fr.wedoany.com Rapport : Google a récemment publié un article technique expliquant comment l’essor de l’IA a remodelé son architecture réseau. L’article indique qu’à mesure que les infrastructures sous-jacentes des services tels que Gemini, Veo, la recherche et Cloud AI dépendent de plus en plus de systèmes réseau étroitement intégrés conçus pour un trafic est-ouest à grande échelle, une faible latence et une haute résilience, le réseau est devenu la couche fondamentale du système d’IA lui-même. Amin Vahdat décrit en détail cette transformation dans l’article.
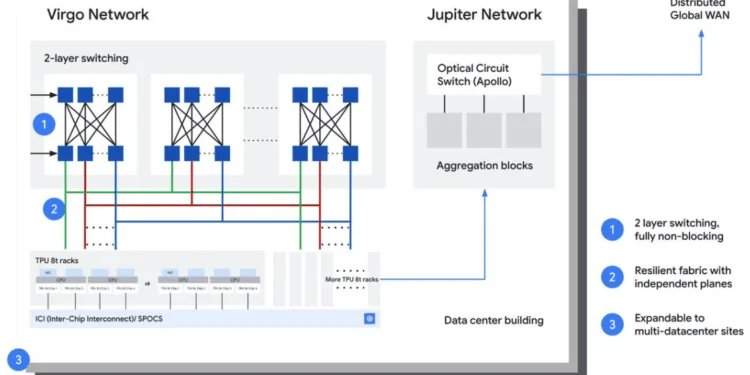
Google considère désormais l’infrastructure IA comme une plateforme de calcul distribué sans précédent. Les charges de travail d’entraînement et d’inférence s’étendent sur plusieurs clusters, bâtiments et même campus, nécessitant le transfert de quantités massives de données via des interconnexions avec une latence prévisible. Google décrit une architecture capable d’intégrer des ressources sur plusieurs sites, formant ce qu’elle appelle un « supercalculateur » IA à grande échelle. Cela nécessite une coordination étroite entre les réseaux de clusters, la transmission optique régionale et le réseau étendu mondial. Le réseau dorsal privé de Google couvre déjà plus de 7,75 millions de kilomètres de systèmes de câbles terrestres et sous-marins, desservant plus de 200 pays et régions, afin de soutenir les charges de travail IA distribuées à l’échelle mondiale.
L’article souligne que l’IA brouille les frontières traditionnelles entre les réseaux de centres de données et les réseaux étendus. Historiquement, les structures des centres de données étaient optimisées pour le trafic est-ouest à courte distance à l’intérieur des bâtiments, tandis que les réseaux étendus géraient les connexions longue distance entre les régions. Aujourd’hui, l’entraînement de grands modèles génère un trafic synchrone entre des milliers d’accélérateurs, dépassant souvent un seul POD ou campus, ce qui oblige l’extension de bande passante, la gestion de la congestion, la planification de la capacité optique et l’ingénierie du trafic à fonctionner comme un système unifié. Google considère cela comme une convergence architecturale entre la commutation, le routage, la transmission optique et le contrôle défini par logiciel.
Le logiciel joue un rôle clé dans l’orchestration de ces réseaux. Google souligne que le placement des charges de travail IA dépend de plus en plus d’une gestion intelligente du trafic à travers plusieurs couches d’infrastructure. Les réseaux définis par logiciel sont utilisés pour équilibrer le trafic, isoler les pannes, optimiser la latence et allouer dynamiquement la capacité entre des charges de travail concurrentes. Cela est particulièrement important pour l’entraînement distribué à grande échelle, car le lien le plus lent dans un cluster synchrone peut affecter les performances globales du modèle. Le plan de contrôle réseau de Google agit de plus en plus comme une couche d’orchestration entre le calcul et la transmission.
L’article met également en lumière l’importance de l’innovation matérielle dans les réseaux IA. Google mentionne ses investissements dans des puces réseau personnalisées, l’accélération matérielle et les technologies d’accès direct à la mémoire pour minimiser la latence et améliorer le débit entre les ressources de calcul. Cela s’aligne sur la tendance des fournisseurs de cloud hyperscale à adopter des réseaux basés sur RDMA, des structures à échelle optique et des architectures de commutation à haute cardinalité conçues spécifiquement pour les clusters IA. Le contenu de l’article reste au niveau système, sans entrer dans les détails spécifiques des produits, mais reflète la tendance de l’industrie où le réseau est co-conçu avec les accélérateurs, les systèmes mémoire et le stockage.
L’architecture de Google est étroitement alignée sur son plan plus large de supercalculateur IA, y compris la structure d’extension Virgo lancée lors de Cloud Next. Cette plateforme connecte à grande échelle les ressources TPU et GPU, et permet aux charges de travail de se répartir sur plusieurs centres de données. Des approches similaires existent dans l’industrie, notamment NVLink et les structures IA basées sur InfiniBand de Nvidia, les réseaux de clusters IA à grande échelle de Meta, le backbone Azure AI de Microsoft, ainsi que les travaux d’AWS sur EFA et les réseaux optiques personnalisés. La contribution de Google montre comment ces concepts s’étendent des clusters aux infrastructures métropolitaines et mondiales.
Les informations clés de l’article incluent : Google positionne le réseau comme un composant architectural central du système IA, et non comme une simple couche de transport de soutien ; les charges de travail IA fonctionnent de plus en plus sur plusieurs clusters et campus, nécessitant des interconnexions à très haute capacité ; la séparation traditionnelle entre les structures des centres de données et les architectures de réseaux étendus se réduit à mesure que le trafic est-ouest IA s’étend géographiquement ; Google s’appuie sur l’ingénierie du trafic définie par logiciel pour optimiser les performances et le placement des charges de travail à travers les couches réseau ; la résilience réseau reste centrale, avec une diversité de routage et un isolement des pannes intégrés dans les infrastructures des centres de données, régionales et dorsales ; l’entreprise continue d’investir dans du matériel réseau personnalisé et des transmissions haute performance pour soutenir les communications IA à faible latence ; l’architecture de Google prend en charge à la fois les charges de travail IA internes et les clients externes de Google Cloud utilisant l’infrastructure de supercalculateur IA de l’entreprise.
« Les charges de travail IA modifient l’ampleur et la forme des besoins en infrastructure à chaque couche du réseau », écrivent les équipes d’ingénierie de Google, décrivant un environnement où les réseaux de centres de données et l’infrastructure dorsale mondiale fonctionnent de plus en plus comme un système distribué unique.