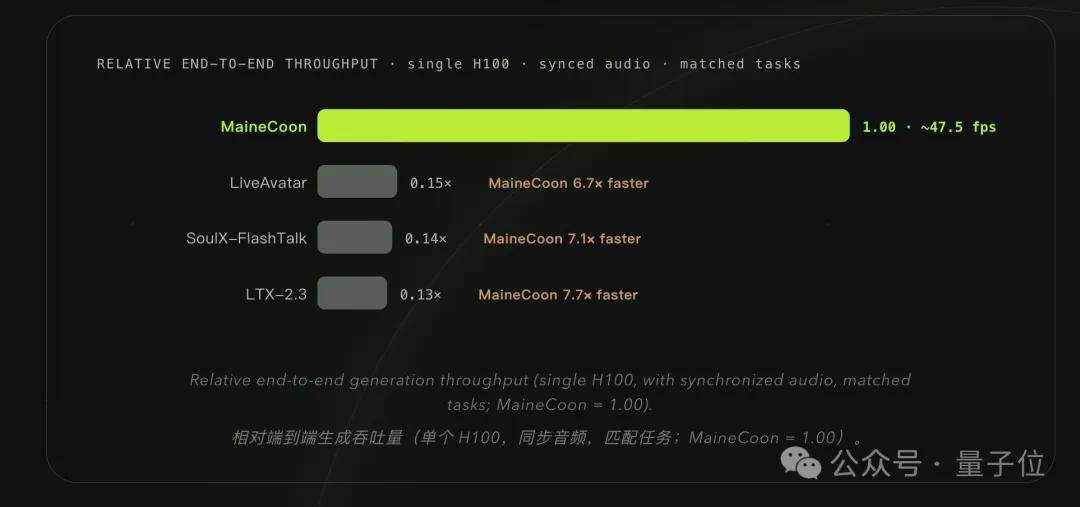
fr.wedoany.com Rapport : La startup chinoise Catnip a récemment lancé le modèle audio-vidéo en streaming MaineCoon, capable de générer en temps réel des contenus audio et vidéo synchronisés d’une durée maximale de 30 minutes. Avec une vitesse d’inférence de 47,5 FPS sur une seule carte H100, le coût par seconde peut être maintenu en dessous de 0,001 dollar.
MaineCoon a été développé par une équipe de seulement 10 personnes chez Catnip, dont le siège est situé en Chine. Le projet a officiellement démarré en mars de cette année, et trois chercheurs principaux ont réalisé en deux mois la livraison complète de la pile, incluant l’entraînement du modèle, la conception de l’architecture, l’infrastructure de données et le système d’inférence.
Contrairement aux modèles traditionnels de génération audio-vidéo, MaineCoon est le premier à se concentrer sur les interactions sociales. Il prend en charge la lecture en continu pendant la génération, avec une sortie simultanée de l’audio et de la vidéo. La première image apparaît dans la seconde suivant l’émission de la commande. En utilisation maximale du GPU, le coût d’inférence par seconde peut descendre à 0,00025 dollar, soit 1/2000 de celui de Veo 3 et 1/560 de celui de Seedance. Avec 22 milliards de paramètres, le modèle fonctionne de manière stable sur une seule carte H100, et maintient une vitesse en temps réel supérieure à 30 FPS même sur la carte d’inférence RTX Pro 6000, moins coûteuse.

