fr.wedoany.com Rapport : L'équipe Qwen d'Alibaba a dévoilé Qwen-AgentWorld, comprenant deux modèles qui ne sont pas conçus pour exécuter des actions dans des environnements d'agents, mais pour prédire les résultats renvoyés par ces environnements, couvrant sept domaines : MCP, recherche, terminal, génie logiciel, Android, Web et systèmes d'exploitation.
Cette publication s'inscrit dans la continuité des récents investissements d'Alibaba dans les agents autonomes, le modèle Qwen3.7-Max, publié en mai, étant construit autour d'une capacité d'exécution autonome de 35 heures. L'équipe souligne que le principal goulot d'étranglement de l'entraînement des agents à grande échelle réside dans les limites de l'entraînement en environnement réel : les moteurs de recherche ne peuvent pas injecter de conditions contrôlées, les terminaux en temps réel ne permettent pas de simuler à la demande des cas limites comme un faible espace disque, et les agents ont du mal à être systématiquement exposés à des scénarios rares.
L'équipe de recherche a entraîné des agents dans des simulateurs générés et a constaté que leurs performances étaient supérieures à celles obtenues avec un entraînement uniquement basé sur des environnements réels. Dans un autre test, l'utilisation de l'entraînement du modèle du monde comme étape de préchauffage avant le réglage fin de l'agent a amélioré les performances sur sept benchmarks, dont trois jamais vus lors de l'entraînement. L'article accompagnant la publication indique que la modélisation du monde est un élément clé pour parvenir à des agents universels.
Contrairement aux modèles d'agents traditionnels qui optimisent la sélection d'actions, Qwen-AgentWorld est entraîné à répondre à la question inverse : étant donné l'action que l'agent vient d'effectuer, qu'affichera l'environnement ensuite ? L'article qualifie cette approche de « modèle de langage du monde », le modèle apprenant à prédire l'état suivant de l'environnement dans les sept domaines avec un seul objectif d'entraînement. Les recherches précédentes dans ce domaine étaient plus restreintes, comme WebWorld publié par Qwen en février, qui ne couvrait que l'environnement web ; ou Agent World Model publié par Snowflake le même mois, qui générait un environnement de support SQL basé sur du code, sans entraîner le modèle à prédire les états. Qwen-AgentWorld est le premier modèle à couvrir sept domaines dans un seul modèle et à intégrer la modélisation de l'environnement dès la phase de pré-entraînement la plus précoce.
Le processus d'entraînement a utilisé plus de dix millions de traces d'interactions environnementales provenant d'opérations d'agents réels, divisé en trois phases : la première phase enseigne au modèle le fonctionnement de l'environnement, y compris le système de fichiers, l'état du terminal, les modifications du DOM du navigateur et les réponses API ; la deuxième phase entraîne le modèle à raisonner sur l'état suivant avant de faire une prédiction ; la troisième phase, via l'apprentissage par renforcement, resserre les prédictions en utilisant des vérifications basées sur des règles et une évaluation ouverte de la qualité. Les deux modèles adoptent une conception de mélange d'experts, où seule une petite partie des paramètres est activée pour chaque token. Le modèle 35B active 3B, le 397B active 17B, et les deux prennent en charge une fenêtre de contexte de 256K. Pour les domaines GUI (Android, Web et systèmes d'exploitation), les modèles travaillent à partir d'arbres d'accessibilité textuels et de hiérarchies de vues UI, et non de captures d'écran. Les poids du modèle 35B et AgentWorldBench sont disponibles sous licence Apache 2.0 ; les poids du modèle 397B n'ont pas encore été rendus publics.
Les scores des benchmarks montrent la précision avec laquelle le modèle prédit le contenu renvoyé par l'environnement, mais les résultats de l'entraînement révèlent la valeur réelle de cette capacité prédictive pour la construction d'équipes d'agents, ces chiffres étant plus importants. Selon les chercheurs, les agents entraînés dans des simulations contrôlées surpassent ceux entraînés dans des environnements réels. L'injection de perturbations dirigées a fait passer MCPMark de 24,6 à 33,8. Dans les tâches de recherche, les agents entraînés dans des mondes entièrement fictifs, transférés à des tâches de recherche réelles, ont amélioré le WideSearch F1 Item sur le modèle open source 35B de 34,02 à 50,31. Les tests de préchauffage montrent que le pré-entraînement du modèle du monde a fait passer BFCL v4 de 62,29 à 71,25 et Claw-Eval de 53,60 à 64,88, sans aucun réglage fin spécifique à l'agent.
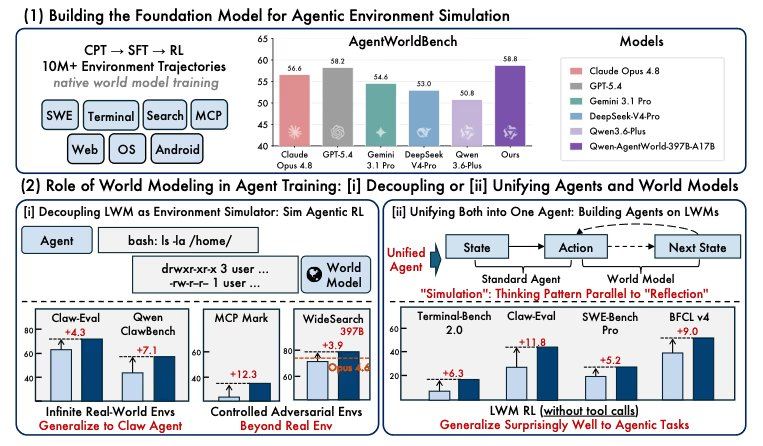
La publication de l'article a suscité des discussions parmi les chercheurs en IA. Certains estiment que Qwen a inversé le problème central en entraînant le modèle à prédire l'environnement lui-même, ces connaissances prédictives étant ensuite transférées aux tâches d'agent, même sans réglage fin spécifique à l'agent. D'autres chercheurs notent qu'AgentWorldBench est un benchmark construit et publié par Alibaba dans le même article, et que lors des tests, son modèle l'a emporté avec une marge de 0,46, ce qui pourrait soulever des questions sur l'indépendance des critères d'évaluation. Le problème traditionnel des méthodes RL basées sur la simulation est que les agents ont tendance à surajuster les caractéristiques du simulateur ; si le modèle du monde est trop propre, l'agent apprend le modèle plutôt que la tâche. Les divisions de retrait et les résultats de données dans l'article répondent en partie à ces préoccupations, les résultats de recherche dans des mondes fictifs montrant que les agents entraînés dans ces environnements peuvent être transférés à des tâches de recherche réelles.
Pour les équipes qui construisent et étendent des pipelines d'agents, ce travail offre une troisième option : des simulations contrôlées qui injectent des cas limites qui ne se produisent pas dans l'environnement de production. Les environnements synthétiques constituent une couche d'entraînement légitime, un complément à la RL en environnement réel, et non un raccourci pour la contourner. La mise en base de l'environnement avant l'entraînement de l'agent intervient plus tôt dans le processus de développement que la plupart des pratiques actuelles, permettant d'améliorer les performances sur plusieurs benchmarks sans nécessiter d'entraînement spécifique à l'agent. Ce que le modèle apprend avant l'entraînement est bien plus important que ce que la plupart des pipelines prennent en compte.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com