

Selon les données InferenceX publiées par SemiAnalysis le 16 février, l'architecture Blackwell Ultra de NVIDIA a réalisé des progrès importants en matière d'économie de l'inférence IA. L'auteur de l'agence, Ashraf Eassa, indique que, par rapport à la plateforme précédente Hopper, le système NVIDIA GB300 NVL72 offre jusqu'à 50 fois plus de débit par mégawatt et réduit le coût par token jusqu'à 35 fois. Ces améliorations ciblent principalement les charges de travail à faible latence et à contexte long, telles que les agents de codage IA et les assistants interactifs. Le « Rapport sur l'état de l'inférence » d'OpenRouter montre que ce type de charge de travail représente actuellement environ la moitié des requêtes de programmation logicielle IA, une augmentation significative par rapport aux 11 % de novembre dernier. 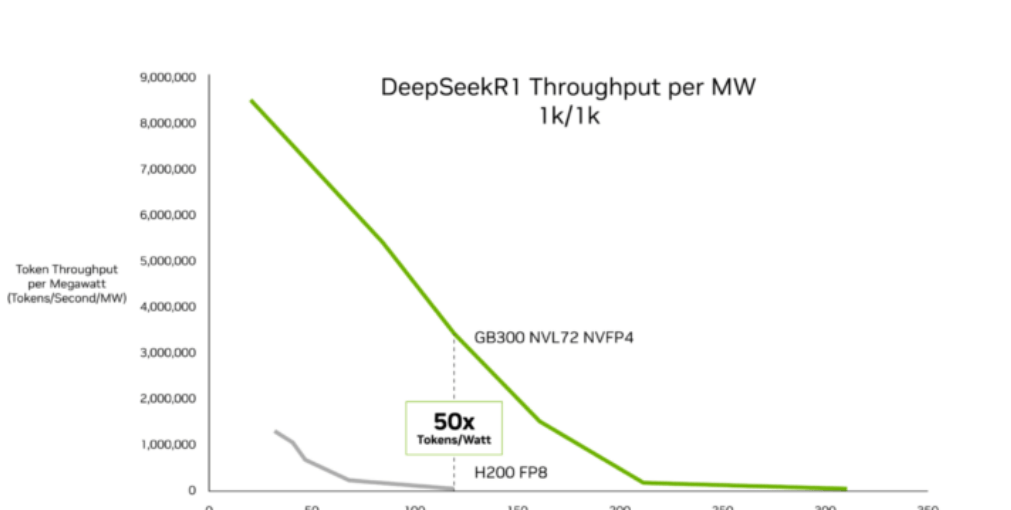
SemiAnalysis attribue les gains de performance aux progrès de la technologie des puces Blackwell Ultra ainsi qu'à l'optimisation continue des piles logicielles telles que TensorRT-LLM et Dynamo. Le GB300 NVL72 intègre des GPU Blackwell Ultra avec une mémoire symétrique NVLink et réduit les cycles d'inactivité grâce à une conception optimisée des cœurs GPU. Dans les scénarios d'inférence à faible latence, y compris les flux de travail de codage d'agents multi-étapes, le coût par million de tokens du GB300 NVL72 est jusqu'à 35 fois inférieur à celui de Hopper. Pour les charges de travail à contexte long, par exemple avec 128 000 tokens en entrée et 8 000 tokens en sortie, le coût par token du GB300 est jusqu'à 1,5 fois inférieur à celui du GB200 NVL72, grâce aux améliorations des performances de calcul NVFP4 et à un traitement de l'attention plus rapide.
Les fournisseurs de cloud déploient cette plateforme à grande échelle. Microsoft, CoreWeave et Oracle Cloud Infrastructure lancent des systèmes GB300 NVL72 pour l'inférence en production d'assistants de codage et d'autres applications d'IA agentique. SemiAnalysis rapporte que ces améliorations prolongent l'élan du déploiement de Blackwell chez les fournisseurs d'inférence, les premiers systèmes Blackwell ayant réduit le coût par token jusqu'à 10 fois.
Chen Goldberg, vice-présidente senior de l'ingénierie chez CoreWeave, déclare : « Alors que l'inférence devient centrale pour la production d'IA, les performances en contexte long et l'efficacité par token deviennent cruciales. Grace Blackwell NVL72 relève directement ce défi, et le cloud IA de CoreWeave est conçu pour traduire les gains des systèmes GB300 en performances prévisibles et en efficacité des coûts. Le résultat est une meilleure économie des tokens, offrant une inférence plus accessible aux clients exécutant des charges de travail à grande échelle. »
Les données de SemiAnalysis indiquent que les hyperscalers accélèrent leur transition vers des infrastructures optimisées pour l'inférence. La feuille de route de NVIDIA – de Hopper à Blackwell Ultra et à l'architecture Rubin à venir – positionne le débit par mégawatt et l'économie des tokens comme des indicateurs de compétition majeurs, un domaine sur lequel les concurrents, y compris AMD, se concentrent de plus en plus.











