
fr.wedoany.com Rapport : Une équipe de neuf chercheurs de Sina Weibo a dévoilé VibeThinker-3B, un modèle linguistique compact de 3 milliards de paramètres, dont les performances dans plusieurs tests de référence en matière de raisonnement égalent ou surpassent celles de systèmes plus volumineux provenant d’organisations telles que Google DeepMind, OpenAI, la société de sécurité en intelligence artificielle Anthropic et DeepSeek.
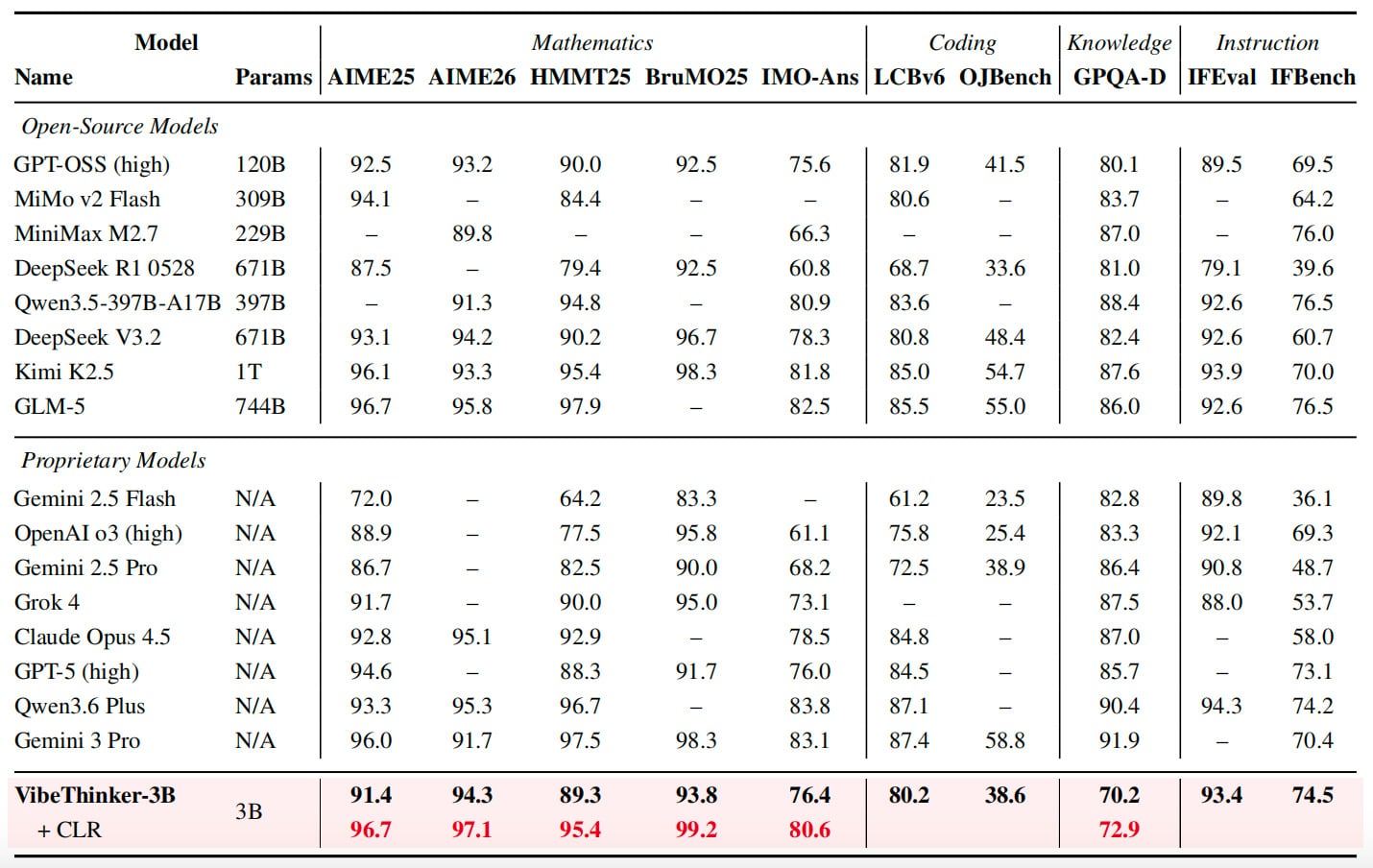
Le modèle a obtenu un score de 94,3 à l’AIME 2026, comparable à la plage de performance de DeepSeek V3.2, qui compte 671 milliards de paramètres, et a battu le score de 91,7 de Gemini 3 Pro. Grâce à une méthode d’extension au moment du test appelée « évaluation de fiabilité au niveau des déclarations » (Claim-Level Reliability Assessment), le score de VibeThinker-3B à l’AIME 2026 est passé à 97,1.
