
fr.wedoany.com Rapport : Baidu a publié en open source le 22 juin son modèle Unlimited OCR, visant à résoudre le problème de ralentissement progressif des modèles OCR de bout en bout lors de l'analyse de longs documents. Ce modèle compte un total de 3 milliards de paramètres, mais n'en active que 500 millions lors de l'inférence.
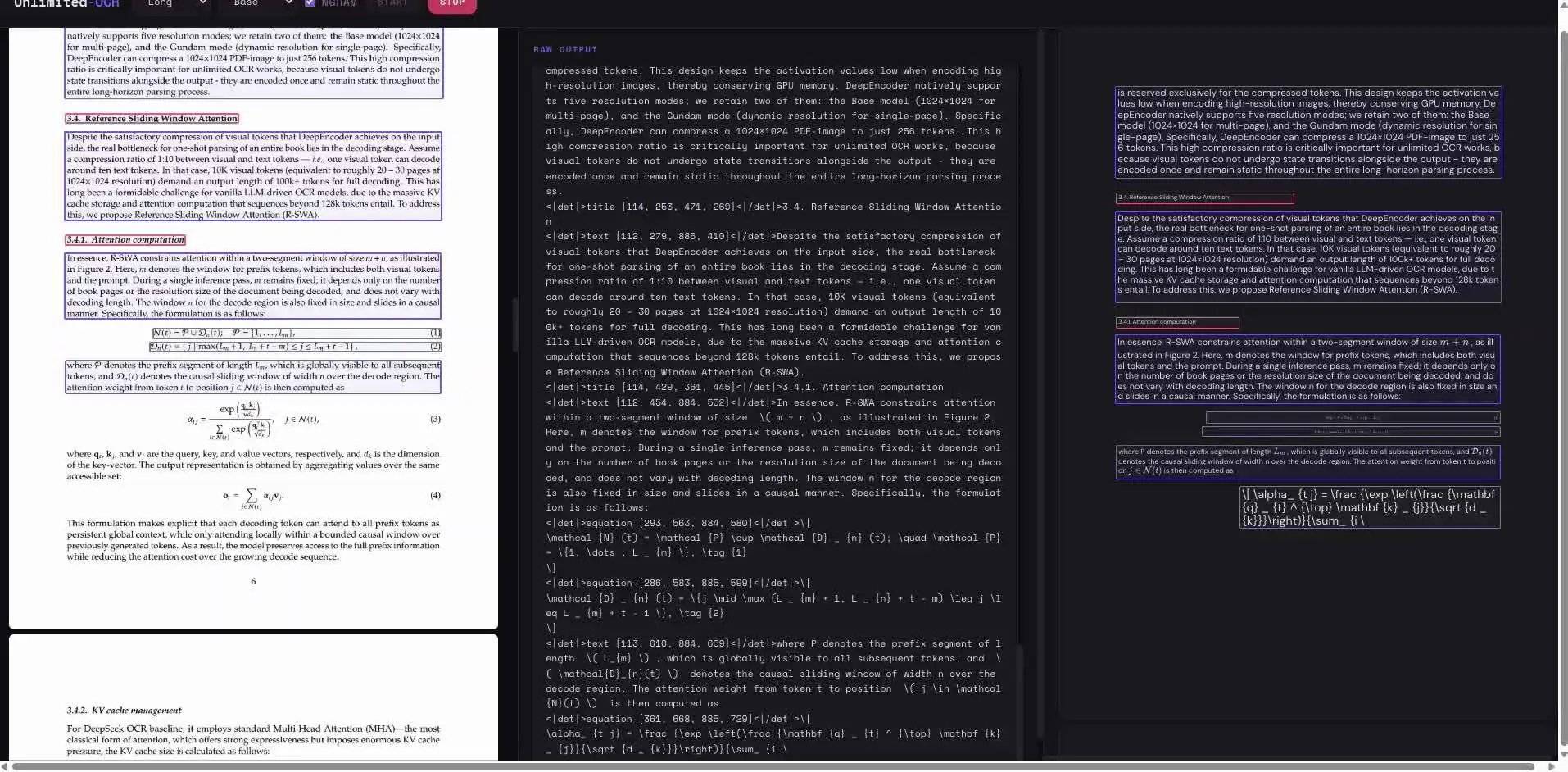
Les modèles OCR de bout en bout utilisent une architecture de réseau neuronal unifiée, fusionnant la détection de texte et la reconnaissance de caractères en un seul système, qui mappe directement l'image d'entrée à une séquence de texte de sortie, abandonnant ainsi le processus traditionnel de détection préalable des zones de texte suivi d'une reconnaissance séparée. Chaque token généré par un modèle OCR de bout en bout dominant augmente le cache de clés-valeurs (KV cache), ce qui entraîne une hausse continue de l'utilisation de la mémoire et de la latence, donnant à l'utilisateur l'impression que l'analyse de documents multipages ralentit au fur et à mesure.