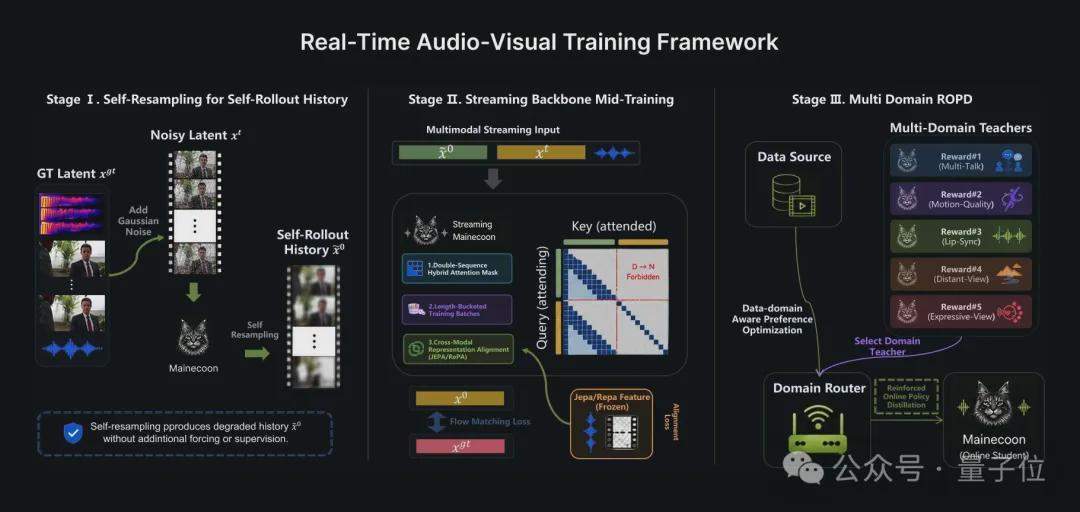
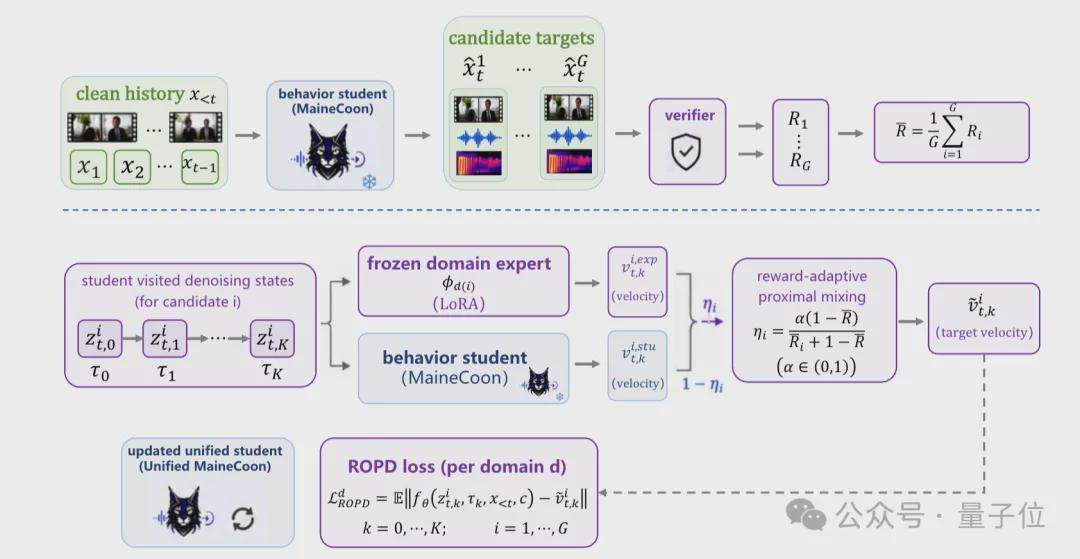
L’équipe de Catnip a détaillé l’architecture d’entraînement et d’inférence de MaineCoon dans un rapport technique. Le cadre d’entraînement se décompose en trois phases : le rééchantillonnage automatique (Self-Resampling) résout le fossé entre l’entraînement et l’inférence ; l’alignement des représentations en streaming (Representation Alignment) accélère la convergence de l’entraînement conjoint audio-vidéo en gelant l’encodeur visuel pré-entraîné V-JEPA 2 ; l’optimisation préférentielle par domaine (DPO), combinée à la distillation en ligne par stratégie renforcée (ROPD), entraîne des modèles experts de préférence spécifiques à différents scénarios sociaux. L’ensemble du modèle a été entraîné sur 64 cartes H100 avec moins d’un million de données, en 10 000 heures GPU.