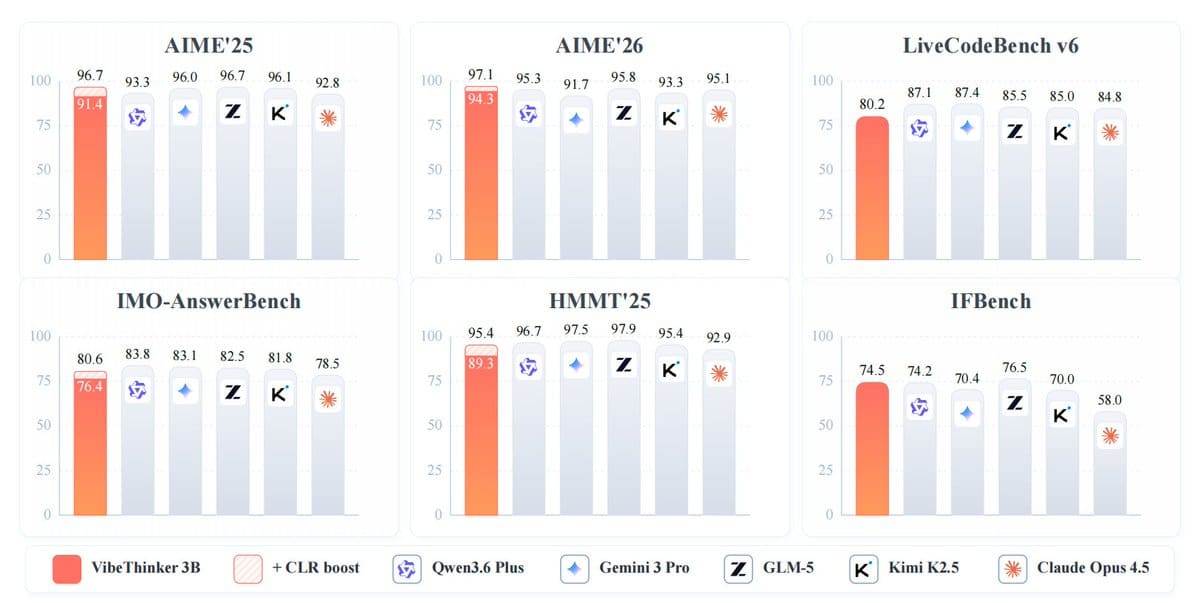
Dans d’autres tests de référence, VibeThinker-3B a obtenu 91,4 à l’AIME 2025, 89,3 au HMMT 2025, 93,8 au BruMO 2025 et 76,4 à l’IMO-AnswerBench. En matière de codage, le modèle a atteint un score Pass@1 de 80,2 sur LiveCodeBench v6 et un taux d’acceptation des soumissions de 96,1 % lors des concours hebdomadaires et bimensuels inédits de LeetCode organisés de fin avril à fin mai 2026. Sur le test de respect des instructions IFEval, son score était de 93,4.
Le modèle a réussi 123 des 128 problèmes de LeetCode soumis pour la première fois, surpassant GPT-5.2, Doubao Seed 2.0 Pro, Kimi K2.5 et Claude Opus 4.6 dans les mêmes conditions d’évaluation.
Le nombre de paramètres de VibeThinker-3B est environ 224 fois inférieur à celui de DeepSeek V3.2. En comparaison, GLM-5 compte 744 milliards de paramètres, tandis que Kimi K2.5 en dépasse mille milliards. Le modèle est suffisamment compact pour fonctionner sur un ordinateur portable grand public. L’équipe de recherche estime que les tâches de raisonnement vérifiables (comme les mathématiques et le codage) peuvent être compressées plus efficacement dans des modèles plus petits que les connaissances factuelles générales, et appelle cela « l’hypothèse de couverture par compression des paramètres ».