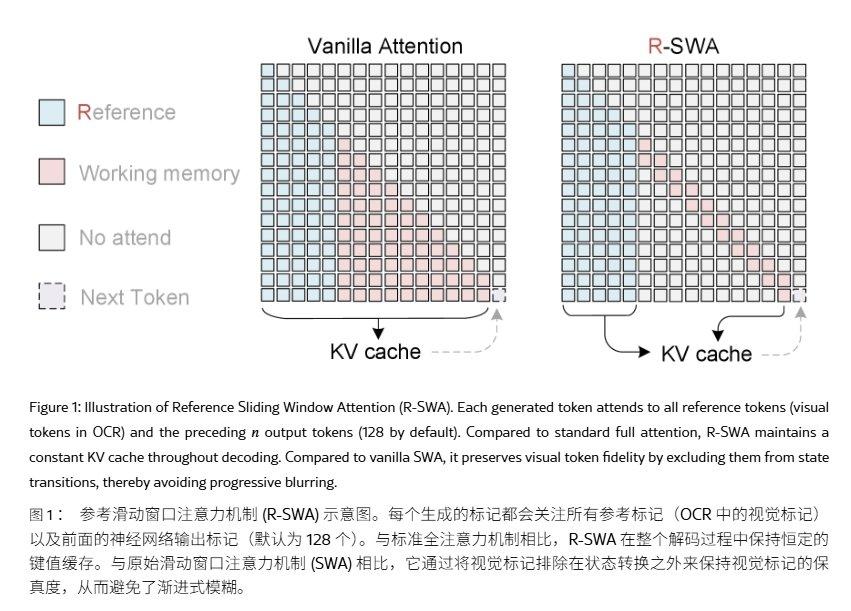
Unlimited OCR reprend l'architecture de DeepSeek OCR, en conservant le DeepEncoder et le décodeur à experts mixtes (MoE). Le côté encodeur utilise un codage visuel à deux niveaux, avec une compression de tokens par un facteur 16 lors de la phase de connexion, compressant une image PDF de 1024×1024 en 256 tokens visuels, réduisant ainsi la charge de préremplissage dès la source.
En termes d'entraînement, Unlimited OCR a poursuivi l'apprentissage à partir du point de contrôle de DeepSeek OCR pendant 4000 étapes, en gelant le DeepEncoder et en n'entraînant que le décodeur. Les données d'entraînement comprennent environ 2 millions d'échantillons de documents, exécutés sur 8×16 GPU A800. Le ratio de données est d'environ 9:1 entre pages uniques et pages multiples, ces dernières étant obtenues par concaténation.
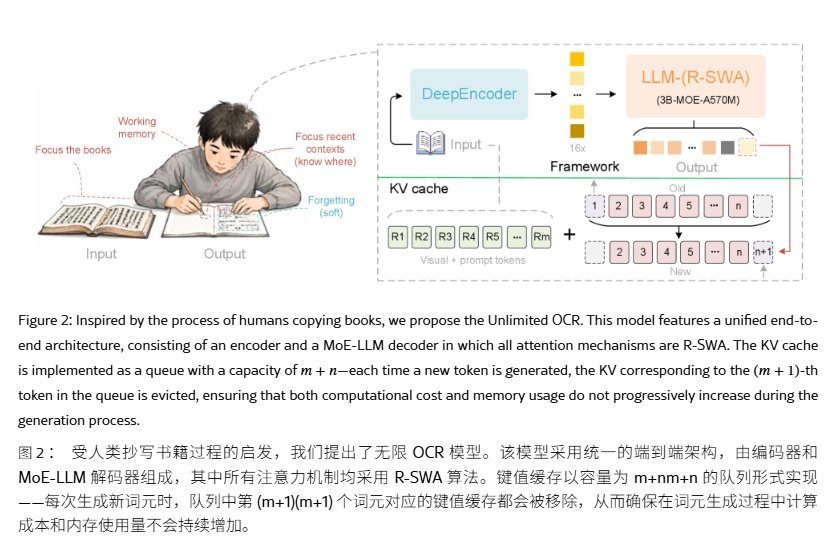
Les tests de référence montrent qu'Unlimited OCR obtient un score global de 93,23 sur OmniDocBench v1.5, supérieur aux 87,01 de DeepSeek OCR et aux 89,17 de DeepSeek OCR 2. Sa distance d'édition de texte est de 0,038, son CDM de formules de 92,61, son TEDS de tableaux de 90,93, et sa distance d'édition d'ordre de lecture de 0,045. Sur OmniDocBench v1.6, le score global du modèle atteint 93,92.











