
fr.wedoany.com Rapport : AudioX-Turbo, un modèle audio ultra-rapide, a été dévoilé : il génère 10 secondes d'audio en 0,24 seconde avec seulement 4 étapes d'inférence. Développé par Noiz AI en collaboration avec l'Université des Sciences et Technologies de Hong Kong et l'Université Tsinghua, ce modèle prend en charge des entrées multimodales telles que le texte, la vidéo et l'image. Grâce aux techniques de distillation par appariement de distribution et de distillation antagoniste, il réduit le processus de génération des modèles de diffusion traditionnels, qui nécessitait 50 à 200 étapes, à seulement 4 étapes, diminuant ainsi le nombre de passages avant du modèle d'environ 25 fois. Sur une seule carte graphique RTX 4090, la génération de 10 secondes d'audio ne prend que 0,24 seconde, avec un facteur temps réel de seulement 0,02, ouvrant ainsi la voie à des interactions audio en temps réel.
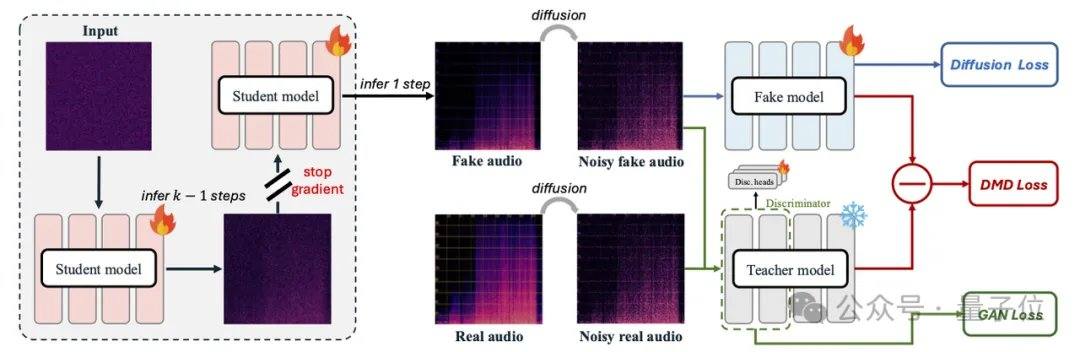
Les modèles audio grand public actuels, tels que MMAudio et Stable Audio Open, reposent sur des techniques de diffusion ou de flux, nécessitant généralement des dizaines, voire des centaines d'itérations. AudioX-Turbo utilise le Multimodal Diffusion Transformer (MMDiT) à fusion multimodale native comme squelette, et intègre le module MAF pour entraîner à partir de zéro un modèle de 2,7 milliards de paramètres. Dans le cadre du flux, l'équipe de recherche a introduit la distillation par appariement de distribution (DMD) et la distillation antagoniste pour compresser le modèle à 4 étapes, tout en éliminant les coûts supplémentaires de NFE grâce à la distillation CFG. Grâce au discriminateur de diffusion, le modèle étudiant surpasse même le modèle enseignant à 100 étapes sur certains indicateurs de performance.
