fr.wedoany.com Rapport : La société française d’intelligence artificielle Mistral AI a dévoilé mardi son modèle de reconnaissance optique de caractères de quatrième génération, OCR 4. Sa capacité principale ne se limite pas à l’extraction de texte, mais permet également de renvoyer une représentation structurée du document, comprenant des boîtes englobantes, une classification par type de bloc et des scores de confiance mot par mot. Le produit cible le marché des déploiements d’entreprise auto-hébergés dans les secteurs réglementés, où les entreprises ne peuvent pas confier leurs documents sensibles à des fournisseurs de services cloud soumis à la juridiction américaine.

OCR 4 prend en charge 170 langues réparties dans 10 familles linguistiques et peut traiter les formats PDF, DOC, PPT et OpenDocument. Mistral indique que les générations précédentes convertissaient principalement les pages en texte et tableaux propres, tandis qu’OCR 4 renvoie directement une représentation structurée du document. Le modèle est déjà disponible via l’API Mistral, Document AI dans Mistral Studio, Amazon SageMaker et Microsoft Foundry, avec un support prochain pour Snowflake Parse Document. Le prix de départ est de 4 dollars pour 1 000 pages, avec un tarif réduit de 2 dollars pour 1 000 pages via l’API batch.
Le cœur technique d’OCR 4 réside dans la production d’une représentation hiérarchique du document, plutôt qu’un flux de texte plat. Chaque bloc de texte est accompagné d’un positionnement par boîte englobante, d’une classification par type (par exemple, titre, tableau, formule, signature) et de scores de confiance au niveau de la page et du mot. Mistral précise que les boîtes englobantes sont la fonctionnalité la plus demandée