
fr.wedoany.com Rapport : L'Université Renmin de Chine, en collaboration avec Microsoft Research, a lancé le framework Arbor, qui transforme l'optimisation autonome des systèmes d'IA d'un processus d'essais-erreurs en un mécanisme d'apprentissage cumulatif. Ce framework, grâce à une gestion structurée des hypothèses, permet d'obtenir une amélioration vérifiable des performances de plus de 2,5 fois dans des tâches d'ingénierie réelles.

Avec l'augmentation des capacités des grands modèles de langage et des systèmes d'IA, l'optimisation autonome devient un défi central. Lors de l'optimisation des agents d'IA, les équipes d'ingénierie doivent souvent ajuster simultanément plusieurs paramètres tels que les stratégies de partitionnement, les méthodes de recherche et les invites système. Ces ajustements sont interdépendants et difficiles à attribuer avec précision, ce qui rend le processus d'optimisation inefficace. Jiajie Jin, co-auteur de l'article, souligne que donner simplement plus de temps ou de ressources de calcul à un agent de codage n'apporte pas de meilleurs résultats : « Si l'objectif est flou ou si les indicateurs sont facilement contournables, une exécution prolongée ne fait souvent que générer plus rapidement des 'améliorations' que personne ne souhaite vraiment. »
Les agents de codage existants s'appuient sur l'historique des dialogues comme mémoire, mais les tâches d'optimisation autonome impliquent des centaines d'interactions, dépassant facilement les limites de la fenêtre de contexte. Les agents ont du mal à conserver des preuves factuelles dans un long historique, perdent la structure globale du processus de recherche et stagnent souvent sur des échecs précoces ou poursuivent des fluctuations d'évaluation bruitées. Parallèlement, les frameworks génériques organisent les chaînes d'appels d'outils sur un arbre de travail partagé, ce qui empêche de tester des hypothèses parallèles dans un environnement isolé.
Arbor résout ce défi grâce à une architecture de séparation des rôles : le coordinateur, en tant que chercheur principal, gère l'état global de la recherche d'optimisation, propose des hypothèses et décide de l'orientation des expériences, sans modifier directement le code source ; l'exécuteur est un agent à courte durée de vie qui teste des hypothèses spécifiques dans un arbre de travail git indépendant. Les deux composants collaborent via un mécanisme de « raffinement de l'arbre d'hypothèses », représentant le processus de recherche comme un arbre de branches persistant, chaque nœud étant lié à une hypothèse, un artefact exécutable, des preuves factuelles et des informations distillées. Le coordinateur place des idées générales au nœud racine et des raffinements spécifiques aux nœuds feuilles, permettant d'explorer simultanément plusieurs directions concurrentes. Les expériences échouées sont enregistrées comme des contraintes négatives, empêchant le système de répéter les mêmes erreurs.
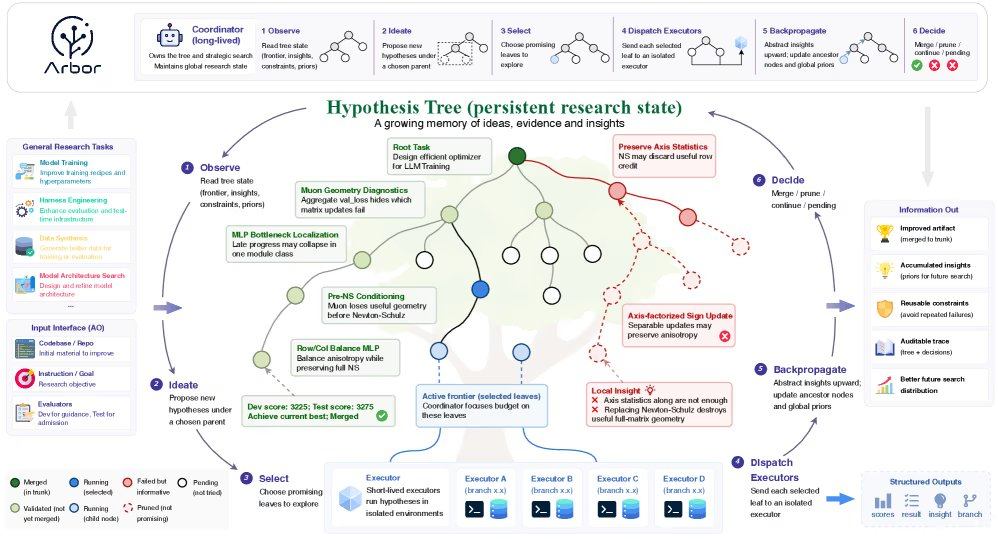
Dans des scénarios d'ingénierie réels, Arbor permet une attribution claire des propriétés en traitant chaque levier d'optimisation comme une hypothèse distincte. Après que l'exécuteur a renvoyé un rapport, le coordinateur écrit les preuves dans l'arbre et rétropropage les informations vers le nœud parent. Pour éviter le surapprentissage, le framework impose une « porte de fusion » : les solutions candidates sont testées dans un arbre de travail indépendant et ne sont fusionnées dans la branche principale optimale actuelle que si elles améliorent le score de test de rétention.
Les chercheurs ont évalué Arbor sur une suite de tâches d'optimisation autonome basée sur un environnement de recherche réel et sur le benchmark d'ingénierie machine learning MLE-Bench Lite. La suite AO couvre des tâches telles que l'entraînement de modèles, l'ingénierie de frameworks et la synthèse de données. Avec des modèles de base comme Claude Opus 4.6, GPT-5.5 et Gemini-3-Flash, le gain relatif moyen d'Arbor est plus de 2,5 fois supérieur à celui de Codex et Claude Code. Dans la tâche BrowseComp d'optimisation d'agents de recherche, Arbor a amélioré le taux de précision de rétention du système de 45,33 % à 67,67 %, tandis que Codex et Claude Code sont restés respectivement à 50 % et 53,33 %. Sur MLE-Bench Lite, Arbor a obtenu les meilleurs résultats avec GPT-5.5.
Arbor montre une résilience face au surapprentissage. Dans l'expérience Terminal-Bench 2.0, Claude Code a obtenu un score de développement de 75 mais est tombé à 71 sur les données de rétention ; Arbor a eu un score de développement plus faible de 72,22 mais a atteint le score de rétention le plus élevé de 77,36. Les expériences de transfert entre tâches montrent que le code optimisé pour le framework de recherche BrowseComp peut améliorer significativement les performances sur des tâches non liées comme HLE et DeepSearchQA.
Ce framework est conçu pour s'appuyer sur les flux de travail Git existants. Jin indique qu'Arbor produit des branches git ordinaires, directement vérifiables par les processus de révision de code et d'examen humain existants. Le coût principal de déploiement réside dans la consommation de tokens pour maintenir le coordinateur et gérer l'arbre, ainsi que dans les besoins en calcul et en ressources disque des multiples arbres de travail isolés. Le framework est adapté aux tâches avec des indicateurs fiables et clairs, tolérant des délais longs et présentant plusieurs directions de recherche raisonnables, comme l'optimisation de pipelines, la qualité de synthèse de données et le réglage d'entraînement de modèles. Il ne doit pas être utilisé pour des tâches en temps réel, des corrections simples ou des scénarios où les indicateurs d'évaluation sont défectueux. Jin estime que la prochaine évolution consistera à faire passer les artefacts de chaque nœud d'un score scalaire unique à une recherche multi-objectifs de Pareto, intégrant des vecteurs de précision, de latence et de coût.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com








