
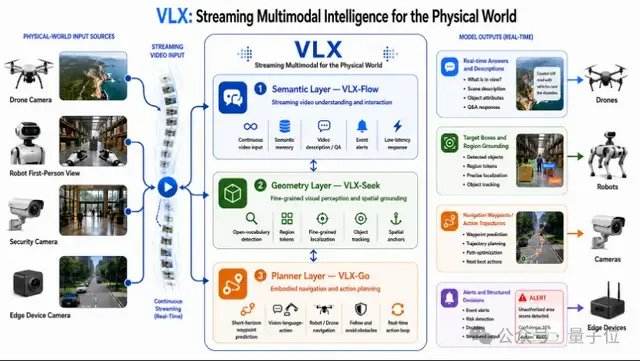
fr.wedoany.com Rapport : L'entreprise d'intelligence artificielle Om AI, basée à Hangzhou, a lancé VLX, la première série de modèles multimodaux fluides côté client au monde, conçue pour le monde physique. Cette série comprend trois modèles qui seront dévoilés successivement en trois jours : VLX-Flow est responsable de la perception fluide en temps réel, permettant à la vidéo de s'écouler comme de l'eau, le modèle observant, réfléchissant et mettant à jour l'état du monde en temps réel ; VLX-Seek est responsable du positionnement précis, passant de la vision à la clarté pour verrouiller rapidement les cibles ; VLX-Go est responsable de la prise de décision d'action, transformant les résultats de la perception et du positionnement en actions réelles, en définissant clairement la direction du déplacement et les étapes opérationnelles.
Ces trois modèles, connectés entre eux, forment une boucle de capacités complète pour le modèle multimodal, allant de la perception continue au positionnement précis, puis à la prise de décision d'action. Leur conception native côté client permet au modèle de fonctionner réellement sur des appareils tels que les téléphones, les drones et les robots.
Ce n'est pas la première incursion d'Om AI dans le domaine du langage visuel. L'année dernière, l'entreprise a lancé VLM-R1, le premier projet open source au monde à introduire le paradigme d'apprentissage par renforcement DeepSeek R1 dans les modèles de langage visuel. En 12 heures, il a obtenu plus de 2000 étoiles GitHub, et en 48 heures, il a atteint la première place du classement mondial GitHub Trending, comptant aujourd'hui plus de 6000 étoiles.
La série VLX est conçue autour de deux mots-clés : côté client et multimodal fluide. Le multimodal fluide désigne la capacité de l'IA à percevoir en continu et en temps réel l'environnement dans le monde physique, formant une chaîne de capacités complète allant de la perception au positionnement précis, puis à l'action. Cela diffère du multimodal fluide dans les assistants vocaux, qui met l'accent sur l'interaction en temps réel entre l'homme et l'IA, tandis que VLX se concentre sur l'observation, le jugement et l'action continus de l'IA dans le monde physique, réalisant le passage de la simple observation à l'exécution de tâches. Avec le développement rapide de domaines tels que l'intelligence incarnée, l'intelligence spatiale et la génération vidéo, les modèles de langage visuel ne sont plus simplement des modules de capacité des modèles de langage, mais deviennent progressivement une nouvelle génération d'infrastructures pour la compréhension spatiale, la compréhension vidéo et même la planification d'actions. Les données du CVPR de cette année montrent que la proportion d'articles sur les modèles de langage visuel et le multimodal est passée de 4,9 % l'année dernière à 10,6 %, devenant l'un des domaines de recherche à la croissance la plus rapide ces dernières années, la perception en temps réel et le positionnement étant les deux mots-clés les plus notables.