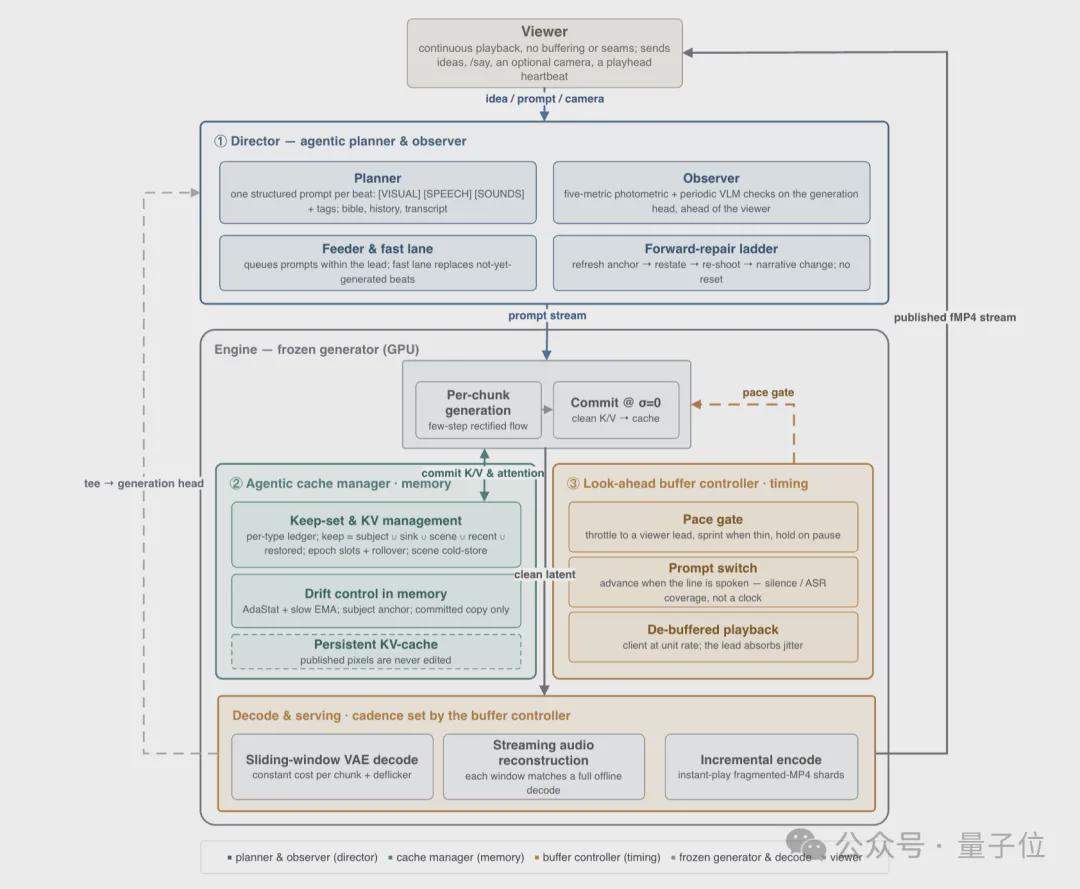
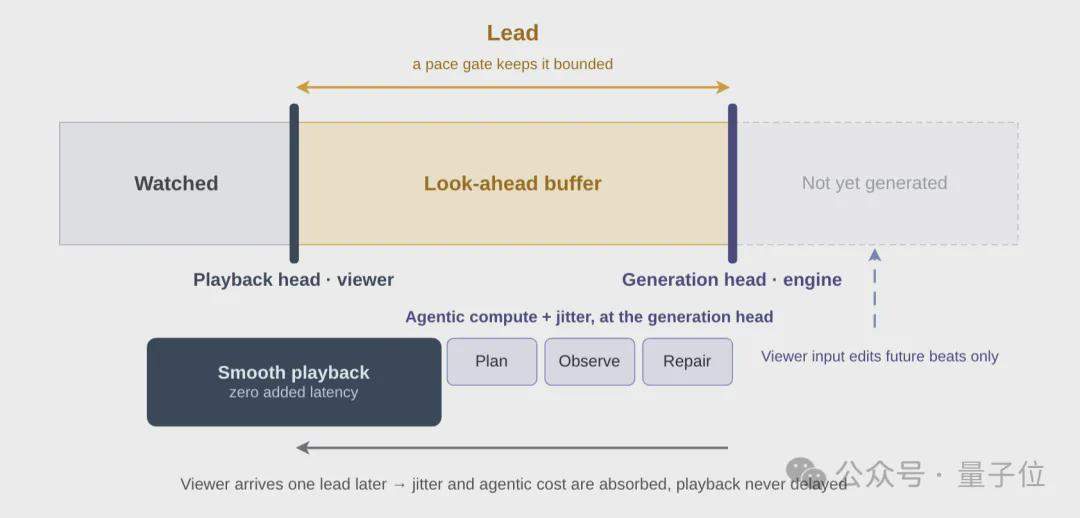
Côté inférence, un cadre Agentic composé de trois contrôleurs intelligents indépendants est utilisé : le Director gère la narration et la correction, générant des invites structurées battement par battement via un planificateur et surveillant la qualité de la génération via un observateur ; le Cache Manager gère les stratégies de conservation et de suppression du cache KV, en utilisant l’apparence des personnages et les images d’établissement de scène comme points d’ancrage de la mémoire à long terme ; le Buffer Controller contrôle la zone tampon prospective, équilibrant la réactivité en temps réel et l’interactivité.