Le modèle n’excelle pas dans tous les domaines. Au test GPQA-Diamond, il a obtenu 70,2, contre 91,9 pour Gemini 3 Pro et 87,0 pour Claude Opus 4.5. L’équipe de recherche indique que cela soutient leur argument selon lequel les modèles compacts peuvent être performants dans les tâches de raisonnement vérifiables, mais ne peuvent pas remplacer les grands modèles offrant une couverture de connaissances plus large.
VibeThinker-3B est basé sur Qwen2.5-Coder-3B d’Alibaba et a été amélioré grâce à un processus de post-entraînement en quatre étapes. La première étape utilise un réglage fin supervisé, axé sur les données de mathématiques, de codage, de raisonnement STEM, de dialogue et de respect des instructions, avant de passer à des problèmes de raisonnement plus difficiles et plus longs. Les échantillons d’entraînement dont les traces de raisonnement sont inférieures à 5 000 tokens ont été supprimés, tout comme ceux que la version antérieure VibeThinker-1.5B pouvait résoudre à plus de 75 %. La deuxième étape utilise l’optimisation de politique guidée par l’entropie maximale (MaxEnt-Guided Policy Optimization) avec apprentissage par renforcement sur les tâches de mathématiques, de codage et de STEM. Les chercheurs ont utilisé une seule fenêtre de 64 000 tokens, plutôt qu’une extension progressive de la fenêtre de contexte, car cette dernière réduisait les performances à l’échelle de 3B. Une étape distincte « Long2Short Math RL » récompense les réponses correctes plus courtes afin de réduire les longueurs inutiles. La troisième étape distille les traces de raisonnement réussies des points de contrôle de l’apprentissage par renforcement dans un modèle unifié. La dernière étape applique l’apprentissage par renforcement aux tâches de respect des instructions à l’aide de vérifications basées sur des règles et d’un modèle de récompense.
Les résultats des tests ont suscité l’attention, mais aussi des inquiétudes quant à un possible surajustement du modèle aux tests de référence. Certains utilisateurs ont signalé que le modèle était moins performant sur des problèmes de codage réels, notamment des difficultés avec les outils de développement courants. D’autres se sont demandé pourquoi le modèle n’avait pas été testé sur un plus large éventail de tests de référence en génie logiciel. Les chercheurs affirment que les données d’entraînement ont fait l’objet d’un strict décontamination des tests de référence, y compris le filtrage des textes qui se chevauchent. Les récents concours LeetCode offrent une meilleure protection contre les fuites de données, car ils ont eu lieu après toute date limite d’entraînement possible. Cependant, les rapports des utilisateurs suggèrent toujours un écart entre les scores des tests de référence et les performances réelles.
Le modèle est publié sous licence MIT, et ses poids sont disponibles via Hugging Face et ModelScope. Dès le premier jour de sa publication, les développeurs avaient déjà généré des versions quantifiées GGUF et des modèles dérivés.
Sina Weibo est plus connu pour sa plateforme de médias sociaux que pour la recherche de pointe en intelligence artificielle. VibeThinker-3B est la deuxième publication majeure en open source de l’entreprise en sept mois. VibeThinker-1.5B, publié en novembre 2025, aurait battu le DeepSeek R1 original sur plusieurs tests de référence en mathématiques. L’équipe indique que son coût de post-entraînement était de 7 800 dollars, contre un coût estimé à 294 000 dollars pour DeepSeek R1.
Les chercheurs ne prétendent pas que VibeThinker-3B peut remplacer les grands modèles polyvalents. Ils estiment que, dans les systèmes d’IA hybrides, les petits modèles peuvent gérer les tâches de raisonnement, tandis que les grands systèmes fournissent des connaissances factuelles. Cette approche pourrait réduire le coût du déploiement du raisonnement avancé et offrir de solides capacités en mathématiques et en codage sur des appareils aux ressources matérielles limitées. La question clé est de savoir si les performances du modèle sur les tests de référence peuvent se traduire par des applications fiables dans le monde réel.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com









