
fr.wedoany.com Rapport : Des chercheurs de l’IMDEA Software Institute, des Nokia Bell Labs, de l’Université Complutense de Madrid, de l’Université d’Aalto et de Quobly ont développé une architecture matérielle basée sur FPGA pour le décodage en temps réel des codes LDPC quantiques. Cette conception, publiée sur ArXiv, gère les réseaux d’erreurs corrélées via une disposition structurelle, optimisant la latence, la surface physique et la consommation énergétique, tout en résolvant le goulot d’étranglement du calcul classique qui entrave l’extension physique de la couche de correction d’erreurs quantiques. L’architecture utilise des boucles ciblées de réutilisation des ressources, plutôt qu’une parallélisation matérielle illimitée, pour traiter les dépendances complexes des syndromes multi-qubits.
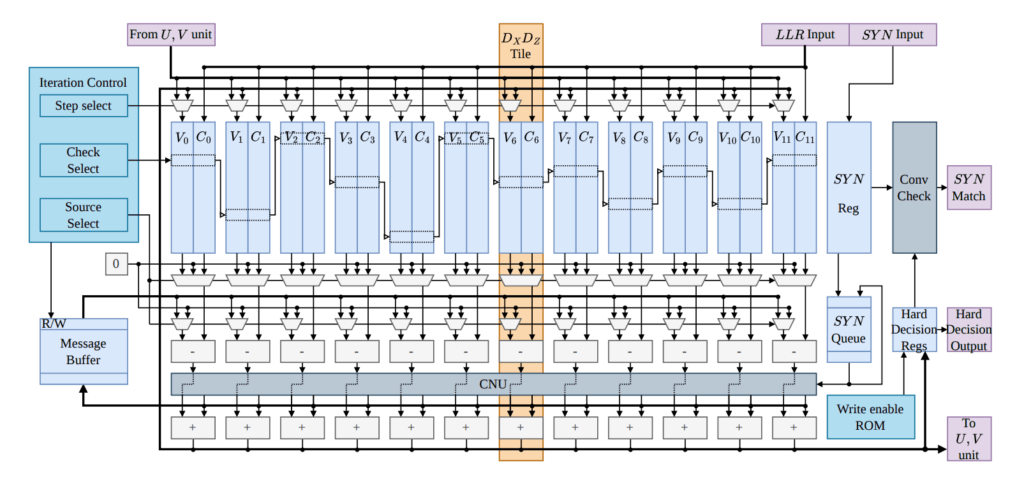
La disposition interne du décodeur est directement mappée sur le cadre spécialisé d’inférence par renforcement et reconnexion de graphes (GARI). Les routines de décodage standard traitent généralement indépendamment les coordonnées spatiales d’erreur X et Z, ce qui réduit la fidélité de suivi lorsque les paramètres de retournement de phase et de bit sont liés par des défauts combinés de type Y. La transformation GARI modifie la matrice du modèle d’erreur du détecteur sous-jacent en séparant les variables corrélées et en éliminant les 4-cycles courts impliquant des erreurs Y, remplaçant le graphe enchevêtré par des dépendances structurées des coordonnées U et V. Cette reconstruction algébrique permet au matériel de répartir la tâche de décodage conjointe sur des chemins d’exécution découplés, tout en maintenant un échange d’informations itératif entre les domaines d’erreur et en supprimant les corrélations nuisibles des messages.
Pour exécuter la matrice reconstruite, l’architecture divise les tâches de traitement en un cœur de propagation de croyance (BP) et un module de suivi parallélisé. Les matrices principales DX et DZ sont acheminées via une unité BP basée sur la mémoire et à ordonnancement série, qui met à jour séquentiellement les paramètres de calcul selon la règle normalisée du minimum-somme. Les structures de vérification indépendantes des matrices U et V sont parallélisées dans des tuiles matérielles séparées, synchronisées avec le cœur série à des intervalles de traitement. L’interconnexion modulaire croisée utilise des étapes de tri par base binaire comme routeur pipeline N-à-N, contournant la logique de contrôleur classique explicite, empêchant ainsi la congestion du routage et les blocages du bus de données.
Cette implémentation matérielle a été évaluée sur un FPGA AMD VCU19P et mappée sur une structure FPGA VU29P pour décoder le code bicyclique bivarié [[144,12,12]] sur une fenêtre de 12 cycles consécutifs de mesure de syndrome. L’architecture applique des contraintes de quantification numérique, limitant les rapports de vraisemblance logarithmiques (LLR) d’entrée à 6 bits, les messages des nœuds de vérification à 8 bits et les valeurs des nœuds de variable à 10 bits, tout en approximant la précision numérique du modèle de suivi classique en virgule flottante. Fonctionnant à environ 274 MHz via des ports AXI-Stream, le cycle d’exécution pipeline fournit une latence de décodage moyenne de 596 nanosecondes par cycle, satisfaisant les contraintes de décodage en temps réel sous des distributions de bruit corrélées réalistes.
Un seul cœur occupe une surface limitée, comprenant 7,5 % des tables de correspondance logiques (LUT) totales, 3,5 % des registres et 26 % des éléments de mémoire bloc RAM (BRAM) internes, avec un mappage partiel possible sur des blocs URAM pour réduire la pression mémoire. Cette efficacité en ressources permet à trois configurations de décodeurs combinés de fonctionner simultanément sur une seule carte FPGA VCU19P. Une configuration de suivi complète de 24 décodeurs concurrents peut être déployée sur huit dispositifs matériels physiques, contre 48 cartes nécessaires pour une architecture alternative entièrement parallélisée.
L’allocation détaillée des ressources silicium, la dérivation de la transformation matricielle et les benchmarks de latence de routage sont disponibles dans le préprint complet fourni sur ArXiv.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com









