fr.wedoany.com Rapport : Des chercheurs du Laboratoire d’intelligence artificielle de Shanghai (Shanghai Artificial Intelligence Laboratory) ont proposé un nouveau paradigme appelé « Self-Harness », qui permet aux agents basés sur les grands modèles de langage (LLM) d’améliorer systématiquement leurs propres règles de fonctionnement, sans dépendre d’ingénieurs humains ni de modèles externes plus puissants.
Les performances des agents basés sur les LLM ne dépendent pas seulement du modèle de base, mais aussi de leur cadre, qui inclut les invites système, les outils, la mémoire, les règles de validation, les stratégies d’exécution, la logique d’orchestration et les procédures de reprise après panne. Les défaillances courantes des agents proviennent souvent du cadre plutôt que du modèle lui-même. Par exemple, un agent peut signaler un succès sans vérifier la réponse du modèle, ou répéter inlassablement une opération échouée. SWE-agent, Claude Code, Codex et OpenHands sont des exemples de cadres populaires.
Hangfan Zhang, premier auteur de l’article sur Self-Harness, indique que le véritable goulot d’étranglement de l’ingénierie manuelle des cadres réside dans la dépendance au débogage ponctuel, plutôt qu’à une boucle de rétroaction systématique. De nombreuses modifications sont basées sur l’intuition ou sur un petit nombre de cas d’échec, ce qui rend difficile de suivre le rythme rapide de l’évolution des LLM. Le paradigme Self-Harness permet aux agents basés sur les LLM de s’auto-évoluer grâce à un cycle itératif en trois phases.
Ce cycle commence par une phase de détection des faiblesses : l’agent exécute des tâches pour générer des traces d’exécution, classifie les traces d’échec et détecte les schémas de défaillance spécifiques au modèle. Vient ensuite la phase de proposition de cadre : l’agent utilise un rôle de « proposeur » pour générer un ensemble diversifié et minimal de modifications du cadre, chacune ciblant un mécanisme de défaillance spécifique. Enfin, la phase de validation des propositions : le système évalue les modifications candidates par des tests de régression, et ne les adopte que si les modifications n’entraînent pas une baisse des performances sur les tâches conservées. Si plusieurs candidats réussissent les tests, ils sont fusionnés dans la version suivante du cadre.
Les chercheurs ont évalué Self-Harness sur le benchmark Terminal-Bench-2.0, qui teste l’exécution basée sur des outils, y compris la gestion des artefacts, l’utilisation des commandes, le comportement de validation et la récupération après des erreurs d’exécution. Ils ont appliqué Self-Harness à MiniMax M2.5, Qwen3.5-35B-A3B et GLM-5. Les résultats quantitatifs montrent que les agents ont amélioré leurs performances grâce à des modifications automatisées du cadre, avec des améliorations relatives allant de 33 % à 60 % selon les modèles sur les tâches conservées.
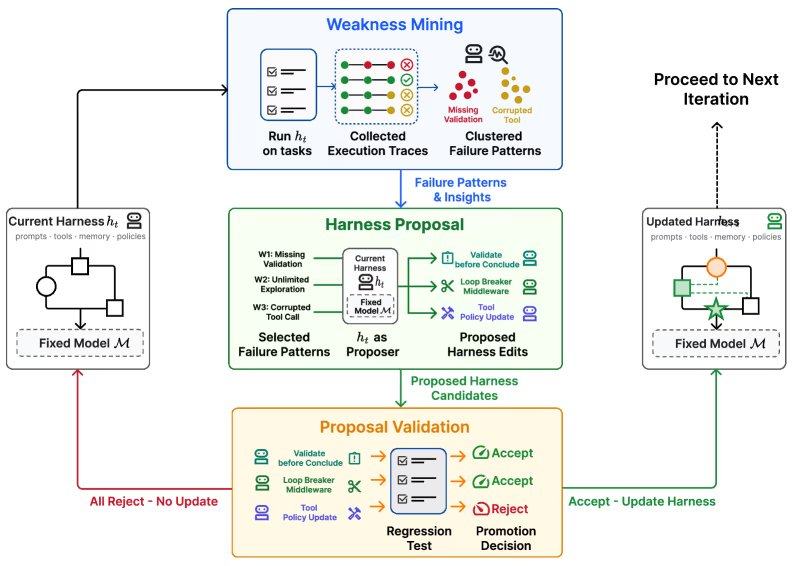
Les expériences montrent que Self-Harness introduit des changements ciblés, reflétant les problèmes récurrents de chaque modèle lors de l’exécution. Par exemple, MiniMax M2.5, sous le cadre de base, explorait sans fin la configuration des données jusqu’à expiration du délai ; le système a corrigé cela en écrivant une règle « d’interruption de boucle » (arrêt après 50 appels d’outils et redirection de la méthode) et en ajoutant l’exigence de créer une version initiale le plus tôt possible. Qwen-3.5 répétait la même commande après une erreur d’écrasement de fichier ; le système a introduit une discipline de réessai stricte (interdiction de répéter complètement la commande) ainsi qu’un mécanisme de recréation immédiate des artefacts perdus après une erreur de fichier. GLM-5 avait du mal à maintenir les changements d’environnement entre différentes commandes ; son cadre auto-généré a introduit des règles telles que la persistance de la variable PATH, la limitation des calculs externes et la réparation de tout test de cohérence échoué avant la fin de l’exécution.
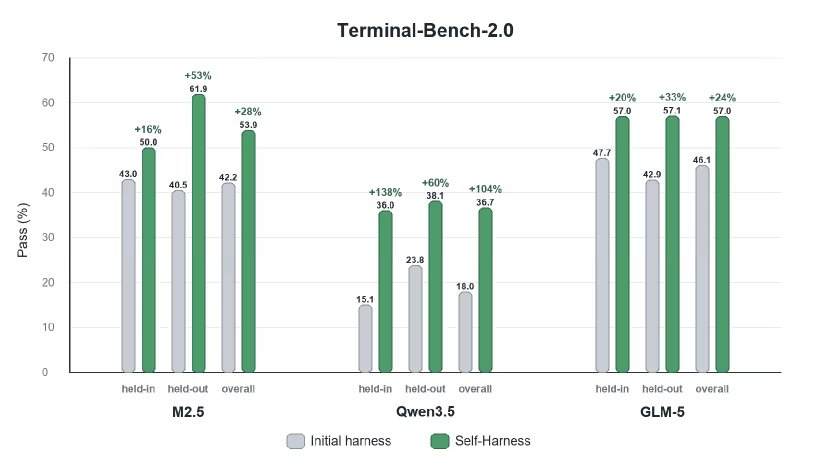
Zhang souligne que l’ingénierie automatisée des cadres nécessite des coûts de calcul pour la génération répétée, l’évaluation parallèle et les tests de régression. Le système dépend également de la précision du pipeline d’évaluation, en s’appuyant dans les expériences sur des validateurs stricts et déterministes. Il estime que les meilleurs domaines de déploiement sont ceux où les échecs sont mesurables et les essais-erreurs relativement sûrs, comme le codage, l’automatisation des flux de travail internes et les pipelines de données DevOps. En revanche, les domaines où l’évaluation est subjective et coûteuse, comme les décisions médicales, les infrastructures critiques pour la sécurité ou les décisions juridiques, devraient éviter une automatisation complète. À mesure que les capacités des modèles de base augmentent, les cadres s’étendront vers l’extérieur, se connectant à des environnements externes plus riches. Le rôle des ingénieurs passera de la correction manuelle d’invites ou d’appels d’outils individuels à la conception de systèmes de rétroaction permettant l’amélioration des agents.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com