fr.wedoany.com Rapport : Microsoft a récemment open-sourcé un nouveau cadre nommé SkillOpt, conçu pour transformer la documentation des compétences des agents IA en objets entraînables. En introduisant des méthodes d'optimisation inspirées du deep learning, ce cadre améliore systématiquement les performances des agents dans des tâches complexes.

Dans les applications d'IA d'entreprise, les compétences des agents se présentent généralement sous forme de fichiers Markdown textuels contenant des instructions pour guider le modèle à s'adapter à des flux de travail spécifiques. Cependant, l'optimisation traditionnelle de ces compétences repose sur une édition manuelle, un processus lent et sujet aux erreurs, où les utilisateurs doivent souvent tâtonner pour trouver la combinaison d'instructions améliorant les performances. Le lancement de SkillOpt résout ce problème. Ce cadre (sous licence MIT) traite les documents de compétences comme des objets entraînables pouvant être ajustés itérativement en fonction des retours de performance, permettant ainsi une adaptation procédurale au niveau du document sans modifier les poids du modèle sous-jacent.
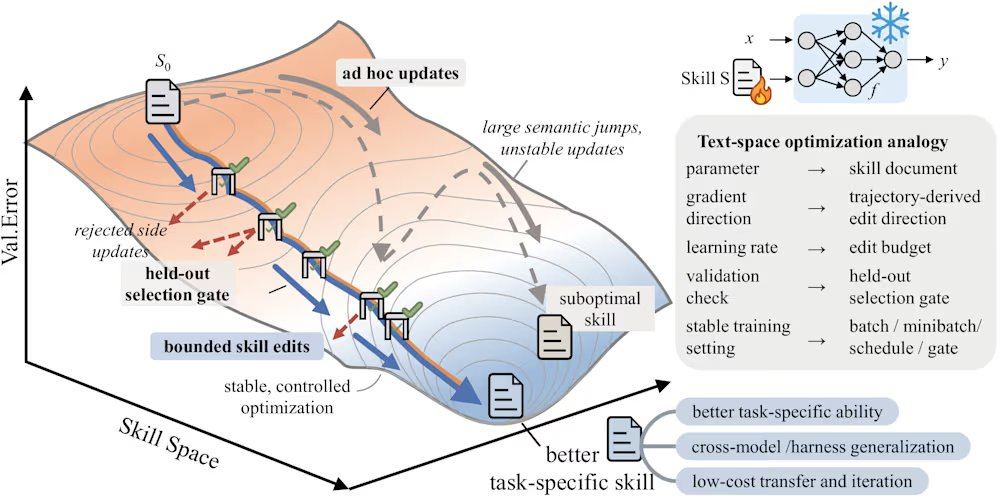
Yifan Yang, ingénieur de recherche senior chez Microsoft Research Asia, souligne que l'édition manuelle des documents de compétences est confrontée à trois modes d'échec : un manque de contrôle du pas entraînant une dérive des compétences, l'absence de mécanisme de validation rendant des modifications apparemment correctes susceptibles de dégrader les performances, et l'absence de mémoire de rétroaction négative conduisant à la répétition des mêmes erreurs. Par exemple, une réécriture sans restriction a fait chuter GPT-5.5 de 41,8 à 41,1 sur le benchmark SpreadsheetBench. Yifan Yang insiste sur le fait que ces erreurs sont amplifiées dans les flux de travail multi-étapes, ce qui constitue une faiblesse des modèles de pointe actuels en raisonnement zéro-shot.
