
fr.wedoany.com Rapport : Artificial Analysis a lancé le premier benchmark d'IA autonome du secteur, AgentPerf, offrant aux développeurs, entreprises et fournisseurs d'infrastructures une méthode standardisée pour comparer les systèmes d'IA autonome. Les premiers résultats montrent que la plateforme NVIDIA Blackwell Ultra NVL72 affiche des performances de pointe dans les charges de travail d'IA autonome, avec un nombre d'agents par mégawatt 20 fois supérieur à celui des systèmes NVIDIA Hopper.

Les charges de travail d'IA autonome diffèrent fondamentalement de l'IA conversationnelle. Une conversation terminée ressemble à un sprint, nécessitant un seul appel LLM et une seule réponse. En revanche, un agent s'apparente davantage à une course de relais : il décompose un objectif en plusieurs étapes et continue jusqu'à ce que la tâche soit accomplie.
Ce modèle entraîne des dizaines, voire des centaines d'appels LLM enchaînés, chaque appel transmettant un contexte croissant au suivant, et chaque transition impliquant des appels d'outils tels que la compilation et l'exécution de code, la recherche dans des bases de données et la navigation web. La complexité n'est pas additive, mais multiplicative.
Cette distinction est cruciale pour la mesure des performances. Les benchmarks d'inférence IA existants mesurent un seul appel LLM, c'est-à-dire la vitesse de réponse du LLM à une requête unique et le nombre de requêtes que le système peut traiter simultanément. Ils ne sont pas conçus pour les charges de travail autonomes, car les appels LLM en chaîne, la latence des appels d'outils et le contexte croissant exercent une pression sur les systèmes de calcul accéléré bien différente d'un seul appel LLM.
Pour les entreprises qui construisent et déploient des agents à grande échelle, il est essentiel de comprendre la vitesse de réponse des agents, le nombre d'agents pouvant être déployés simultanément, et le travail utile accompli par dollar investi et par watt d'énergie consommé dans l'infrastructure IA.
Lors des premiers tests, AgentPerf a utilisé DeepSeek V4 Pro (un grand modèle à experts mixtes, représentant la catégorie de modèles de pointe qui alimentent actuellement les agents les plus performants) pour mesurer les performances autonomes. Sous cette charge de travail, le NVIDIA GB300 NVL72 a obtenu les meilleures performances du benchmark, avec un nombre d'agents par mégawatt 20 fois supérieur à celui du système NVIDIA HGX H200.
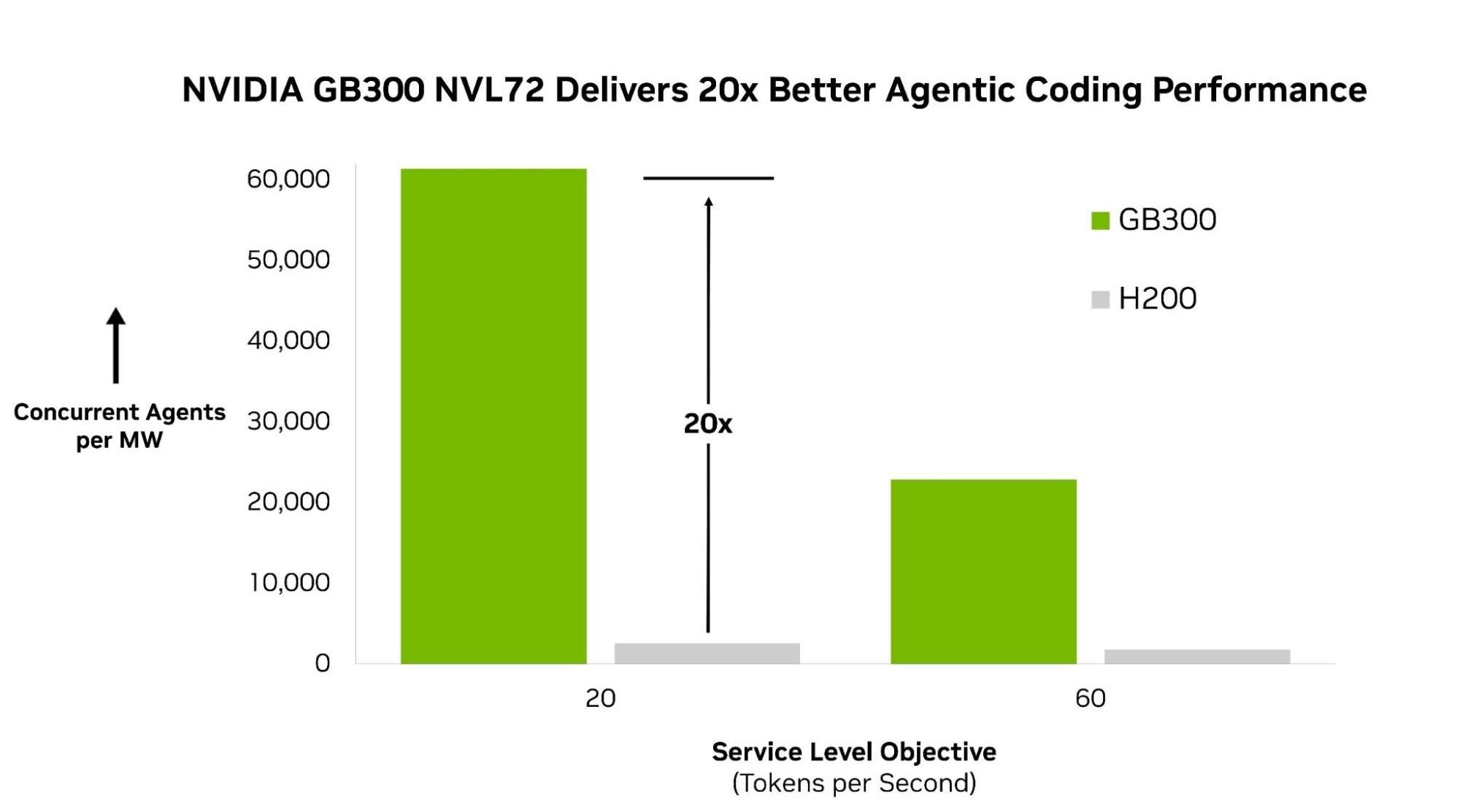
Cet avantage de performance provient d'une conception de synergie extrême à l'échelle de la pile complète. Le GB300 NVL72 connecte 72 GPU en un système au niveau du rack, permettant aux grands modèles MoE comme DeepSeek V4 Pro d'être exécutés efficacement à grande échelle de manière distribuée. Les noyaux CUDA accélèrent encore le processus en superposant la communication et le calcul, de sorte que le coût de coordination entre experts est absorbé sans ajouter de latence. À mesure que le nombre de sessions d'agents concurrents augmente, NVIDIA TensorRT LLM maintient son efficacité en séparant le traitement de l'entrée de la génération de la sortie, permettant ainsi d'optimiser chaque étape indépendamment. Ces résultats sont basés sur une méthodologie de benchmark construite de toutes pièces, conçue pour refléter le fonctionnement réel de l'IA autonome en production.
