
fr.wedoany.com Rapport : L'entreprise chinoise d'IA DeepSeek, en collaboration avec l'Université de Pékin, a publié le 27 juin le framework d'accélération d'inférence DSpark, proposant une nouvelle méthode pour faire face au goulot d'étranglement de l'efficacité d'inférence dans les services à forte concurrence des grands modèles. Ce framework, basé sur l'orientation du décodage spéculatif, améliore la qualité des tokens de brouillon grâce à une structure de génération semi-autorégressive et un mécanisme de vérification dynamique basé sur la confiance, réduisant ainsi les calculs de vérification inefficaces. Dans le système de service en ligne DeepSeek-V4, DSpark augmente la vitesse d'inférence d'environ 60 % à 85 % par rapport au modèle de référence et réduit la perte de débit dans les scénarios à forte concurrence.
Le décodage spéculatif est l'une des voies importantes pour accélérer l'inférence des grands modèles. Lors de la génération de texte par un grand modèle, il est généralement nécessaire de prédire les tokens un par un : le token suivant ne peut être calculé qu'après la génération du token précédent. Cette approche autorégressive assure la cohérence contextuelle, mais rend également le processus d'inférence difficile à paralléliser complètement. L'idée du décodage spéculatif est de laisser d'abord un modèle de brouillon plus léger générer plusieurs tokens candidats à l'avance, puis de les faire vérifier par le grand modèle cible ; si les tokens candidats sont acceptés, plusieurs étapes de génération peuvent être avancées en une seule fois, augmentant ainsi la vitesse de sortie globale.
Le problème est que, bien que la méthode actuelle de génération parallèle de brouillons puisse générer des blocs de tokens plus longs en une seule fois, la corrélation entre les tokens est insuffisante, ce qui fait que les tokens suivants s'écartent plus facilement de la distribution du modèle cible, augmentant ainsi le taux de rejet. Les tokens de brouillon rejetés non seulement n'accélèrent pas le processus, mais consomment également de la puissance de calcul pour la vérification, créant un gaspillage de calcul supplémentaire, en particulier dans les services en ligne à forte concurrence. Pour résoudre ce problème, DSpark ajoute un module séquentiel léger à la structure de génération parallèle, renforçant la dépendance entre les tokens de brouillon et augmentant la longueur acceptable des séquences candidates.
La structure semi-autorégressive est la conception centrale de DSpark. Elle ne revient pas complètement à une autorégression token par token, ni ne génère simplement l'ensemble du bloc de brouillon en une seule fois en parallèle, mais fait un compromis entre l'efficacité parallèle et la dépendance séquentielle. Le squelette parallèle est responsable de la génération rapide des blocs candidats, tandis que le module séquentiel léger complète la relation contextuelle entre les tokens adjacents, rapprochant ainsi le modèle de brouillon du chemin de génération du modèle cible. De cette manière, le modèle cible accepte plus facilement les tokens continus lors de la phase de vérification, permettant à une seule vérification de progresser sur une plus longue distance de génération.
Un autre mécanisme clé de DSpark est la vérification dynamique basée sur la confiance. La probabilité de succès des brouillons varie selon les requêtes, les contextes et les positions de génération. Si le système fixe une longueur de vérification constante, il gaspillera des calculs sur certaines requêtes à faible taux de succès et pourrait ne pas exploiter pleinement les brouillons acceptables sur les requêtes à haut taux de succès. DSpark ajuste de manière adaptative la longueur de vérification en fonction de la probabilité de succès de la requête et de la charge du système, évitant ainsi les situations où l'on vérifie des brouillons trop longs malgré un faible taux d'acceptation, et permettant une répartition plus raisonnable de la puissance de calcul lorsque la charge est élevée.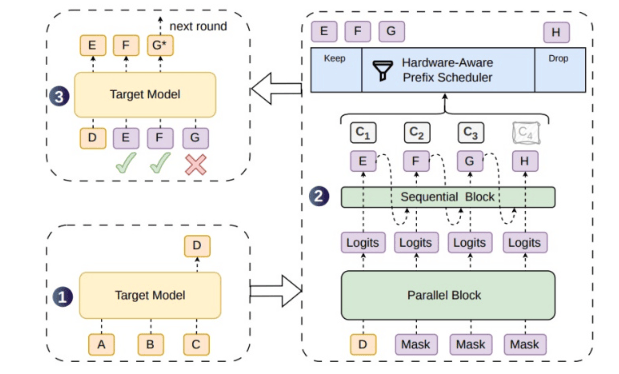
Ce mécanisme est particulièrement important pour les environnements de production en ligne. Les environnements de test hors ligne ont généralement des requêtes plus contrôlables et une pression de concurrence plus faible, mais les services réels de grands modèles doivent faire face simultanément à un grand nombre de requêtes utilisateurs, avec des longueurs d'entrée, des types de tâches, des styles de sortie et des difficultés de génération variables. Un framework d'accélération d'inférence qui ne serait efficace que dans des expériences à petite échelle aurait du mal à soutenir un déploiement commercial. L'augmentation de 60 % à 85 % de la vitesse d'inférence obtenue par DSpark dans le système en ligne DeepSeek-V4 montre que sa conception a été validée face à la pression réelle des services, et non simplement optimisée pour des indicateurs de laboratoire.