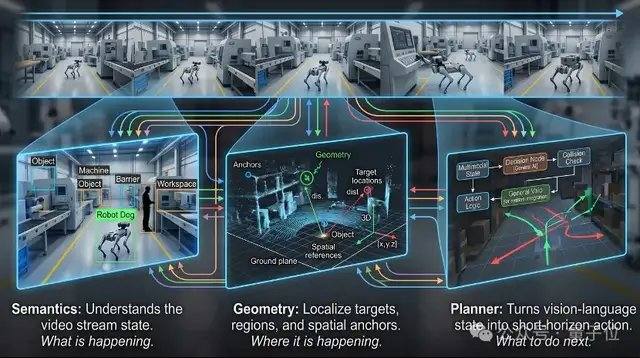
VLX-Flow est responsable de la perception continue. Dans le monde réel, les objets sont constamment en mouvement, l'environnement change sans cesse, et les perspectives changent fréquemment ; une observation ponctuelle ne peut pas faire face à un environnement dynamique, ouvert et en constante évolution. Les modèles vidéo traditionnels découpent souvent la vidéo entière en images et les soumettent en une seule fois au modèle pour une compréhension hors ligne. Lorsque la vidéo est longue, non seulement le coût de calcul augmente considérablement, mais les informations précédentes risquent également d'être perdues. Flow adopte un traitement fluide : les images s'écoulent en continu comme de l'eau, s'appuyant sur un codage incrémental et un mécanisme de cache pour mettre à jour en permanence l'état visuel, sans avoir à recalculer l'historique et sans perdre la mémoire à mesure que la vidéo s'allonge. Sur le plan technique, Flow utilise l'Attention Linéaire à la place de l'Attention standard, combinée à un mécanisme de mémoire à deux niveaux, permettant au flux vidéo de continuer à entrer dans le modèle sans provoquer d'explosion de la mémoire GPU due à l'augmentation du contexte.

VLX-Seek est responsable de la perception fine. De nombreux modèles de langage visuel généraux, bien que performants dans la compréhension sémantique de haut niveau, sont limités dans des tâches telles que le positionnement précis, la détection de vocabulaire ouvert et le grounding fin. Les méthodes traditionnelles adoptent une approche autorégressive, prédisant la position de la cible coordonnée par coordonnée, ce qui est lent et sujet aux erreurs. Seek change d'approche : au lieu de deviner les coordonnées, il génère d'abord des régions candidates, puis effectue la recherche et la correspondance, transformant le processus de positionnement en une sélection de régions. Plus précisément, Seek utilise des Region Tokens pour remplacer la génération traditionnelle de coordonnées, réduisant considérablement la taille du modèle et le coût de déploiement côté client tout en maintenant la capacité de reconnaissance. Cette approche est plus adaptée à la nature même des tâches de perception visuelle, de sorte que même avec une taille de modèle plus petite, elle peut maintenir des performances stables dans des tâches telles que la détection de vocabulaire ouvert, le grounding fin et le suivi en temps réel.

VLX-Go est responsable de l'action. Les modèles de langage visuel traditionnels, même s'ils savent que la cible se trouve devant à gauche, se limitent généralement à répondre par du texte. Pour réellement s'y rendre, contourner les obstacles et suivre la cible en continu, un système de contrôle supplémentaire est nécessaire. Go prend en entrée la vidéo monoculaire, la mémoire visuelle historique et les instructions en langage naturel, et les traite directement en waypoints à court terme exécutables par le robot, prédisant comment se déplacer dans un futur proche, plutôt que de simplement fournir des suggestions textuelles. Go combine l'apprentissage de trajectoire hors ligne et l'apprentissage par renforcement en ligne, corrigeant continuellement la stratégie de mouvement dans une boucle fermée de simulation, permettant au robot d'ajuster constamment sa trajectoire en fonction du retour visuel en temps réel, et de maintenir des performances stables dans des tâches telles que le suivi de cible, la navigation et l'évitement dynamique d'obstacles. Pour répondre aux besoins de contrôle en temps réel côté client, Go adopte un schéma léger de prédiction de waypoints à court terme, utilisant seulement 0,6B paramètres pour réaliser une planification de mouvement en temps réel.