AgentPerf est construit à partir de trajectoires d'agents de codage réelles. L'agent reçoit une tâche, lit des fichiers, écrit et édite du code, exécute des commandes et itère en fonction des résultats, toutes les données provenant de dépôts de code publics réels dans plus de 12 langages de programmation. Les longues séquences, les modèles d'appels d'outils et la latence représentent des flux de travail de codage réels. AgentPerf mesure combien de ces tâches autonomes une plateforme peut prendre en charge simultanément tout en respectant des seuils de performance établis tels que la réactivité et le taux de tokens de sortie. Les appels d'outils ne sont pas réellement exécutés, mais simulés à l'aide de temps de traitement CPU représentatifs, de sorte que les différences de résultats reflètent uniquement l'impact des performances de calcul accéléré. Les résultats se traduisent directement en décisions d'infrastructure : le nombre de tâches autonomes concurrentes pouvant être exécutées par accélérateur et par mégawatt d'énergie.
Les principaux fournisseurs d'inférence, notamment Baseten, DeepInfra et Together AI, servent déjà des charges de travail autonomes sur des modèles de pointe (tels que DeepSeek V4 Pro) sur NVIDIA Blackwell. Together AI fournit une inférence en temps réel pour Cursor, une plateforme de codage autonome pilotée par l'IA, sur NVIDIA Blackwell. Les agents de Cursor déboguent des problèmes, génèrent des fonctionnalités et effectuent des refactorisations pendant que les développeurs continuent de travailler. DeepInfra alimente Pam.ai, une plateforme de main-d'œuvre IA destinée aux concessionnaires automobiles, qui déploie entièrement des agents sur NVIDIA Blackwell pour réserver des rendez-vous de service, traiter les appels téléphoniques et mener des campagnes de vente sortantes. Alors que NVIDIA et l'écosystème open source continuent d'optimiser les logiciels d'inférence, les performances et l'efficacité des charges de travail autonomes ne cesseront de s'améliorer. L'architecture NVIDIA Vera Rubin est désormais en production à grande échelle, apportant la prochaine génération de capacité d'infrastructure pour répondre à la demande croissante d'IA autonome à grande échelle. Plus de détails sur la méthodologie AgentPerf et les optimisations de la pile complète sont disponibles dans le blog technique correspondant.
Texte compilé par Wedoany. Toute citation par IA doit mentionner la source « Wedoany ». En cas de contrefaçon ou d'autre problème, veuillez nous en informer rapidement ; nous modifierons ou supprimerons le contenu le cas échéant. Courriel : news@wedoany.com