par les clients, car elles permettent aux systèmes en aval de retracer les informations extraites jusqu’à des positions spécifiques sur la page. La fonction de classification des blocs permet d’utiliser les paragraphes de titre pour la segmentation hiérarchique dans la recherche sémantique, d’acheminer les blocs de tableau vers des pipelines de données structurées, et les blocs de signature peuvent déclencher des workflows d’édition dans les systèmes de conformité. Les scores de confiance permettent aux organisations de soumettre programmatiquement les zones à faible confiance à une vérification humaine, tout en approuvant automatiquement les extractions à haute confiance.
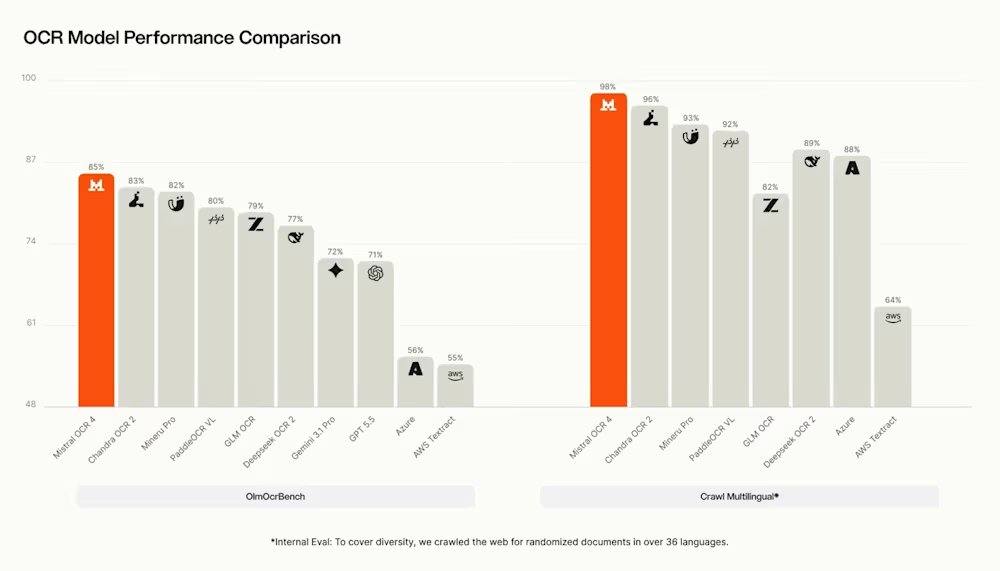
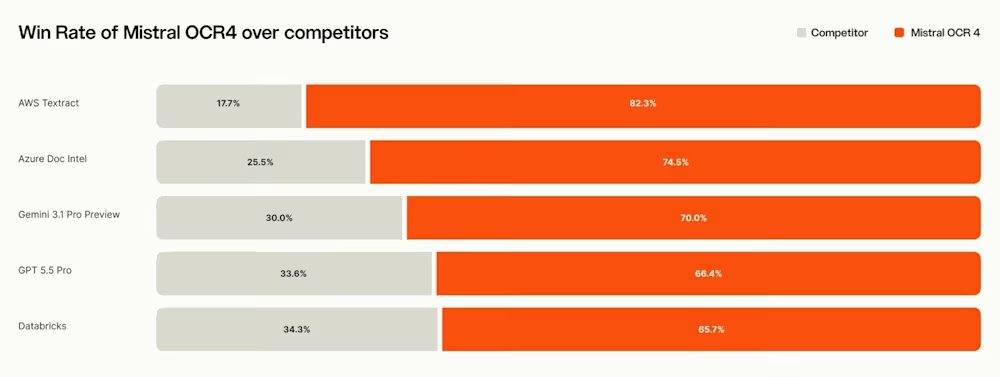
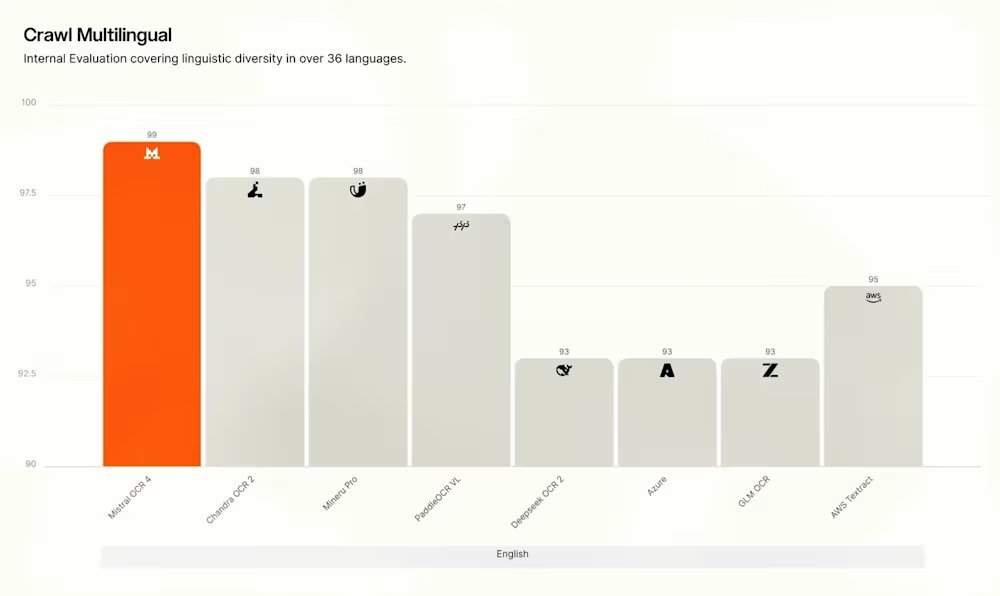
Dans des évaluations indépendantes, Mistral rapporte qu’une évaluation humaine menée par des annotateurs indépendants sur plus de 600 documents réels dans plus de 12 langues montre qu’OCR 4 atteint un taux de victoire moyen de 72 % en comparaison directe avec ses principaux concurrents. Le modèle obtient un score de 85,20 sur OlmOCRBench et de 93,07 sur OmniDocBench. Cependant, Mistral a également audité et divulgué publiquement des artefacts dans les scores, notamment des erreurs dans les annotations de référence, des problèmes de correspondance des symboles LaTeX, des hypothèses sur l’ordre de lecture des colonnes, et considère que les scores totaux sont indicatifs plutôt que définitifs. Il est à noter que sur le classement public OlmOCRBench, OCR 4 se classe actuellement troisième, derrière certains modèles à poids ouverts comme Chandra OCR 2. PaddleOCR-VL-1.6 revendique un score composite de 96,33 sur OmniDocBench.
