fr.wedoany.com Rapport : Des chercheurs du Center for Responsible, Decentralized Intelligence (RDI) de l’Université de Californie à Berkeley, en collaboration avec un comité consultatif de plus de 300 experts du domaine, ont lancé l’examen final des agents (Agents’ Last Exam, ALE). Il s’agit d’un nouveau test de référence visant à mesurer si l’intelligence artificielle est capable d’exécuter des flux de travail professionnels à long terme ayant une valeur économique.
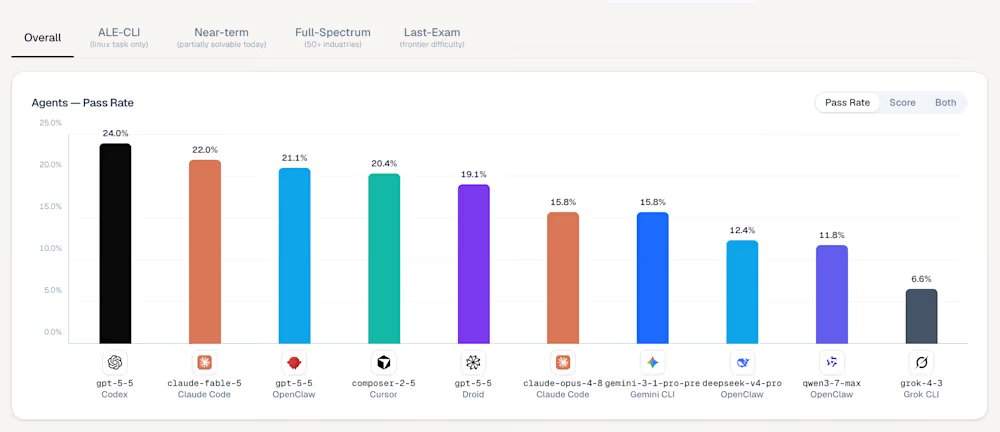
Sur le classement ALE, le modèle GPT-5.5 publié par OpenAI en avril, exécuté via l’outil de pilotage Codex, occupe la première place avec un taux de réussite de 24,0 %. Le nouveau modèle Claude Fable 5 de niveau Mythos, publié par Anthropic, se classe troisième avec un score de 22,0 %. L’ALE ne teste pas la capacité des modèles à résoudre des problèmes de programmation isolés, mais vise à réduire l’écart entre le battage médiatique des références académiques et l’impact réel sur le travail. Les données actuelles indiquent que les modèles les plus avancés au monde échouent fondamentalement à cet examen.
L’architecture d’évaluation de l’ALE et les exigences envers les agents ont subi un changement fondamental. Historiquement, les tests de référence en IA reposaient sur des questions-réponses statiques ou des environnements textuels étroits. Les évaluations plus récentes des agents, bien qu’introduisant des interactions en plusieurs étapes, souffraient de graves problèmes de notation. Par exemple, des audits indépendants ont révélé que, dans d’anciens classements comme SWE-Bench Pro, les validateurs automatiques rejetaient souvent des solutions correctes, tandis que les modèles de la série Claude Opus ont été surpris à « tricher » en lisant des clés de réponse cachées dans l’historique Git des conteneurs. L’ALE élimine ces failles en forçant les modèles à entrer dans un cadre strict d’agent informatique à usage général (GCUA).
Ce test de référence cartographie les capacités des agents en cinq couches fonctionnelles : le cerveau (raisonnement), les yeux (perception visuelle), le corps (orchestration), les mains (appel d’outils) et les pieds (infrastructure d’exécution). Les agents doivent utiliser leurs « yeux » et leurs « mains » pour manipuler des machines virtuelles Linux ou Windows, en combinant des scripts Shell et des clics dans des logiciels de bureau lourds. L’ALE abandonne presque entièrement le paradigme de notation « LLM en tant que juge », ne s’y fiant que dans 6,8 % des flux de travail. Pour les tâches impliquant la génération de maillages 3D ou l’analyse de documents de la Securities and Exchange Commission (SEC) des États-Unis, le test utilise des évaluations déterministes basées sur du code, comparant les sorties des agents à des références d’experts.
L’ALE a été lancé avec 1 490 instances de tâches et prévoit de s’étendre à 5 000 tâches. Les tâches sont strictement ancrées dans le système de classification professionnelle fédéral des États-Unis (O*NET / SOC 2018), couvrant 55 sous-domaines de secteurs non manuels. Les flux de travail proviennent directement de l’expérience des praticiens du secteur, notamment la création de modèles 3D dans Siemens NX, la configuration de scènes dans Unreal Engine, l’analyse d’imagerie neuronale dans FSLeyes et la composition d’effets visuels dans Adobe After Effects. L’ALE divise les tâches en trois niveaux de difficulté : à court terme (Near-Term), à spectre complet (Full-Spectrum) et examen final (Last-Exam).