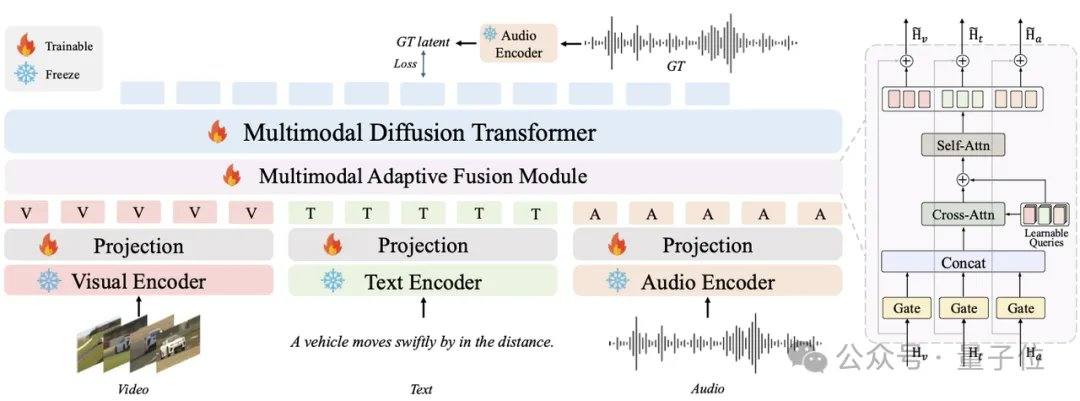
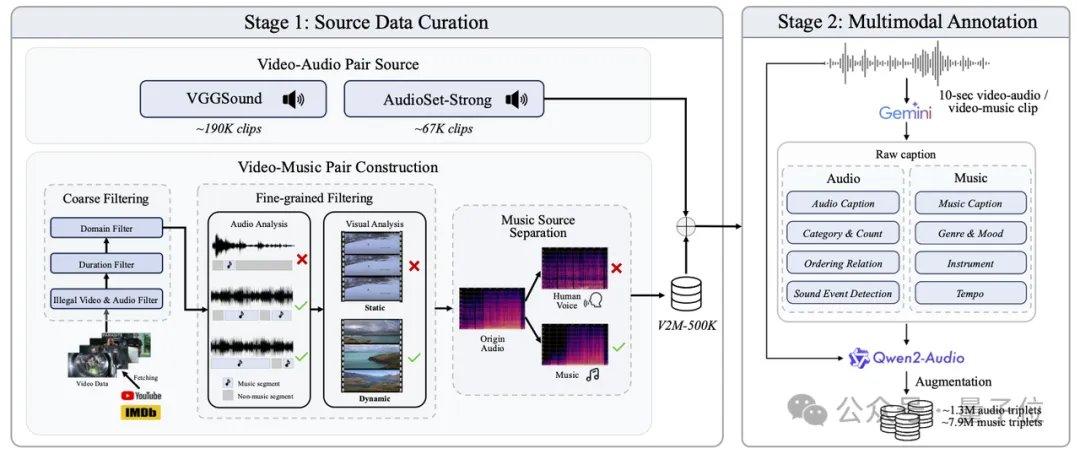
AudioX-Turbo résout également le problème du contrôle précis des modèles audio. L'équipe de recherche souligne que de nombreux modèles précédents ne pouvaient pas contrôler précisément les horodatages, la cause étant le flou des étiquettes textuelles dans les données d'entraînement. Pour y remédier, Noiz AI et l'équipe de l'Université des Sciences et Technologies de Hong Kong ont spécialement créé un ensemble de données audio multimodales à très grande échelle, IF-caps-Pro, totalisant environ 9,2 millions d'échantillons. L'équipe a adopté un schéma d'« annotation en cascade par grands modèles », en construisant d'abord une vaste collection de paires vidéo-audio de haute qualité, en utilisant le modèle Gemini 2.5 Pro pour générer des modèles structurés avec horodatages, instruments et nombre d'événements, puis en les développant à grande échelle avec Qwen2-Audio, transformant ainsi les données de « résumés flous » en « scénarios avec une chronologie précise ».
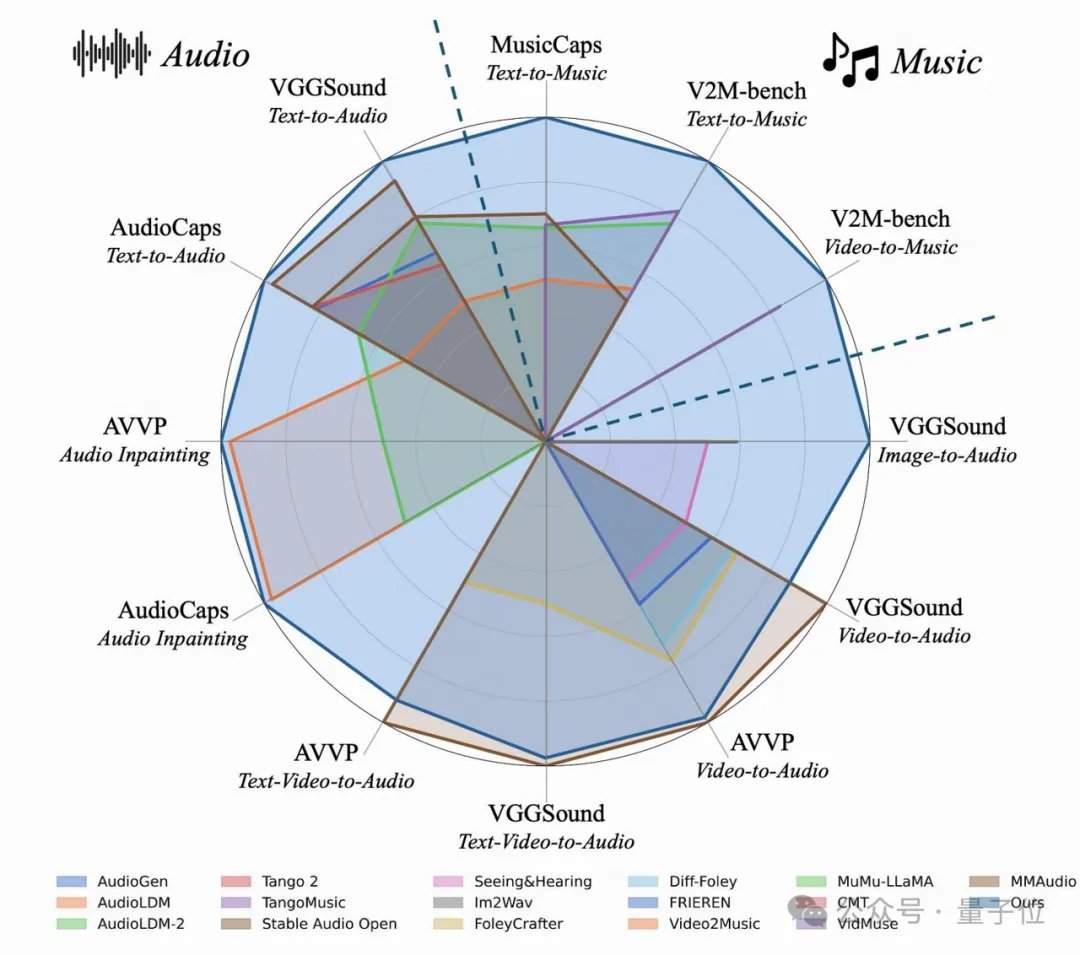
