fr.wedoany.com Rapport : La robotique a été au cœur des débats lors de la conférence Zhiyuan de Pékin en juin. Au cours de l’année écoulée, avec l’essor du secteur robotique, l’industrie s’interroge sur la voie à suivre : VLA (Vision-Langage-Action) ou modèle du monde. Le Dr Guo Yandong, fondateur et PDG de Zhiping², a apporté une réponse claire lors du discours d’ouverture du forum des PDG de l’industrie de la robotique incarnée : le modèle du monde n’est pas une alternative concurrente au VLA, mais un élément central de son système ; une fois fusionnés, l’architecture cérébrale biomimétique deviendra une direction majeure pour la prochaine génération de cerveaux robotiques.

Cette position repose sur les trois dernières années de développement technologique de Zhiping². Selon Guo Yandong, d’un point de vue évolutif, la capacité d’action n’émerge pas isolément ; la perception et la compréhension de l’environnement précèdent l’action. Il redéfinit le VLA comme une architecture de modèle de bout en bout, pilotée par de grandes données et fusionnant plusieurs modalités, estimant qu’il n’y a pas de différence fondamentale entre le modèle du monde et le VLA, ni de relation de substitution. Le modèle du monde résout la prédiction dense et temporelle en 4D de l’environnement physique, faisant partie de la perception spatiale du VLA et améliorant les capacités du cerveau robotique. Guo Yandong illustre la nécessité de leur fusion : pour préparer du thé, il faut d’abord prendre le sachet, puis verser l’eau – une logique de raisonnement qui dépend du modèle de langage, tandis que le modèle du monde excelle dans les prédictions à court terme, comme le risque qu’une tasse tombe en s’approchant du bord de la table. Leur combinaison permet au robot de posséder à la fois des capacités de prédiction physique à court terme et de planification de tâches à long terme. Zhiping² utilise également le modèle du monde pour générer des données marginales difficiles à collecter dans des environnements réels, afin de compléter l’entraînement du VLA.
Sur cette base, Zhiping² a lancé en novembre 2025, en collaboration avec l’Université de Pékin, une nouvelle génération d’architecture intégrant le modèle du monde : Video2Act, réalisant pour la première fois un paradigme de modèle robotique « prédire d’abord, exécuter ensuite ». Video2Act n’est pas un modèle de génération vidéo traditionnel, mais une architecture VLA intégrant un modèle du monde en 4D. Grâce à la modélisation d’informations spatiales denses et à l’entrée continue de séquences d’actions, le robot peut anticiper les changements d’état futurs et transformer les capacités de prédiction en décisions d’action. Lors d’évaluations tierces, Video2Act a obtenu une amélioration des performances de plus de 30 % par rapport aux modèles les plus avancés de la Silicon Valley. Dans la revue de référence sur les modèles du monde, « World Model for Robot Learning: A Comprehensive Survey », co-rédigée par des sommités mondiales telles que Philip Torr, membre des deux académies royales britanniques et chercheur de renommée mondiale en intelligence artificielle, et Pieter Abbeel, pionnier de l’apprentissage par renforcement, Video2Act est cité comme un résultat représentatif de la « fusion modèle du monde + VLA ».

Après avoir résolu la fusion entre le modèle du monde et le VLA, Zhiping² s’est concentré sur le défi de permettre aux robots d’agir de manière stable et efficace, à l’instar des humains. Lors de la conférence Zhiyuan, Guo Yandong a présenté le dernier système d’intelligence incarnée biomimétique de Zhiping², NeuroVLA. Il s’agit du seul système d’intelligence incarnée capable de combiner trois capacités biologiques motrices : la perception active, l’auto-récupération après panne et la mémoire temporelle. Guo Yandong a souligné que, bien que les robots dotés des architectures VLA actuelles possèdent une forte capacité de compréhension, ils souffrent encore de lenteurs de réponse, de tremblements dans les mouvements et d’une consommation énergétique élevée dans des environnements réels complexes, car la plupart des robots s’appuient sur un seul grand modèle pour gérer simultanément la perception, le raisonnement et le contrôle.
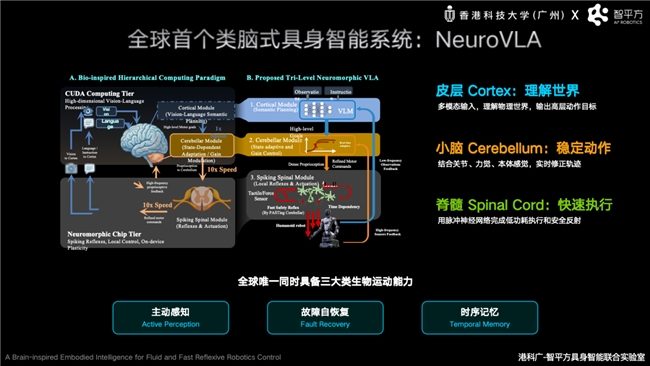
S’inspirant du mécanisme humain où le cortex cérébral gère la réflexion, le cervelet coordonne les mouvements et la moelle épinière assure les réflexes instinctifs, Zhiping² a construit une architecture cérébrale biomimétique à trois niveaux, une première mondiale : « cortex – cervelet – moelle épinière », baptisée NeuroVLA. Le cortex est responsable de la compréhension sémantique et de la planification des tâches, le cervelet de la coordination motrice à haute fréquence et des corrections dynamiques, et la moelle épinière de l’exécution motrice à l’échelle milliseconde et des réflexes de sécurité. Cette conception améliore la stabilité, la réactivité en temps réel et l’efficacité énergétique du robot dans le monde physique réel. Les résultats expérimentaux montrent que NeuroVLA réduit les tremblements des mouvements du robot de plus de 75 %, déclenche une réponse réflexe en moins de 20 millisecondes après une collision et réduit considérablement la consommation électrique du système.

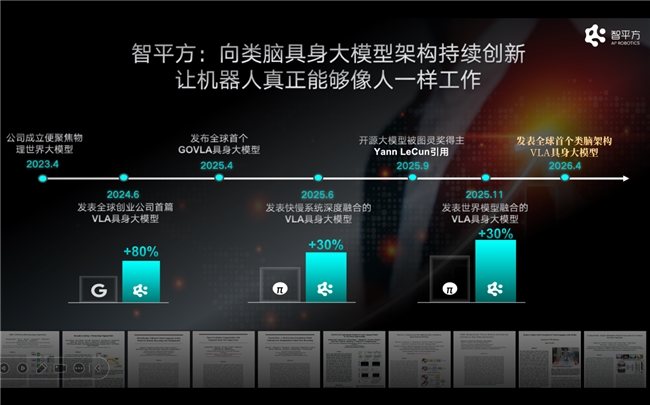
Du VLA de bout en bout à Video2Act, puis à NeuroVLA, Zhiping² a poursuivi une innovation systématique autour du cerveau robotique au cours des trois dernières années. Cette trajectoire d’évolution suit une direction unique : doter le robot d’un « cerveau » plus proche de celui de l’humain.