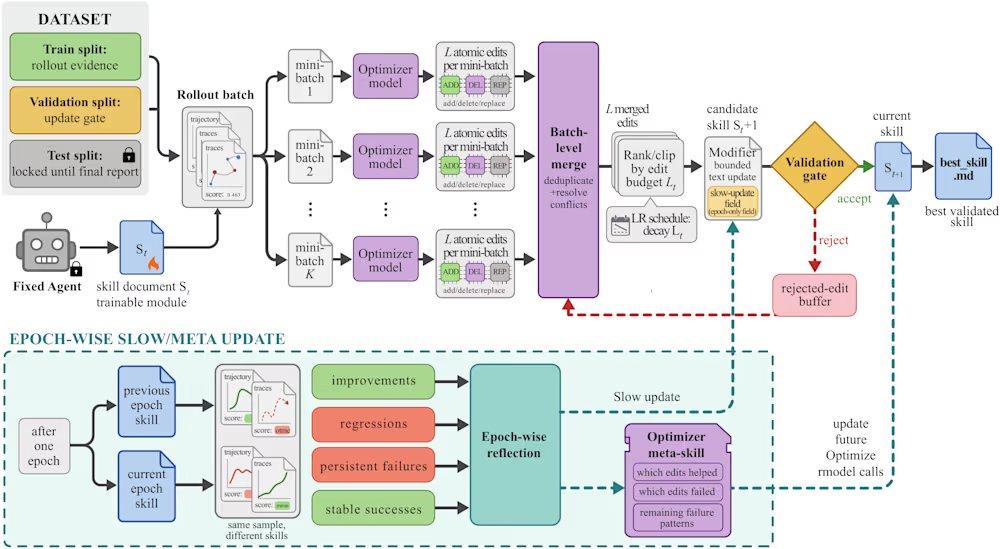
SkillOpt résout ces problèmes via un cycle itératif de proposition-test. Le processus commence par l'exécution d'un lot de tâches par un modèle cible gelé, générant des traces d'exécution comme preuve de l'état actuel. Ensuite, un optimiseur hors ligne analyse ces traces, identifie les erreurs procédurales systématiques et propose des modifications structurelles du document de compétences. Ces modifications sont examinées et classées avant d'être appliquées, avec un budget d'édition maximal par étape (similaire au taux d'apprentissage en deep learning) pour éviter une dérive brutale de la version des compétences. Les compétences candidates sont évaluées sur un ensemble de validation réservé : si elles améliorent le score de validation, elles sont acceptées ; sinon, elles sont rejetées et placées dans un tampon d'édition rejetée, fournissant une rétroaction négative à l'optimiseur. De plus, le cadre effectue une mise à jour lente en comparant les performances des tâches sous les compétences des cycles précédents et suivants, similaire à un terme de momentum, pour transmettre une expérience procédurale durable.
Lors de l'évaluation pratique, l'équipe de recherche a testé SkillOpt sur plusieurs modèles, dont GPT-5.5, GPT-5.4-mini et Qwen3.5-4B, couvrant des benchmarks tels que les questions-réponses en un tour, la génération de code multi-tours et le raisonnement documentaire multimodal. Les résultats montrent que SkillOpt surpasse plusieurs méthodes de base, notamment TextGrad, GEPA et EvoSkill, dans les 52 combinaisons d'évaluation. Sur le modèle de pointe GPT-5.5, l'amélioration absolue moyenne de la précision est de 23,5 points de pourcentage par rapport à la ligne de base sans compétence. Pour les petits modèles comme GPT-5.4-nano, les scores ont presque doublé ou triplé. Ces gains de performance se traduisent directement par des besoins clés des entreprises, tels que l'extraction précise de chiffres dans les contrats, factures et tableaux, ainsi que les opérations d'automatisation des comptes fournisseurs, de traitement des sinistres et de conformité. Yifan Yang indique que l'amélioration réside dans la fiabilité, notamment un format précis, une auto-validation et des résultats audités, ces bénéfices provenant de l'apprentissage de procédures plutôt que de la mémorisation de réponses.
Le cadre SkillOpt démontre une bonne portabilité et compatibilité. Les expériences confirment qu'il est indépendant du cadre d'exécution, avec des améliorations significatives dans des environnements d'exécution supportés par des outils comme Codex CLI et Claude Code. Par exemple, une compétence de tableur entièrement entraînée dans la boucle Codex peut être directement transférée à Claude Code sans aucune modification, entraînant une amélioration de performance allant jusqu'à 59,7 points de pourcentage par rapport à la ligne de base native de Claude Code. De plus, les artefacts de compétences peuvent être transférés entre différentes tailles de modèles : une compétence optimisée pour GPT-5.4, déployée sur des modèles plus petits comme GPT-5.4-mini et GPT-5.4-nano, continue de produire des gains positifs. Les documents de compétences finaux ne dépassent jamais 2000 tokens, avec une longueur médiane d'environ 920 tokens, ce qui les rend hautement lisibles et audités.
En termes de coût, pour les cas d'usage quotidiens en entreprise, la charge réelle de SkillOpt est légère. Yifan Yang mentionne que dans des cadres communautaires comme GBrain, les mises à jour de SkillOpt s'exécutent sur Claude Sonnet, avec un coût moyen de formation d'une compétence pour une tâche unique compris entre 1 et 5 dollars, et ce coût d'optimisation est unique. Cependant, le fonctionnement efficace du cadre nécessite deux conditions : des dizaines d'exemples représentatifs et un signal de rétroaction pouvant être noté. Les équipes doivent éviter de l'appliquer à des tâches ouvertes ou subjectives. Par ailleurs, SkillOpt peut fonctionner en synergie avec des piles d'orchestration existantes (comme DSPy), les deux étant complémentaires plutôt que substituables. En perspective, la communauté open-source a déjà commencé à déployer des exécutions régulières de SkillOpt sur les traces passées des agents pour construire un écosystème de plugins d'agents auto-optimisants. Yifan Yang estime que les compétences constituent le premier pas le plus rapide, le moins cher et le plus réversible pour que l'IA découvre des connaissances de manière autonome et améliore son propre comportement, cette même logique menant à une auto-optimisation ultime des agents, jusqu'à leurs propres poids.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com