
fr.wedoany.com Rapport : Le modèle GLM-5.2 développé par l’entreprise chinoise d’intelligence artificielle Z.ai affiche des performances comparables à celles du modèle phare Mythos d’Anthropic en matière d’identification des vulnérabilités de sécurité logicielle.

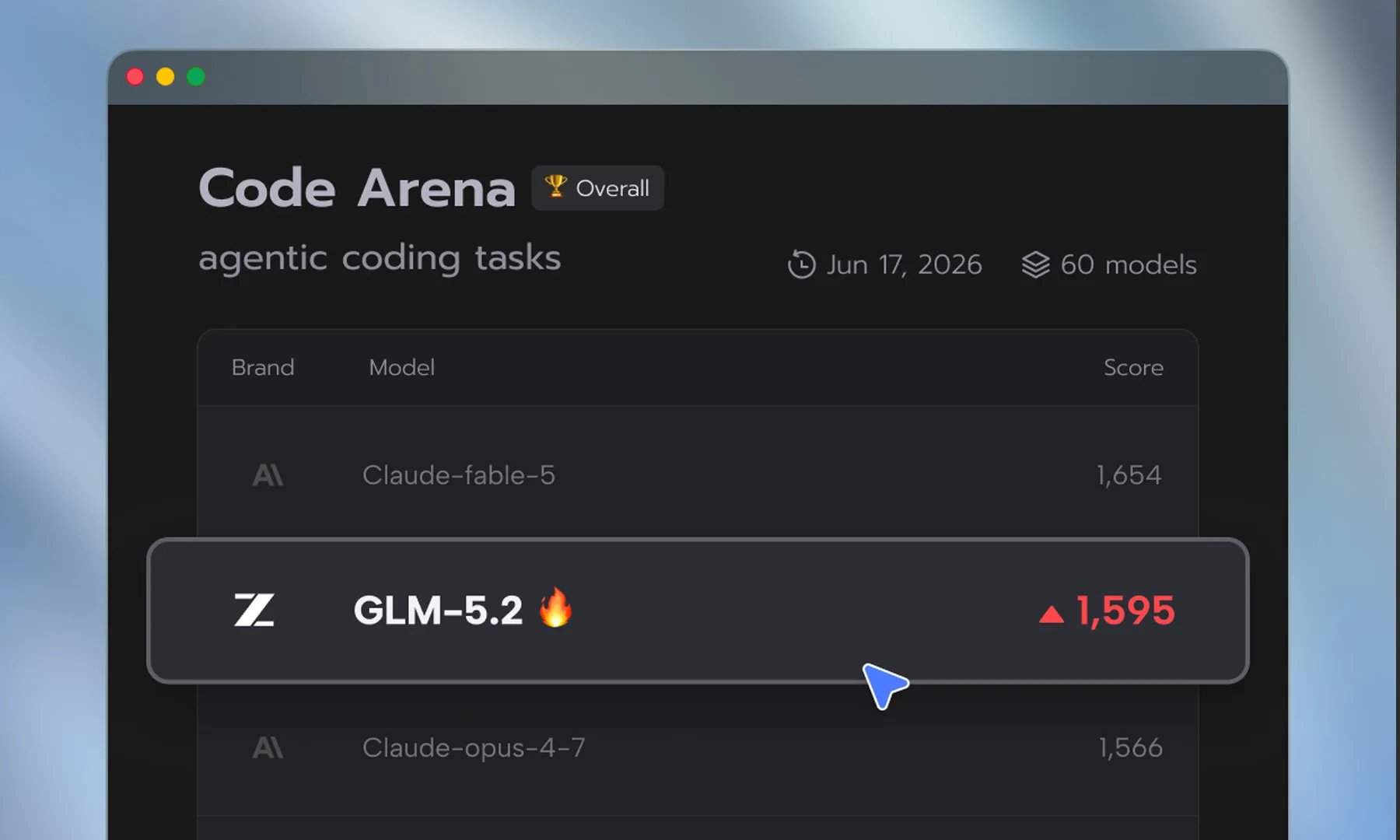
Selon un rapport du *Wall Street Journal*, des chercheurs en sécurité ont découvert que le GLM-5.2 affiche des performances équivalentes à celles du Mythos dans l’identification des vulnérabilités logicielles. Cette capacité est cruciale dans la course des entreprises à corriger les failles avant que les pirates ne les exploitent. Le rapport indique également que le GLM-5.2 reste en retrait des modèles d’Anthropic et d’OpenAI dans les tâches de raisonnement général plus larges, mais que l’écart s’est considérablement réduit dans le domaine de la cybersécurité. Selon les données de référence citées, le GLM-5.2 a déjà surpassé le Claude Opus 4.8 dans certaines évaluations de sécurité.
Le statut open source du GLM-5.2 constitue un facteur de différenciation clé. Tout utilisateur peut télécharger, modifier et exécuter le modèle sur son propre matériel, sans dépendre d’un fournisseur de services cloud. Cette flexibilité séduit les entreprises, mais suscite également des inquiétudes quant à son utilisation potentielle par des cybercriminels à des fins malveillantes.
Cette avancée intervient à un moment crucial pour le secteur américain de l’IA. Alors que des entreprises comme Anthropic et OpenAI limitent l’accès à leurs modèles de pointe les plus avancés pour des raisons de sécurité nationale, les laboratoires chinois d’IA publient des modèles open source de plus en plus puissants. Le débat sur la rapidité du rattrapage chinois est désormais public. Elon Musk avait précédemment prédit que les laboratoires chinois d’IA rattraperaient le modèle phare Fable 5 d’Anthropic, au moins en termes de performances de référence, d’ici le premier trimestre 2027. Tang Jie, fondateur de Z.ai, a immédiatement répondu que « cela ne prendrait pas autant de temps ». Musk a ensuite précisé que, bien que la Chine puisse atteindre les performances de référence, atteindre un niveau de « véritable utilité pratique » est un exploit plus difficile à réaliser.
Le rapport du *Wall Street Journal* donne du poids à l’optimisme de Tang Jie. Il montre que le GLM-5.2 rivalise déjà avec le Mythos dans la découverte de vulnérabilités de sécurité, l’une des applications réelles les plus précieuses de l’IA actuelle. Le modèle open source GLM-5.2 permet également aux chercheurs d’utiliser des techniques d’invite supplémentaires pour atteindre des performances comparables à celles du Mythos, ce qui suggère qu’un modèle « plus faible » en général peut être optimisé pour des tâches clés spécifiques grâce à des méthodes appropriées.
Cette avancée a un impact considérable sur le secteur de la cybersécurité. Alors que les modèles d’IA open source atteignent des performances comparables à celles des modèles propriétaires dans la découverte de vulnérabilités, le paysage de la cyberdéfense pourrait connaître un bouleversement majeur. Les entreprises disposent de plus d’outils, mais sont également confrontées à des risques accrus, car les mêmes outils peuvent être utilisés par des adversaires. Le rapport souligne que le centre de gravité de la compétition en IA se déplace : il ne s’agit plus seulement de savoir qui possède le modèle le plus performant en termes de référence, mais de savoir qui peut transformer les capacités de l’IA en solutions pratiques et à haute valeur ajoutée dans le monde réel. Dans le domaine de la cybersécurité, la Chine a déjà démontré sa capacité à combler rapidement l’écart.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com