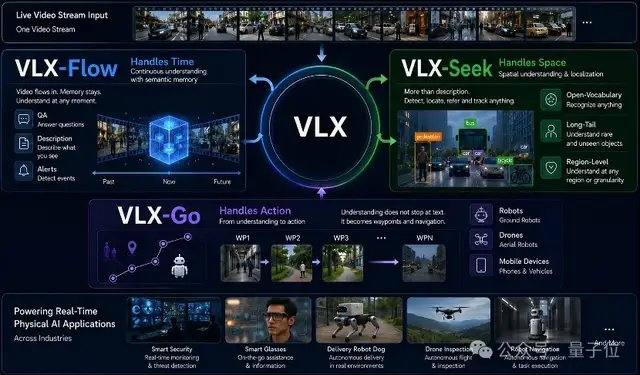
Les trois modèles Flow, Seek et Go ne sont pas indépendants les uns des autres ; ils partagent la même base et collaborent de bout en bout sur le même flux vidéo. De la perception continue au positionnement précis, puis à la prise de décision d'action, ils forment ensemble une chaîne de capacités complète de VLX pour le monde physique.
Pour les appareils du monde physique tels que les robots, les drones et les caméras, le déploiement côté client est une condition préalable à la mise en œuvre réelle du modèle. De nombreux modèles multimodaux dans le cloud sont déjà suffisamment puissants, mais ils ne sont pas naturellement adaptés aux scénarios robotiques et incarnés, car le monde réel est continu, dynamique et limité en ressources. L'approche courante dans l'industrie consiste d'abord à entraîner un modèle aussi grand que possible, puis à le compresser pour une exécution côté client via la quantification, la distillation, etc. VLX a choisi une voie différente : dès la conception, il a repensé l'ensemble du système en fonction des contraintes de calcul côté client, l'architecture du modèle, la méthode d'inférence et la chaîne de déploiement étant toutes conçues autour du flux vidéo en temps réel et des appareils côté client.
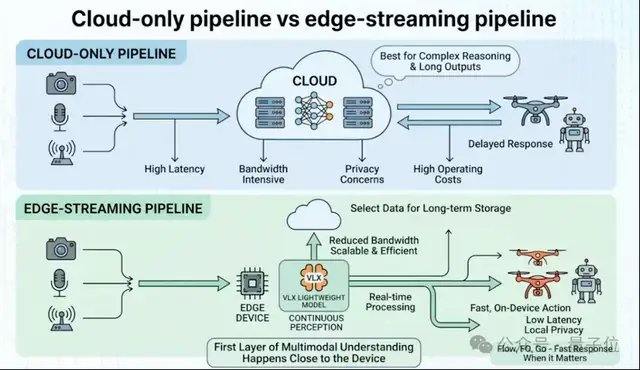
Les données montrent que VLX-Flow ne prend que 0,06 seconde pour traiter un seul flux vidéo, tout en étant capable de gérer plusieurs flux vidéo de manière stable ; VLX-Go, avec environ un dixième de la taille des paramètres, obtient des performances de navigation supérieures à celles de modèles plus grands ; VLX-Seek, avec un modèle de niveau 3B, atteint ou dépasse les performances de modèles généraux plus grands dans des tâches telles que la détection d'objets.

Om AI est une entreprise d'intelligence artificielle basée à Hangzhou. Son fondateur et PDG, Zhao Tiancheng, est titulaire d'un doctorat en informatique de l'Université Carnegie Mellon et est lauréat du Prix des progrès scientifiques et technologiques en intelligence artificielle Wu Wenjun. Les membres de l'équipe sont issus d'institutions telles que CMU, l'Université Tsinghua, l'Université du Zhejiang, Microsoft et Alibaba Cloud, et comptent plus de 50 articles dans des conférences de premier plan et plus de 50 brevets d'invention. En 2022, Om AI a obtenu la première certification de modèle multimodal du ministère chinois de l'Industrie et des Technologies de l'information. Le VLX publié cette fois-ci est le dernier résultat de l'entreprise autour de l'objectif de perception continue, de positionnement précis et d'action réelle.











