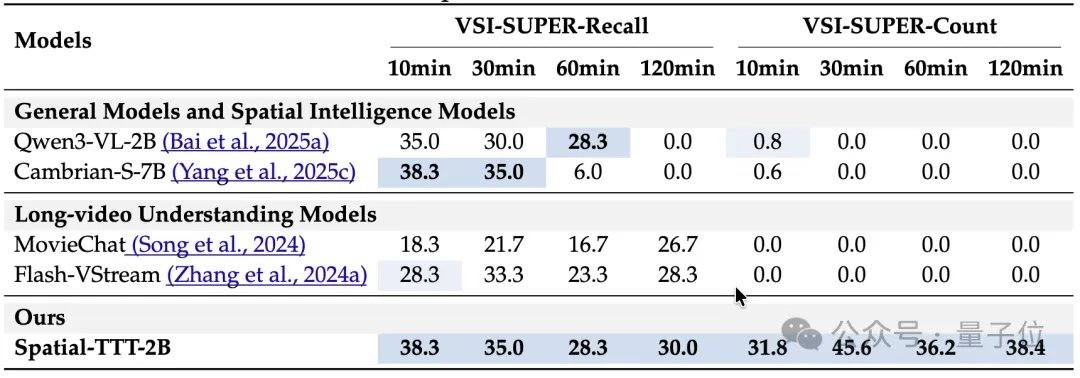
En termes de résultats expérimentaux, Spatial-TTT, avec seulement 2 milliards de paramètres, a montré des avantages significatifs sur plusieurs benchmarks spécialisés d’intelligence spatiale. Sur VSI-Bench, son score moyen a atteint 64,4, surpassant des modèles propriétaires tels que GPT-5 et Gemini-3-pro. Sur le benchmark MindCube-Tiny, qui teste davantage le raisonnement spatial fin multi-vues, Spatial-TTT a obtenu une précision de 76,2 %, soit 12 points de pourcentage de plus que Gemini-3-pro (63,9 %) et près de 25 points de pourcentage de plus que le modèle spatial open-source représentatif MindCube-3B (51,7 %). Dans les tâches de la série VSI-SUPER, qui testent la mémoire à long terme, le modèle a pu traiter de manière stable des flux vidéo allant jusqu’à 120 minutes. Sur la tâche VSI-SUPER-Count, les scores de Spatial-TTT sur des vidéos de 10, 30, 60 et 120 minutes ont respectivement atteint 31,8, 45,6, 36,2 et 38,4.
L’analyse de l’efficacité montre qu’avec une entrée de 1024 images, l’occupation maximale de la mémoire GPU de Spatial-TTT-2B est de 11,9 Go, avec une charge de calcul théorique de 799,4 TFLOPs, réalisant une économie de plus de 40 % en mémoire et en ressources de calcul par rapport aux modèles de base de pointe du secteur. Les expériences d’ablation confirment en outre que l’amélioration des performances provient de l’effet synergique entre l’architecture hybride, le mécanisme de prédiction spatiale et les signaux de supervision denses. Plus précisément : en supprimant le mécanisme de prédiction spatiale, le score moyen sur VSI-Bench passe de 64,4 à 62,1 ; en supprimant la supervision dense par description de scène, il tombe à 61,3 ; si l’architecture hybride est complètement supprimée et que seule la structure TTT pure est utilisée, le score moyen chute directement à 53,9.
Cette étude, sélectionnée pour ECCV 2026, offre une nouvelle voie technologique pour les systèmes d’intelligence artificielle physique nécessitant un fonctionnement continu à long terme. En permettant au modèle d’accumuler, de corriger et d’exploiter en continu les informations spatiales, les agents intelligents futurs ne seront plus confrontés à des images fragmentées image par image, mais pourront construire un modèle du monde interne, continu, compréhensible et dans lequel ils pourront agir.
Lien vers l’article : https://arxiv.org/pdf/2603.12255
Page du projet : https://liuff19.github.io/Spatial-TTT/
GitHub : https://github.com/THU-SI/Spatial-TTT/
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com