Les retours précoces des entreprises fournissent des données concrètes. Aidan Donohue, ingénieur en IA chez Rogo, une société de finance IA, déclare que sur un ensemble de données de questions-réponses financières riches en graphiques, OCR 4 atteint « une précision équivalente à celle des analyseurs de documents agents leaders, avec une réduction des coûts d’environ 8 fois et une réduction de la latence d’environ 17 fois ». Ivan Mihailov, ingénieur en IA chez Anaqua, une société de gestion de propriété intellectuelle, indique que la « vitesse par page d’OCR 4 est environ 4 fois supérieure à celle des fournisseurs existants ».
Le contexte géopolitique de ce lancement est la désactivation par Anthropic le 12 juin de ses derniers modèles Fable 5 et Mythos 5 en raison des contrôles à l’exportation américains, provoquant une interruption de service pour les clients entreprises dans les secteurs financier, médical et des infrastructures critiques. Cet événement a validé les avertissements d’Arthur Mensch, PDG de Mistral, sur les risques de dépendance de l’Europe vis-à-vis des entreprises américaines d’IA. Mensch avait déclaré que les entreprises américaines « détiennent la clé de leurs modèles » et a récemment souligné que « l’Europe est en retard dans la construction d’infrastructures, donc nous investissons pour combler cet écart ». Le déploiement auto-hébergé en conteneur unique d’OCR 4 permet aux documents de ne jamais quitter l’infrastructure du client, fonctionnant entièrement sous la juridiction de l’UE.
La veille du lancement de Mistral, Baidu a dévoilé un modèle de 3 milliards de paramètres appelé Unlimited-OCR, sous licence MIT avec poids ouverts gratuits. Ce modèle utilise une technique appelée attention à fenêtre glissante de référence (R-SWA), capable d’analyser un PDF entier et des scans multipages en une seule passe avant, sans nécessiter de découpage ou d’assemblage. Ces deux lancements sont considérés par les analystes comme une divergence de deux modèles dans le domaine de l’IA documentaire en juin 2026 : l’analyse longue distance auto-hébergée à poids ouverts et l’extraction structurée hébergée commerciale. Pour les équipes de recherche sur un seul GPU, Unlimited-OCR pourrait être plus approprié, tandis qu’OCR 4 cible les accords de niveau de service, les accords de traitement de données et les audits de conformité impliqués dans les processus d’achat informatique des entreprises.
D’un point de vue industriel, OCR 4 est le point d’entrée de Mistral dans les budgets d’IA des entreprises. Le modèle prend directement en charge le Search Toolkit de Mistral, un framework de recherche open source et composable. Sur le plan architectural, OCR 4 sert de couche d’extraction pour les pipelines de génération augmentée de récupération et de recherche d’entreprise. Bloomberg a récemment rapporté que Mistral est en négociations préliminaires pour lever environ 3 milliards d’euros à une valorisation d’environ 20 milliards d’euros. La société vise un chiffre d’affaires de 1 milliard d’euros en 2026. Le PDG de Mistral a également récemment répondu à l’appel du pape à « désarmer » l’IA, estimant que l’Europe ne peut pas prendre de retard sur les géants technologiques américains et doit posséder ses propres capacités en IA.