L'équipe de recherche a découvert par hasard que plus les étiquettes textuelles sont détaillées, meilleure est la génération audio à partir de texte, et que l'alignement lors du doublage de vidéos muettes s'améliore également considérablement. Dans les ensembles de test classiques comme AudioCaps et MusicCaps, le modèle AudioX-Turbo à 4 étapes bat ou égalise de nombreux modèles de base nécessitant 50 à 200 étapes sur les indicateurs de qualité audio essentiels. Pour évaluer la capacité de suivi des instructions, l'équipe a construit un benchmark spécialisé, T2A-bench. Dans les évaluations portant sur les catégories de sons, les quantités, les horodatages et l'ordre séquentiel, AudioX-Turbo surpasse largement les autres méthodes de base, certains indicateurs étant plus du double de ceux des bases.
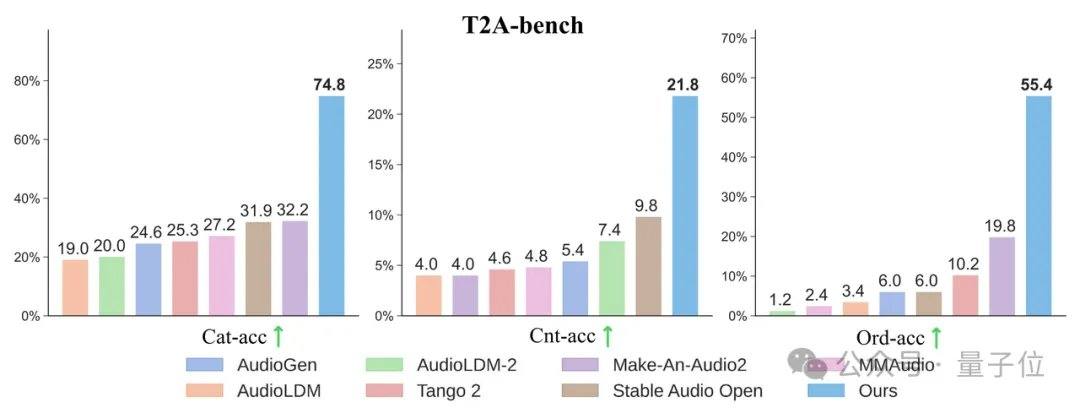
Les trois points forts d'AudioX-Turbo sont les suivants : inférence en 4 étapes, réduisant la charge de calcul de 25 fois par rapport au modèle enseignant, avec de meilleures performances et un RTF de seulement 0,02 ; un ensemble de données de 9,2 millions d'instructions puissantes, permettant pour la première fois un contrôle précis des horodatages ; et la prise en charge d'entrées multimodales (texte, vidéo, image) pour la génération Anything-to-Audio. Tous les codes d'entraînement et les poids du modèle de ce projet sont entièrement open source. L'article, intitulé « AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation », a été réalisé par les équipes de Noiz AI, de l'Université des Sciences et Technologies de Hong Kong et de l'Université Tsinghua. La page d'accueil du projet est https://zeyuet.github.io/AudioX-Turbo/.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com