DSpark améliore également le débit en cas de forte concurrence en augmentant la longueur de génération acceptable. Le coût des services de grands modèles ne provient pas seulement de la latence des requêtes individuelles, mais aussi de la capacité de débit totale des clusters GPU sous forte charge. Plus la qualité des brouillons est élevée, plus le nombre de tokens vérifiés en une seule fois par le modèle cible est important, et plus la production effective par unité de ressource de calcul est élevée. Pour les services API, les systèmes d'agents, la génération de code, les questions-réponses de recherche et les applications d'IA d'entreprise, une baisse du coût d'inférence signifie que la même puissance de calcul peut servir plus de requêtes, ou fournir des temps de réponse plus rapides à coût égal.
DeepSeek a également open-sourcé les points de contrôle du modèle et le framework d'entraînement DeepSpec, fournissant à la communauté une chaîne d'outils complète pour continuer à rechercher des algorithmes de décodage spéculatif. DeepSpec comprend l'entraînement des modèles de brouillon, la préparation des données, des scripts d'évaluation et diverses implémentations d'algorithmes, prenant en charge l'entraînement et la comparaison de modèles de brouillon tels que DSpark, DFlash et Eagle3. L'importance de l'open-source réside dans le fait que les développeurs et institutions de recherche externes peuvent reproduire, ajuster et évaluer ces modèles sur différents modèles cibles, données de tâches et scénarios de service, faisant ainsi passer le décodage spéculatif d'un algorithme ponctuel à un outil d'ingénierie.
Ce résultat reflète également le fait que la concurrence autour des grands modèles s'étend de la taille des paramètres du modèle à l'efficacité de l'ingénierie d'inférence. La capacité du modèle détermine la limite supérieure du service, tandis que la vitesse d'inférence et le coût unitaire déterminent la vitesse de commercialisation. Alors que les applications d'entreprise, les agents, les assistants de programmation et les systèmes multimodaux entrent dans une phase d'utilisation à haute fréquence, les utilisateurs exigent non seulement que le modèle « réponde bien », mais aussi qu'il « réponde vite, à faible coût et de manière stable en cas de concurrence ». Ce que DSpark résout est précisément le problème fondamental d'efficacité auquel les grands modèles sont confrontés lorsqu'ils entrent dans des services en ligne à grande échelle.
Les points d'intérêt futurs se concentrent sur trois aspects : premièrement, si DSpark peut maintenir une accélération stable sur davantage d'architectures de modèles et de types de tâches ; deuxièmement, si le mécanisme de vérification dynamique peut continuer à réduire les calculs inefficaces dans des environnements à très forte concurrence ; troisièmement, après l'open-source de DeepSpec, si la communauté développera davantage de modèles de brouillon spécialisés pour le code, les mathématiques, les textes longs et les tâches d'agents basés sur DSpark. Alors que le coût du côté de l'inférence devient une variable clé de la commercialisation des grands modèles, les frameworks d'accélération d'inférence comme DSpark deviendront une partie importante de la concurrence dans les infrastructures d'IA.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com