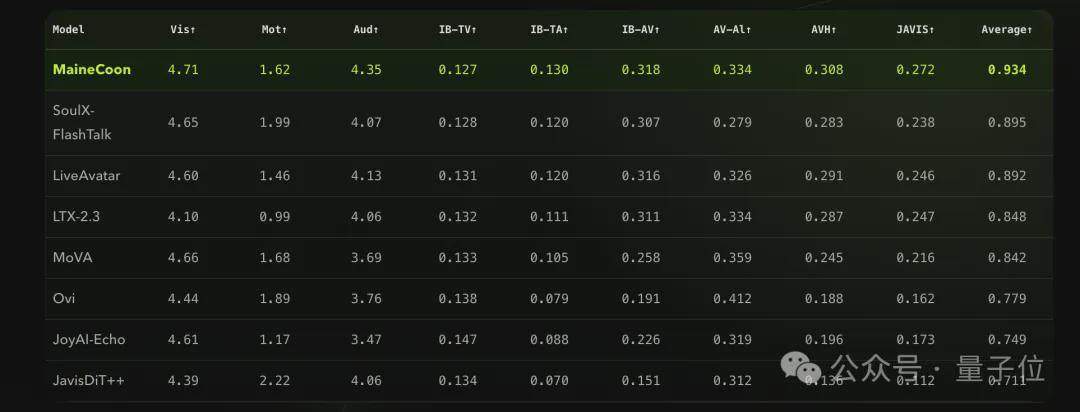
L’équipe de Catnip a également créé le premier benchmark dédié aux vidéos courtes sociales, SocialVideo Bench, couvrant sept scénarios : discours denses, interactions en duo, chant musical, performances émotionnelles, danse, défis créatifs et mèmes sociaux. Les évaluations montrent que MaineCoon obtient un score global de 0,934, surpassant sept modèles de génération audio-vidéo grand public, dont SoulX-FlashTalk (0,895).
L’équipe de Catnip a proposé pour la première fois le concept de « modèle de monde social », qu’elle considère comme comprenant trois niveaux : la couche perceptive (comprendre les émotions des utilisateurs), la couche de simulation (prédire les comportements sociaux) et la couche de rendu (générer en temps réel l’audio et la vidéo). MaineCoon est considéré comme une avancée au niveau du rendu. L’équipe prévoit de dépasser le mode d’interaction semi-duplex des dialogues IA traditionnels pour réaliser une interaction bidirectionnelle en temps réel, continue, entrelacée et multimodale, à l’image des humains, et de faire évoluer le modèle vers une plateforme de contenu interactive.
La fondatrice de l’équipe, Yang Shurui, a précédemment travaillé chez TikTok et PixVerse, où elle était responsable du déploiement de produits d’effets de modèles viraux, et possède une expérience d’entrepreneuriat en série. Le scientifique en chef, Xie Zeke, est professeur assistant à l’Université des Sciences et Technologies de Hong Kong (Canton), titulaire d’une licence de l’Université des Sciences et Technologies de Chine et d’un doctorat de l’Université de Tokyo. Il a participé à la recherche de pointe sur les grands modèles à l’Institut de Recherche Baidu et est depuis longtemps président de domaine pour les conférences majeures d’IA comme NeurIPS, ICLR et ICML. Les autres membres de l’équipe sont principalement des diplômés récents.
L’équipe de Catnip a précédemment publié le rapport technique sur la plateforme sociale X, attirant immédiatement l’attention de multiples parties, et l’équipe officielle de LTX a également cherché activement une collaboration. L’équipe a révélé avoir obtenu en début d’année des financements d’amorçage en série auprès d’investisseurs institutionnels tels que Sequoia et Mingshi.