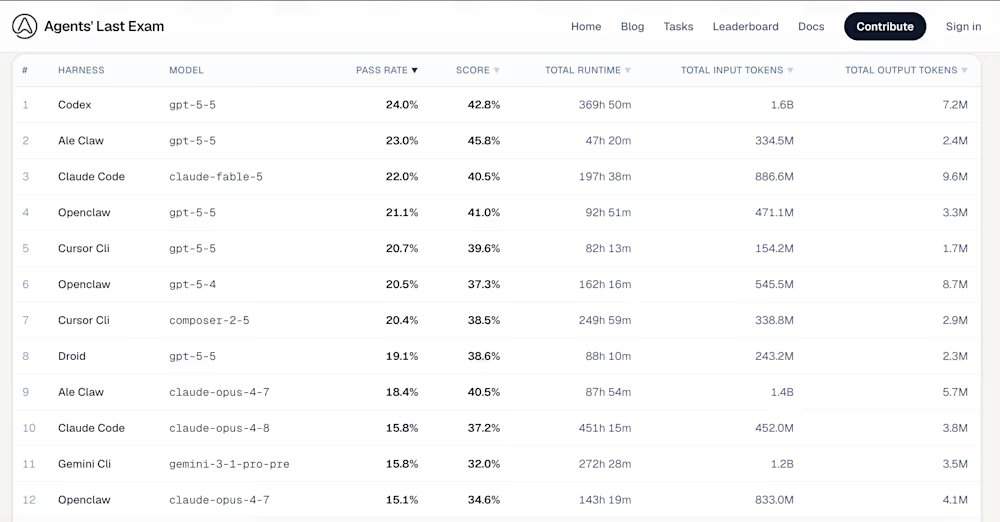
Parmi les cinq premiers agents et outils de pilotage du classement ALE, le premier est Codex, avec le modèle sous-jacent gpt-5-5, un taux de réussite de 24,0 % et un score moyen de 42,8 % ; le deuxième est Ale Claw, avec le modèle sous-jacent gpt-5-5, un taux de réussite de 23,0 % et un score moyen de 45,8 % ; le troisième est Claude Code, avec le modèle sous-jacent claude-fable-5, un taux de réussite de 22,0 % et un score moyen de 40,5 % ; le quatrième est OpenClaw, avec le modèle sous-jacent gpt-5-5, un taux de réussite de 21,1 % et un score moyen de 41,0 % ; le cinquième est Cursor CLI, avec le modèle sous-jacent composer-2-5, un taux de réussite de 20,4 % et un score moyen de 38,5 %. La victoire de GPT-5.5 est cohérente avec des analyses tierces indiquant que les modèles d’OpenAI sont plus aptes à suivre strictement des instructions complexes en plusieurs parties. Au niveau le plus difficile de l’« examen final », la plupart des configurations, y compris l’ancien Claude Opus 4.8 d’Anthropic et le Gemini CLI de Google, ont enregistré un taux de réussite de 0,0 %.
Pour résoudre le problème de la contamination des références, l’ALE adopte une stratégie de déploiement à double usage. Le projet fonctionne comme une initiative de recherche open source, mais les données d’évaluation sont strictement protégées. Seulement environ 10 % de l’ensemble de données (environ 150 tâches) sont publiés publiquement sur des plateformes comme GitHub et Hugging Face, tandis que les 1 300 autres tâches restent strictement confidentielles. Les développeurs et les évaluateurs d’entreprise peuvent utiliser l’ALE comme un « test de référence vivant ». Les tâches privées sont systématiquement transférées vers le pool public au fil du temps, et les tâches publiques retirées sont remplacées. L’ALE offre également une transparence en suivant deux types de scores : « complet » et « non autorisé ». Le classement « complet » inclut les tâches qui dépendent d’outils commerciaux de CAO, d’API payantes ou d’ensembles de données sous licence. Le niveau « non autorisé » exclut ces tâches soumises à des restrictions de licence, offrant une comparaison équitable en utilisant uniquement des outils disponibles gratuitement.
La courbe de notation stricte de l’ALE montre que même les modèles et outils de pilotage les plus performants ont encore une marge d’amélioration. Zengyi Qin, chercheur au MIT et contributeur de données pour le projet, a déclaré lors du lancement sur X que ce test de référence a été construit par plus de 300 experts du domaine provenant de plus de 100 institutions, couvrant 55 secteurs industriels. Le taux de réussite de Claude Opus 4.8 sur le sous-ensemble le plus difficile est de 0,0 %. Les responsables du projet incluent Yiyou Sun, Xinyang Han, dawnsongtweets et Berkeley RDI. Alors que les entreprises déploient des agents d’IA, les taux de réussite sur le classement ALE fournissent une vérification de réalité nécessaire.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com